Command Palette
Search for a command to run...
オリジナルアニメーターを解放せよ! Wav2Lip は AI リスニングを使用してキャラクターの口の形を同期します

"百聞は一見に如かず"AI技術の前では効果がなくなってきました 顔の変更や口パクの技術が次々と登場し、その効果はますます現実的になってきています。今日紹介したいのは Wav2Lip このモデルに必要なのは、元のビデオとターゲット オーディオの一部のみであり、これらを 1 つに組み合わせることができます。
『ズートピア』『アナと雪の女王』など、近年のハリウッドアニメは興行収入10億ドルを超える作品が相次いでいる。口の形だけを見ても、アニメキャラクターの口の形は現実の人間の口の形とほぼ同じです。
このような効果を達成するには、実際には非常に複雑なプロセスが必要であり、膨大な人的資源と物的資源を消費します。したがって、コストを節約するために、多くのアニメーション制作者は比較的単純な口のジェスチャーのみを使用します。
現在、AI はコンセプト アーティストの作業を容易にするために取り組んでいます。インドのハイデラバード大学と英国のバース大学のチームが今年のACM MM2020で論文を発表「野外でのスピーチトゥリップ生成に必要なのはリップシンクエキスパートだけです」、Wav2Lip と呼ばれる AI モデルが提案されています。これは、キャラクター ビデオとターゲット音声のみを必要とし、それらを 1 つに結合してシームレスに連携させることができます。
口パク技術Wav2Lip、効果抜群です
リップシンク技術に関しては、実はディープラーニングベースの技術が登場する以前から、キャラクターの唇の形状と実際の音声信号を一致させる技術はいくつかありました。
しかし、この Wav2Lip は、すべての方法の中で絶対的な利点を示します。他の既存の方法は、主に静止画像に基づいて、対象の音声に一致する口唇同期ビデオを出力します。しかし、口唇同期は、多くの場合、動的に話すキャラクターに対してうまく機能しません。
Wav2Lip は、動的なビデオを唇の形状に直接変換し、ターゲット音声に一致するビデオ結果を出力できます。
さらに、動画だけでなくアニメーション画像も口パクできるようになり、今後は絵文字パッケージがさらに充実します!

人間の評価が示すもの既存の方法と比較して、Wav2Lip によって生成されたビデオは、90% 以上の確率で既存の方法を上回ります。
モデルの実際の効果は何ですか?スーパーニューロはいくつかのテストを実施しました。以下のビデオは、公式デモの実行効果を示しています。入力教材は、公式が提供するテスト教材と、Super Neural が選択した中国語と英語のテスト教材です。
入力された元のビデオの登場人物は誰も話しませんでした。
AIモデルの操作により、キャラクターの口の形状と入力音声を同期させます。
公式デモアニメーションビデオでは、効果が完璧であることがわかります。スーパーニューラル実在人物テストでは、唇のわずかな変形と震えを除いて、全体的な唇同期効果は比較的正確です。
チュートリアルが公開されました。3 分で学習できます
これを見てあなたも挑戦してみませんか?すでに大胆なアイデアをお持ちなら、今すぐ始めてみませんか?
現在、このプロジェクトは GitHub 上のオープンソースであり、作成者はインタラクティブなデモンストレーション、Colab ノートブック、完全なトレーニング コード、推論コード、事前トレーニングされたモデル、チュートリアルを提供しています。
プロジェクト固有の情報は次のとおりです。
プロジェクト名:Wav2Lip
GitHub アドレス:
https://github.com/Rudrabha/Wav2Lip
プロジェクトの動作環境:
- 言語: Python 3.6+
- ビデオ処理プログラム: ffmpeg
顔検出の事前トレーニング モデルのダウンロード:
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
上記の環境を準備することに加えて、次のソフトウェア パッケージをダウンロードしてインストールする必要があります。
- リブロサ==0.7.0
- numpy==1.17.1
- opencv-contrib-python>=4.2.0.34
- opencv-python==4.1.0.25
- テンソルフロー==1.12.0
- トーチ==1.1.0
- トーチビジョン==0.3.0
- tqdm==4.45.0
- 数値==0.48
ただし、こうした面倒な手続きを準備する必要はありません。画像・キャラクター動画(CGIキャラクターも可)+音声(合成音声も可)を用意するだけで、国内の機械学習コンピューティングパワーコンテナサービスプラットフォーム上でワンクリックで直接実行できます。
ポータル:https://openbayes.com/console/openbayes/containers/EiBlCZyh7k7
現在、このプラットフォームは vGPU 時間を収集するためにも使用でき、毎週 vGPU 使用時間をプレゼントすることで誰でも簡単にチュートリアルを完了できます。
このモデルには、Wav2Lip、Wav2Lip+GAN、Expert Discriminator の 3 つの重みがあります。このうち、後の 2 つは、Wav2Lip モデルを単独で使用するよりも大幅に優れています。このチュートリアルで使用されるウェイトは Wav2Lip+GAN です。
モデルの作成者は次のように強調しています。オープンソース コードから得られるすべての結果は、研究/学術/個人的な目的にのみ使用する必要があります。このモデルは LRS2 (Lip Reading Sentences 2) データセットに基づいてトレーニングされているため、いかなる形式の商用利用も固く禁止されています。
研究者らは、この技術の悪用を避けるために、Wav2Lip のコードとモデルを使用して作成されたコンテンツには合成としてマークを付けることを強く推奨しています。
その背後にあるキーテクノロジー: リップシンクディスクリミネーター
Wav2Lip はどのようにしてオーディオのリップシンクを聞く際にこれほどの精度を実現しているのでしょうか?
レポートによると、ブレークスルーを達成するための鍵は次のとおりです。研究者らはリップシンク弁別器を使用しました。ジェネレーターが正確でリアルな唇の動きを一貫して生成するように強制します。
さらに、この研究では、弁別器で単一フレームの代わりに複数の連続フレームを使用し、時間的相関を説明するために(単なるコントラスト損失ではなく)視覚品質損失を使用することにより、視覚品質を改善しています。
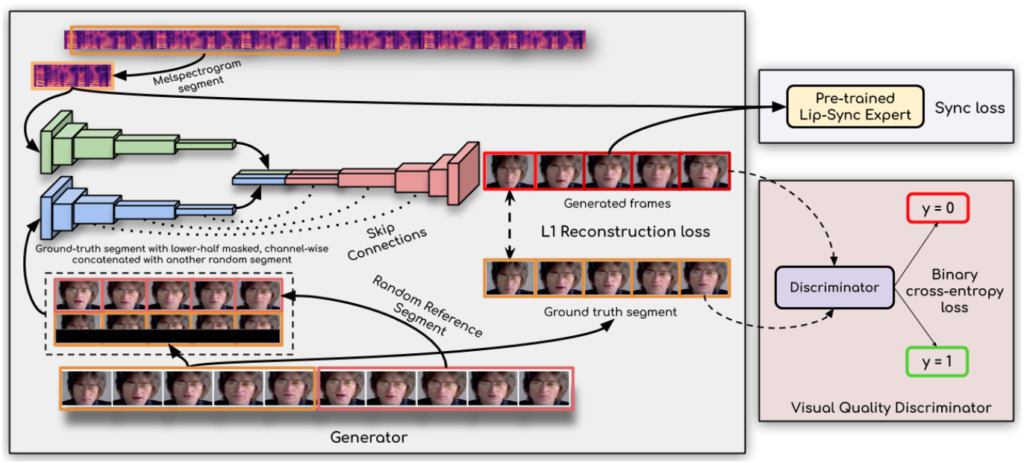
研究者らは次のように述べています。彼らの Wav2Lip モデルはほぼ普遍的で、あらゆる顔、あらゆる声、あらゆる言語に適しており、あらゆるビデオに対して高い精度を実現できます。元のビデオとシームレスにブレンドでき、アニメーションの顔を変換するために使用することもでき、合成音声のインポートも可能です。
このアーティファクトが心霊ビデオの新たな波を生み出す可能性も考えられます...
用紙のアドレス:
デモアドレス:
https://bhaasha.iiit.ac.in/lipsync/
- 以上 -








