Command Palette
Search for a command to run...
PyTorch と TensorFlow を超えて、この国内フレームワークには何かがあります

すでに非常に多くの深層学習フレームワークが存在するのに、なぜ OneFlow を構築する必要があるのでしょうか?機械学習の分野では、Yuan Jinhui は 90% の誰よりも長期的な視点を持っています。
ディープラーニングの分野では、PyTorch や TensorFlow などの主流フレームワークが間違いなく市場シェアの大部分を占めています。Baidu レベルの企業でさえ、PaddlePaddle を主流に押し上げるために多くの人的資源と物的資源を費やしてきました。
このようなリソースが独占的で略奪的な競争環境の中で、国産ディープラーニング フレームワークのスタートアップである OneFlow が台頭しました。
大規模モデルの処理を得意としており、今年はソースコード全体と実験比較データをGitHub上でオープンソース化した。
必然的に次のような疑問が生じます。大規模なモデルのトレーニングを解決するのに適した新しいアーキテクチャである OneFlow は必要ですか?深層学習フレームワークの効率はそれほど重要ですか?スタートアップが競合他社から抜きん出ることは可能でしょうか?
私たちは、オープンソース年次カンファレンス CosCon 20 の機会を利用して、First-Class Technology の CEO、Yuan Jinhui 氏にインタビューし、彼とエンジニアの間で 1,300 昼夜を超え、数十万行のコードの背後にある物語について学びました。一流のテクノロジー。
どんなに後光があっても、起業は段階的に進めなければなりません
2016 年 11 月、Yuan Jinhui は清華大学近くのオフィスビルで OneFlow の設計コンセプトの最初のバージョンを作成しました。この時、Yuan Jinhui 氏は 4 年近く勤務したマイクロソフト リサーチ アジア (MSRA) を退職したばかりでした。
Yuan Jinhui 氏が持つタグは「元 MSRA 職員」だけではありません。2003 年に西安電子科学技術大学を卒業した後、清華大学のコンピューターサイエンス学部に博士課程を続けるよう推薦されました。彼は、中国科学院の学者であり、中国の AI 分野の創設者の 1 人である張波教授に師事しました。
2008 年に清華大学を卒業した後、Yuan Jinhui は NetEase と 360 Search に入社しました。彼が開発したホークアイ システムは、中国代表チームによって日常のトレーニング支援システムとして使用されています。さらに、MSRA での勤務中は、大規模な機械学習プラットフォームに焦点を当てていました。また、当時世界最速のトピック モデル トレーニング アルゴリズムおよびシステムである LightLDA も開発しました。Microsoft のオンライン広告システムで使用されています。
LightLDA は 2014 年に開始されました。わずか 2 年後、目の肥えた袁金輝氏は別の大胆な推測を思いつきました。ビジネスニーズとシナリオの充実に伴い、大規模モデルのトレーニングを効率的に処理できる分散ディープラーニングフレームワークが、HadoopやSpark以降のデータインテリジェンスの時代のインフラの中核となることは必然です。
しかし、当時主流だったディープラーニングのフレームワークは、いずれもGoogle、Amazon、Facebookといった大手企業が開発したものであり、中国でも同様の状況でした。なぜなら、ディープラーニングフレームワークの開発には多額の研究開発コストが必要なだけでなく、さらに重要なことに、孤独に耐え、長期戦に備える能力が必要となるため、この分野で挑戦する新興企業は存在しないからです。 。
既存の深層学習フレームワークはすでに本格化していますが、新興企業が新しいフレームワークを開発した場合、ユーザーはそれに料金を支払うのでしょうか。行動主義者の袁金輝は、考えることだけでなく、実行することも敢えてします。
彼が OneFlow のコードの最初の行を入力したとき、完璧なビジネス ロジックはおろか、詳細な実装戦略についても考えていませんでした。彼のアイデアは単純であると同時に複雑でもあり、私たちは「開発者が使いたくなる」製品を作りたいと考えています。
天才たちのグループ + 21 か月、OneFlow の最初のバージョンがオンラインに
2017年1月、袁金輝氏は一流技術を設立し、30人以上のエンジニアを招集し、OneFlowの正式な「チーム戦」を開始した。誰もがその困難を十分に予想していましたが、開発が進むにつれて、チームの予想を超える困難が現れました。
ディープ ラーニング フレームワークのテクノロジーは非常に複雑で、OneFlow は参考になる前例のないまったく新しい技術アーキテクチャを採用しており、技術的なアイデアを検討するだけでも 2 年近くかかりました。

2018年秋、一流技術の開発は最も困難な段階に入った。製品開発の完成が遅れており、一部の従業員の忍耐と自信は疲弊しており、さらに同社の次の資金調達ラウンドは紆余曲折があり、チームの士気と自信は大きな課題に直面している。
起業家界には「18 か月の呪い」という格言があります。これは、1 年半にわたって希望もポジティブなフィードバックもなければ、起業家チームのメンタリティが変化し、忍耐力を失うことを意味します。袁晋輝はこれ以上待てないと悟った。OneFlow のイノベーションが実際に価値があることを誰もが認識できるように、OneFlow をできるだけ早く実際のシナリオで使用して、肯定的なフィードバックを形成する必要があります。
2018年9月、1年9か月の研究開発を経て、Yuan Jinhui と彼のチームは、OneFlow のクローズドソース バージョンを立ち上げました。当時、OneFlow はオープンソースではなかったので、大小さまざまな問題がありましたが、製品が正式にリリースされ、チームメンバーはようやく安心しました。
大規模なトレーニングに焦点を当て、効率性は同様のフレームワークを即座に上回ります
2018 年 11 月、一流のテクノロジーに幸運が訪れました。 Google は最強の自然言語モデルである BERT を発表し、NLP の新時代を切り開きました。これは袁晋輝の予測を裏付けました。大規模なトレーニングの処理に優れた新しいアーキテクチャが必要であり、必要です。
すぐ、一流の技術者がOneFlowをベースとしたBERT-Largeの分散トレーニングをサポートしています。これは当時分散型 BERT-Large トレーニングをサポートする唯一のフレームワークでもあり、そのパフォーマンスと処理速度は既存のオープンソース フレームワークをはるかに上回っていました。
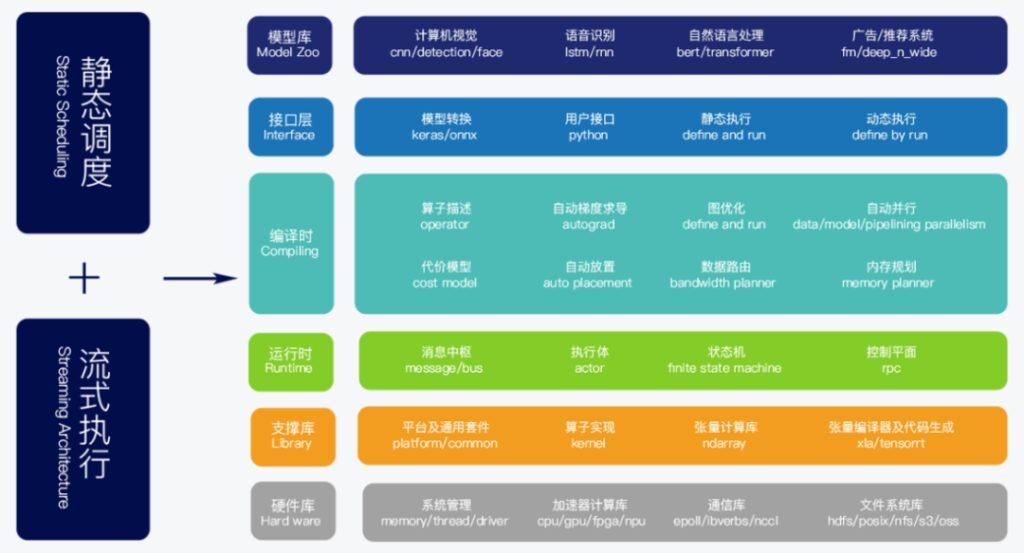
OneFlow は「一度の戦いで有名になる」ため、一流のテクノロジーが主要なインターネット企業ユーザーの最初のグループを蓄積する機会も提供されます。驚くべきことは、当時、袁金輝氏は「まだ製品に満足していない」ため、特に目立たない道を選択した。
2018 年 9 月のクローズドソース バージョンのリリースから、2020 年 7 月の正式なオープンソースまで、Yuan Jinhui はさらに 22 か月を費やして OneFlow を磨き上げました。彼と彼のチームは、当初予想されていなかった問題を解決しながら、古典的なモデルの最適化を続けました。Yuan Jinhui 氏の見解では、たとえ製品ドキュメントが十分に作成されていないとしても、OneFlow を簡単に押し出すつもりはありません。
2020 年 7 月 31 日、OneFlow は GitHub で正式にオープンソース化されました。大規模モデルのトレーニングで有名なこのオープンソース フレームワークは、効率が王様という 4 つの言葉を完璧に解釈して、2 度目の注目を集めています。
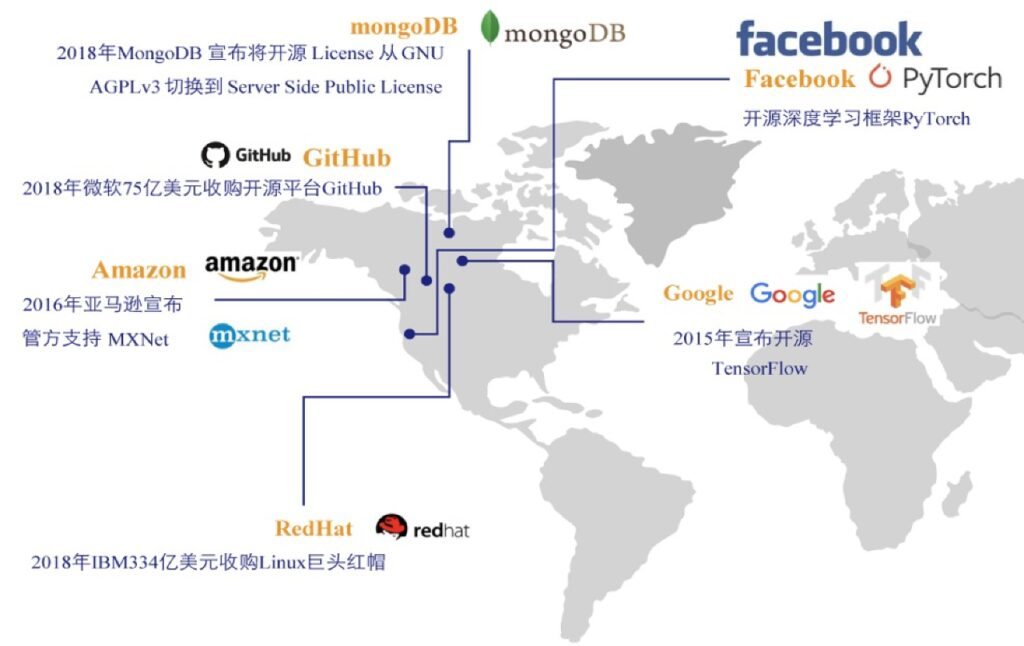
トレーニング速度が速く、GPU 使用率が高く、マルチマシンの加速率が高く、運用とメンテナンスのコストが低く、ユーザーが簡単に始めることができます。5 つの強力な利点により、OneFlow はさまざまなシナリオに迅速に適応し、迅速に拡張できます。 Yuan Jinhui と彼のチームは、OneFlow のパフォーマンスを極限まで追求し、最適化しました。
最近、OneFlow はバージョン v0.2.0 をリリースしました。最大 17 の更新されたパフォーマンス最適化、これにより、CNN と BERT の自動混合精度トレーニングの速度が大幅に向上します。
開発チームはまた、実験環境、実験データ、再現可能なアルゴリズムを完全にオープンソース化するために、DLPerf と呼ばれるオープンソース プロジェクトを設立しました。同じ物理環境 (V100 16G x8 マシン 4 台) で、ResNet50-v1.5 および BERT ベース モデル上の OneFlow および他のいくつかの主流フレームワークのスループットと加速率を評価しました。

結果は、OneFlow のスループット レートが、単一マシンと単一カード上、および複数マシンと複数カード上で他のフレームワークよりも大幅に優れており、主流のフラッグシップ グラフィックスで ResNet50-v1.5 および BERT ベースのモデルをトレーニングするための最速のフレームワークであることを証明しています。カード (V100 16G)。OneFlow ResNet50-v1.5 AMP シングル カードは、NVIDIA の高度に最適化された PyTorch よりも 80% 高速で、TensorFlow 2.3 よりも 35% 高速です。
具体的な評価レポートは次のリンクからご覧いただけます。
https://github.com/Oneflow-Inc/DLPerf
疑問に正面から向き合い、トラック上では「少数派」になりましょう
実際、OneFlow は当初から多くの人から疑問の声がありました。「バスに乗るのが遅くて居住スペースが狭い」という声が最も主流です。この点において、袁晋輝は並外れた冷静さを示した。

同氏によれば、ディープラーニングのフレームワークは新しいものであり、テクノロジーも業界も初期から中期にあるため、遅かれ早かれ始めることに問題はないという。テクノロジーが収束する前に、高性能、使いやすさ、ユーザー価値の高い製品はユーザーに支持されます。
居住空間が狭いという理論に関しては、さらに根拠がありません。オープンソースは、中小企業と大企業の製品に公平に競争する機会を与えます。優れた新しいフレームワークは、オープンソース精神の中核の 1 つである権威あるフレームワークに挑戦します。
疑いは OneFlow の開発を妨げるものではありません。Yuan Jinhui と彼のチームは、OneFlow のアップグレードと改善のプロセスを加速し、パフォーマンスを更新して最適化し、開発者ドキュメントを整理し、コミュニティからのフィードバックを収集しました。こうした努力と粘り強さにより、当初は「懐疑論者」だった人も多く、より多くのユーザーを OneFlow に引き寄せるようになりました。

COSCon'20 中国オープンソース年次会議で、Yuan Jinhui 氏は「深層学習トレーニング システムの進化」と題した講演を行いました。OneFlow の次の開発計画をすべての開発者に紹介し、効率性を重視し、パフォーマンスの最適化を継続します。開発チームは、ユーザーの学習コストと移行コストを削減するためにも懸命に取り組んでいます。現時点では、PyTorch ユーザーが OneFlow に移行するコストは非常に低くなっています。これは、2 つのユーザー インターフェイスがほぼ同じであり、トレーニング済みモデルを OneFlow に変換するコストも十分に低いためです。
客観的に見て、OneFlow は完成度と使いやすさの点で TensorFlow や PyTorch にまだ遅れをとっています。ただし、OneFlow は、高効率、優れたスケーラビリティ、分散型の使いやすさを特徴としています。これは、大規模な顔認識、大規模な広告推奨システム、GPT-3 のような巨大なモデル パラメーターを使用するモデル トレーニング シナリオに非常に適しています。
袁金輝氏はインタビューの最後に、OneFlowが機械学習エンジニアと深層学習エンジニアを募集していると述べ、意欲的なこの精力的なチームへの参加を大歓迎していると語った。勝つ。
- 以上 -








