Command Palette
Search for a command to run...
約 200,000 冊の書籍を含む OpenAI レベルのトレーニング データセットがオンラインにあります

OpenAI のような強力な GPT モデルをトレーニングしたいと考えていますが、トレーニング データ セットが不足していませんか?最近、reddit コミュニティのネチズンが、約 200,000 冊の書籍を含むプレーン テキスト データ セットをアップロードしました。最上級の GPT モデルのトレーニングはもはや夢ではありません。
最近、機械学習コミュニティで注目されているリソースの投稿 「GPT などの大規模な言語モデルをトレーニングするために使用される 196,640 冊のプレーン テキスト ブックのデータ セット」それは活発な議論を引き起こしました。
このデータセットは、2020 年 9 月までのすべての大規模テキスト コーパスのダウンロード リンクをカバーしています。さらに、bibliotik (オンライン書籍リソース ライブラリ) 内のすべての書籍のプレーン テキストと、トレーニングに使用される大量のコードも含まれています。
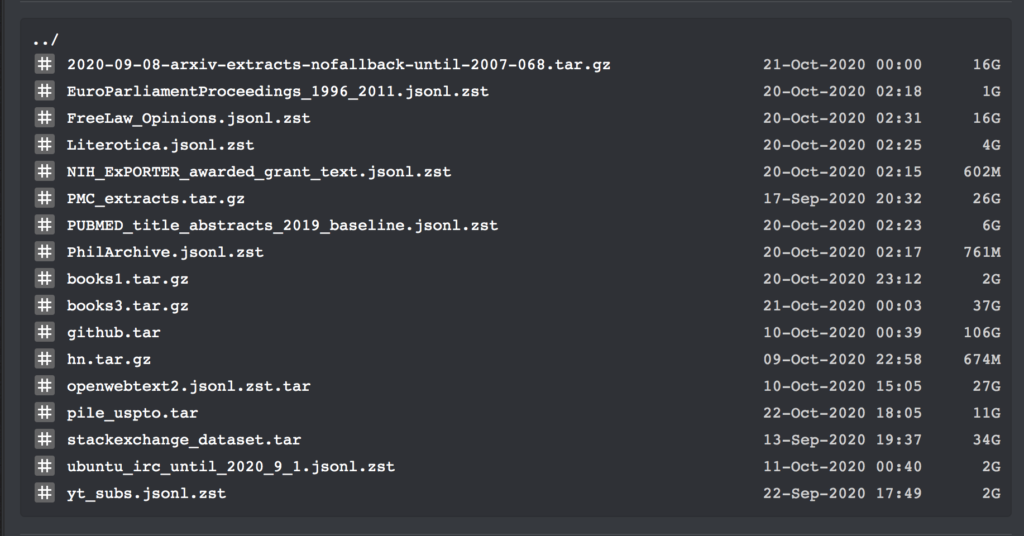
つい昨日、reddit の機械学習コミュニティで、ネチズンの Shawn Presser が一連の純粋なテキスト データ セットをリリースし、満場一致で賞賛されました。
これらのデータ セットには、合計 196,640 ボリュームのプレーン テキスト データが含まれており、GPT などの大規模な言語モデルをトレーニングするために使用できます。
このデータ セットには複数のデータ セットとトレーニング コードが含まれているため、ここでは詳細には触れません。books1 および Books3 データ セットの特定の情報のみをリストします。
書籍のプレーンテキスト データ セット
投稿者: ショーン・プレッサー
含まれる数量:ブック 1: 1800 冊; ブック 3: 196640 冊
データ形式:テキスト形式
データサイズ:ブック 1: 2.2 GB; ブック 3: 37 GB
更新時間:2020年10月
ダウンロードアドレス:https://orion.hyper.ai/datasets/13642
データセットオーガナイザーの Shawn Presser 氏によると、これらのデータセットの品質は非常に高く、books1 データセットの epub2txt スクリプトを修復するだけでも約 1 週間かかりました。
さらに、彼はこうも言いました。Books3 データセットは、OpenAI 論文にある謎の「books2」データセットに似ているようです。ただし、OpenAI はこの点について詳細な情報を提供していないため、両者の違いを理解することはできません。
ただし、彼の意見では、このデータセットは GPT-3 トレーニング データセットに非常に近いです。これを使用すると、次のステップで GPT-3 に匹敵する NLP 言語モデルをトレーニングすることもできます。もちろん、十分な GPU を準備する必要があることも条件となります。

報道によると、Books1 データ セット内の 1800 冊の書籍のテキスト データはすべて、大規模なテキスト コーパス BookCorpus から取得されています。これらには詩や小説などが含まれます。
たとえば、アメリカの作家クリスティ・リン・ヒギンズの『シェイズ・オブ・グレイ:闇に包まれた街ノワール』、ベンジャミン・ブロークの『アニマル・シアター』、T.I.ウェイドの『アメリカ・ワン』(『アメリカ・ワン』)など。
強力な GPT-3 の背後で、トレーニング データセットが貢献します
自然言語処理の分野に注目している人なら誰でも、OpenAI が今年 5 月に自然言語処理モデル GPT-3 の構築に多額の投資を行い、その驚くべきテキスト生成機能が業界で大きな注目を集めたことを知っています。人気になる。
GPT-3 は、質問に答えたり、翻訳したり、記事をより適切に作成できるだけでなく、いくつかの数学的計算機能も備えています。このような強力な機能を備えている理由は、その背後にある膨大なトレーニング データ セットと切り離すことができません。
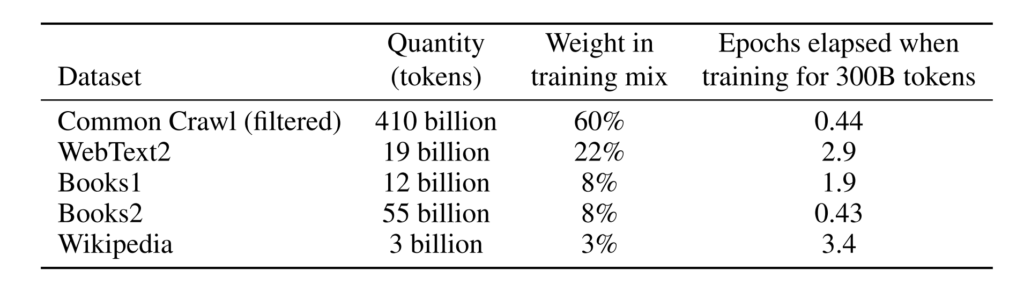
報道によると、GPT-3 で使用されるトレーニング データ セットは、CommonCrawl データ セット、インターネット テキスト、データ、Wikipedia、および 1 兆近くの単語を含むその他のデータに基づいており、使用される最大のデータ セットの前処理容量は 45 TB です。訓練費用も 1,200 万米ドルという驚異的な額に達しました。
GPT-3 は、より大きなトレーニング データ セットとより多くのモデル パラメーターにより、自然言語処理モデルの中で比類のないものになっています。
ただし、一般の開発者にとって、一流の言語モデルをトレーニングしたい場合は、トレーニング コストがかかることは言うまでもなく、トレーニング データ セットのステップだけで立ち往生することになります。
したがって、ショーン・プレッサーによってもたらされたデータセットは間違いなくこの問題を解決し、一部のネチズンはこの作業で莫大なコストを節約できたと述べています。
Super Neural は現在、books1 データ セットを次の場所に移動しています。 https://orion.hyper.ai、キーワード「本」または「テキスト」で検索するか、原文をクリックしてデータセットを入手してください。
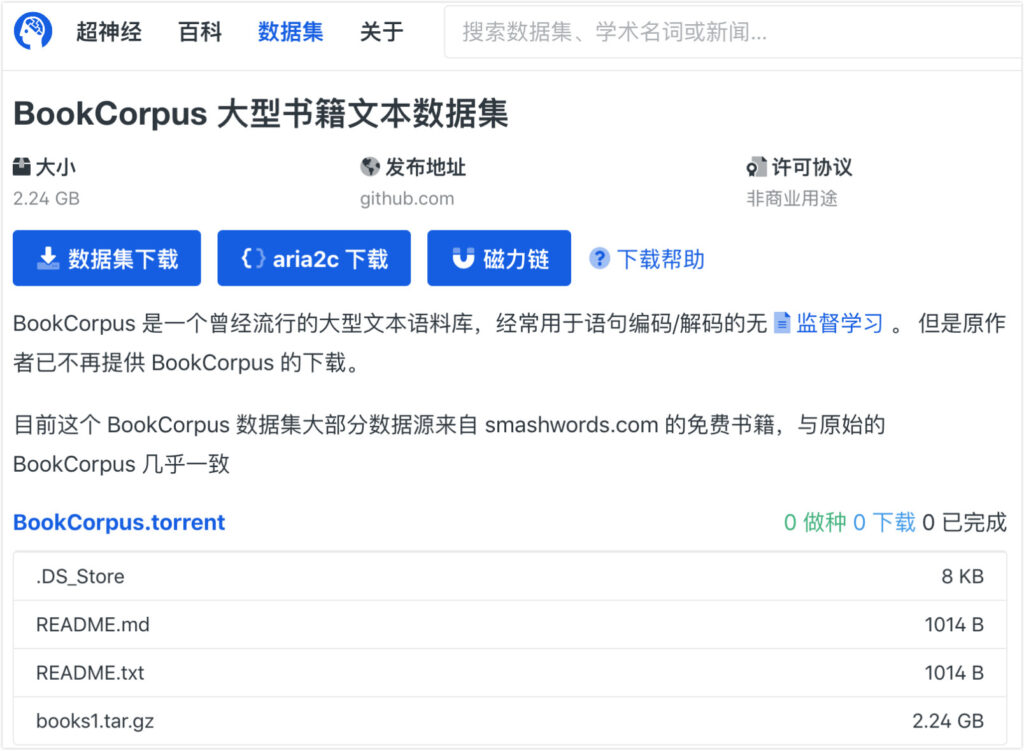
他のデータセットは次のリンクから入手できます。
Books3 データセットのダウンロード アドレス:
https://the-eye.eu/public/AI/pile_preliminary_components/books3.tar.gz
トレーニング コードのダウンロード アドレス:
https://the-eye.eu/public/AI/pile_preliminary_components/github.tar
redditの元の投稿:https://www.reddit.com/r/MachineLearning/comments/ji7y06/p_dataset_of_196640_books_in_plain_text_for/
- 以上 -








