Command Palette
Search for a command to run...
ますます注目を集める歩行者再識別のホットスポットとは?

歩行者再識別技術はスマートシティや自動運転などで広く活用されており、近年急速な発展を遂げています。これも学習データ規模の拡大やディープラーニングの発展によるものです。
広大な人の海の中で、あなたは一目で探している人を見つけることができますか?
今日、このタスクはコンピュータにとって簡単なものかもしれません。これは、近年の歩行者再識別技術の急速な発展によるものです。
人物再識別 (人物再識別、略して ReID とも呼ばれます) は、コンピューター ビジョン テクノロジを使用して、画像またはビデオ シーケンスに特定の歩行者が存在するかどうかを判断するテクノロジです。単純な観点から言えば、服装や姿勢、髪型などの特徴から、異なるシーンの同じ対象者を識別できるため、越境追跡技術とも呼ばれます。
歩行者の再識別は、顔認識に続くコンピュータ ビジョンの分野における重要な研究方向となっています。
顔認識技術は非常に成熟していますが、密集した群衆、監視カメラの低解像度、偏った撮影角度など、多くの状況では顔を効果的に認識できないことがよくあります。歩行者の再識別は重要な補足となっています。
したがって、顔再認識は近年ますます注目を集めており、その関連アプリケーションはますます普及しています。
テクノロジーを理解するには、まずそのテクノロジーがどのような問題を解決するのか、どのようにしてブレークスルーを達成するのか、開発のどの段階に到達しているのか、どのような課題が存在するのかを理解する必要があります。次に、総合的な分析を行っていきます。
歩行者の再識別はどこで使用されますか?
まず、前述したように、歩行者の再識別は顔認識技術を補完する重要な機能です。
顔認識の前提条件は、鮮明な正面写真です。ただし、背面のみなど顔が見えない角度の画像では顔認識ができません。現時点では、歩行者再識別は、姿勢、服装、その他の特徴を通じて対象人物を追跡し続けることができます。
現在、歩行者再識別技術はセキュリティや自動運転などの分野で広く活用されています。例えば:
インテリジェントなセキュリティ:警察の捜査官は ReID を使用して、不審者を迅速に選別することができます。
インテリジェントな人物検索システム:空港や駅など人の往来が多い場所では、ReID を使用して迷子や高齢者を見つけます。
スマートなビジネス:ReID は、歩行者の外観の写真に基づいてユーザーの軌跡をリアルタイムで動的に追跡し、モール内でのユーザーの興味を理解してユーザー エクスペリエンスを最適化できます。
自動運転システム:ReID により、歩行者の識別が向上し、自動運転の安全性が向上します。
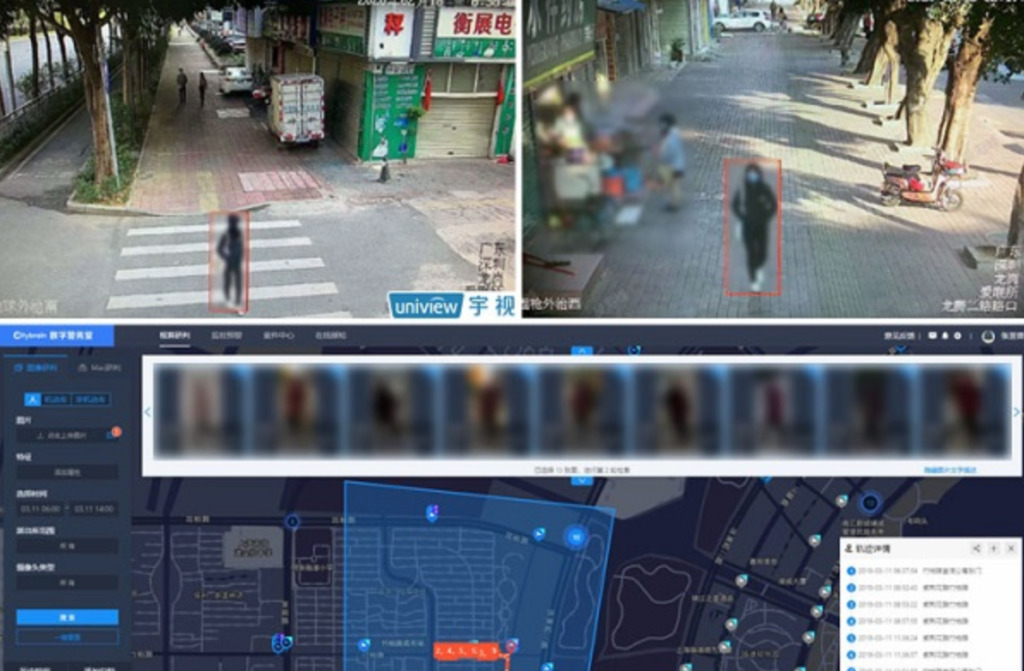
技術的ブレークスルーの鍵: 膨大なデータセット
関連研究者のまとめによると、歩行者再識別技術の実装には一般に次の 5 つのステップが必要です。
- データ収集。
- 境界ボックスの生成。
- トレーニングデータのアノテーション。
- モデルトレーニング。
- 歩行者捜索
その中で、データ収集は最初のステップであり、歩行者再識別研究全体の基礎となります。近年、歩行者の再識別における大きな進歩は、大規模なデータセットの推進とサポートと切り離すことができません。
この記事では、誰もがモデルを研究してトレーニングできるように、歩行者検出に一般的に使用されるデータ セットをいくつか紹介します。
INRIA 人物データセット 歩行者検出データセット
INRIA 人物データセットは、現在最も人気があり、最も使用されている静的歩行者検出データセットの 1 つです。INRIA (フランス国立情報オートメーション研究所) によって 2005 年に発行されました。このデータセットは、画像やビデオ内の直立歩行者を検出するために使用されます。
このデータセットには 2 種類の形式のデータが含まれています。
カテゴリ 1: 元の画像と対応する直立歩行者の注釈。
2 番目のカテゴリ: 64 × 128 ピクセルに正規化された直立歩行者のポジティブ クラス イメージと、対応する写真のネガティブ クラス イメージ。

このデータセットの基本情報は次のとおりです。
INRIA 人物データセット
発行機関: インリア
含まれる数量:トレーニング セットとテスト セットには合計 2573 個の画像があります。
データ形式:ポジティブ サンプルは .png 形式、ネガティブ サンプルは .jpg 形式です。
データサイズ:969MB
更新時間:2005年
ダウンロードアドレス:https://orion.hyper.ai/datasets/5331
関連論文:
UCSD 歩行者歩行者ビデオ データセット
UCSD の歩行者ビデオ データは、カリフォルニア大学と香港城市大学によって収集および編集され、2013 年 2 月に公開されました。
このデータセットは、モーション セグメンテーションと群衆カウントに使用されます。データセットには、UCSD (カリフォルニア大学サンディエゴ校) の歩道上の歩行者のビデオが含まれており、すべて固定カメラで撮影されました。
このうち、すべてのビデオは 8 ビット グレースケール、サイズ 238×158、10 フレーム/秒です。オリジナルビデオは 740×480、30 フレーム/秒で、ご要望に応じて提供可能です。
ビデオ ディレクトリには 2 つのシーンのビデオが含まれています (vidf と vidd の 2 つのディレクトリに分かれています)。各シーンは独自の vidX ディレクトリにあり、.png クリップのセットに分割されます。

このデータセットの基本情報は次のとおりです。
UCSD 歩行者データセット
発行機関: UCSD、香港城市大学
含まれる数量:約10時間のビデオ
データ形式:.png
データサイズ:ビデオ: 787MB; ビデオ: 672MB
更新時間:2013 年 2 月
ダウンロードアドレス:https://orion.hyper.ai/datasets/9370
関連論文:
カリフォルニア工科大学の歩行者検知ベンチマーク
Caltech Pedestrian Detection Benchmark データベースは、2009 年に Caltech によってリリースされ、毎年更新され続けています。
このデータベースは現在最大の歩行者データベースであり、約 10 時間のビデオが含まれています。主に都市部の通常の交通環境を走行する車両の車載カメラで撮影されたもので、解像度は640×480、30フレーム/秒です。
合計約 250,000 フレーム (約 137 分)、350,000 個の長方形フレーム、2,300 人の歩行者がビデオに注釈付けされます。さらに、長方形フレームとそのオクルージョン間の時間対応も注釈付けされます。

このデータセットの基本情報は次のとおりです。
カリフォルニア工科大学歩行者データセット
発行機関: カリフォルニア工科大学
含まれる数量:トレーニング セットとテスト セットには合計 2573 個の画像があります。
データ形式:.jpg
データサイズ:11.12GB
更新時間:2019年7月
ダウンロードアドレス:https://orion.hyper.ai/datasets/5334
関連論文:
先進的な手法とは何でしょうか?
歩行者再識別分野の研究は30年近く行われており、近年、大規模なデータセットの開発とディープラーニングの開発により、この技術は大きく進歩しました。
ここでは、学習と参考のために、最近提案された 2 つの方法の例を示します。
異なるカメラ間のスタイルの違いを排除する
トップ国際コンピュータビジョンカンファレンスCVPR 2020で、中国科学院が発表した論文 「本人再識別のための Unity スタイル転送」真ん中、異なるカメラ間のスタイルの違いを統一できる適応型UnityStyle手法を提案する。

同じカメラであっても、異なるカメラであっても、写真を撮影する場合、時間、照明、天候などの影響を受け、大きな違いが生じるため、ターゲットクエリが困難になります。
この問題を解決するために、研究チームはまず UnityGAN を作成し、カメラ間のスタイルの変化を学習し、カメラごとに形状が安定したスタイルユニティ イメージを生成し、それを UnityStyle イメージと呼びました。
同時に、UnityStyle 画像を使用して、異なる画像間のスタイルの違いを排除します。、クエリ (クエリ ターゲット) とギャラリー (画像ライブラリ) の間の一致が向上します。
次に、彼らは、提案された方法を再識別モデルに適用し、クエリ用によりスタイルに堅牢な深い特徴を取得できることを期待しました。

チームは、提案されたフレームワークのパフォーマンスを評価するために、広く使用されているベンチマーク データセットに対して広範な実験を実施し、実験結果により、提案されたモデルの優位性が確認されました。
歩行者の遮蔽の問題を解決する
Megvii Research Institute が CVPR 2020 で発表した論文 「高次情報は重要:遮蔽された人物の再識別のための学習関係とトポロジー」真ん中、この分野で最も一般的かつ困難な問題である歩行者の遮蔽を解決します。

この論文では、Megvii Research Institute が提案するフレームワークには次のものが含まれます。
- 一次意味モジュール (S)。人体のキーポイント領域の意味特徴を取得できます。
- 異なる意味論的局所特徴間の関係情報をモデル化できる高次関係モジュール (R)。
- 堅牢な位置合わせ機能を学習し、2 つの画像間の類似性を予測できる高次のヒューマン トポロジ モジュール (T)。
これら 3 つのモジュールは、エンドツーエンドの方法で共同でトレーニングされます。

以前は、「史上最も人気のある ECCV がオープンしました。これらの論文はとても興味深いです。」華中科技大学、中山大学、Tencent Youtu Laboratory が発表した論文「Please Don't Disturb Me: Pedestrian Re-identification under the Interference of Other Pedestrians」で紹介されています。この論文で提案されている手法は、次のような問題を解決します。混雑したシーンにおける背景と背景の問題 歩行者の干渉や人体の遮蔽によって引き起こされる誤った検索結果の問題。興味のある学生はもう一度復習してください。
注目の技術だが、まだ難しい点もある
現在、歩行者の再識別は、データ、効率、パフォーマンス、その他の側面を含め、依然として多くの課題に直面しています。
データ的には、屋内と屋外などのシーン別、季節ごとのスタイルの変化、昼と夜などの時間ごとの光の違いなど、得られる映像データはすべて必要となります。歩行者の干渉要因の再識別。これらの干渉要因は、モデルの認識精度に影響を与えるだけでなく、認識効率にも影響を与えます。

したがって、既存の事例では、歩行者の再識別が人間の識別能力を超えていることも確認されていますが、依然として解決すべき問題が多くあります。
次のリンクに移動します。https://orion.hyper.ai/datasets、「歩行者」を検索するか、元の記事を読んで、より多くの歩行者検出データセットが利用可能です。
- 以上 -








