Command Palette
Search for a command to run...
B局の神曲ダメダネ:本質は顔が変わる、5分で覚えられる

AIによる顔を変える技術は次々と登場していますが、世代が進むごとにどんどん良くなっていきます。最近、NeurIPs 2019 で公開された AI 顔変更一次運動モデルが人気となっており、その表情伝達効果は同じ分野の他の手法よりも優れています。最近、このテクノロジーは Bilibili に新たなトレンドを引き起こしています...
最近、ビリビリでは「生草」(ビリビリの俗語で「魔法で面白い」という意味)すぎる動画が続々と登場しており、再生回数はゆうに100万回を超えており、かなりの人気となっています。
完璧なスキルを持つマスターを育成し、使用してください 「一次運動一次運動モデル」AI 顔変更プロジェクトは、ユニークなスタイルのさまざまなビデオを生成しました。
たとえば、Jacky Cheung、Du Fu、Tang Monk、パンダ頭の絵文字パックは、「ダメダン」と「解きほぐす」を感情豊かに歌うことができました...写真は次のようになります。


アニメーションを見るだけでは十分でない場合は、ビデオに直接アクセスしましょう。
洗脳ソング「ダメダン」の泣き猫バージョン、これまでの再生回数は211万3000回、出典:Station B Upの毛深いフー・チュチュ
ちょっと派手だと言わざるを得ません…Xiaopo のウェブサイトにアクセスして、さらに見たい作品を検索してください。
これらのビデオは、試してみたいという無数のネチズンを魅了し、チュートリアルを求めるメッセージを残しています。次に、これらの顔を変える効果 (諸悪の根源) を実現するテクノロジーを見てみましょう。一次運動モデル。
Learning Garden Station B、口パクを教えるための複数のチュートリアル
これまでに同様の顔変更技術や口パク技術が次々と登場し、提案されるたびに顔変更ブームが巻き起こります。
一次運動モデルは、顔の特徴や口の形状の最適化に効果的であり、使いやすく、実装効率が高いため、非常に人気があります。
例えば記事冒頭の「ダメダネ」の顔を変更したい場合、導入には数十秒しかかからず、5 分で習得できます。
サイト B のほとんどの所有者は、チュートリアルを行うために Google ドライブと Colab を選択します。ファイアウォールを突破するための閾値を考慮して、アップマスターのいずれかからチュートリアルを選択し、国内の機械学習コンピューティングパワーコンテナサービス(https://openbayes.com) に加えて、自由時間を取得し、毎週無料の vGPU 使用時間を取得できるようになったので、このチュートリアルを簡単に完了できます。
2020-09-30 更新: 現在、bilibili は「AI Face Changing」に関連するすべてのビデオを削除したため、OpenBayes チームはステップバイステップのチュートリアルの対応するテキスト バージョンを追加しました。
5分以内に自分だけのダメダンを完成させましょう
この解説ビデオでは、初心者でも簡単にこの顔を変えるトリックを習得できるように、ステップごとに説明しています。 up の所有者もノートブックをプラットフォームにアップロードし、ワンクリック クローンで直接使用できます。
しかし、Technology Up の所有者の多くは、エンターテイメントに加えて、技術交流のためにビデオを作成しているため、悪意を持って悪用しないことを望んでいると述べています。
上記のビデオチュートリアルのアドレス:
https://openbayes.com/console/openbayes/containers/BwZQj5wr3Jp
元のプロジェクトの Github アドレス:
https://github.com/AliaksandrSiarohin/first-order-model
もう 1 つの顔を変えるツールですが、どこで使用できますか?
一次運動モデルは、トップカンファレンス NeurlPS 2019 の論文から引用されました。「画像アニメーションの一次運動モデル」(「画像アニメーションの一次運動モデル」)、著者はイタリアのトレント大学とスナップ社の出身。

タイトルからもわかるように、この論文の目標は、静止画像をアニメーション化することです。ソース画像とドライバー ビデオが与えられた場合、ソース画像内の画像をドライバー ビデオ内のアクションに合わせて動かします。つまり、あらゆるものは動くことができるのです。
効果は次の図に示すとおりです。左上隅はドライバー ビデオ、残りはソースの静止画像です。

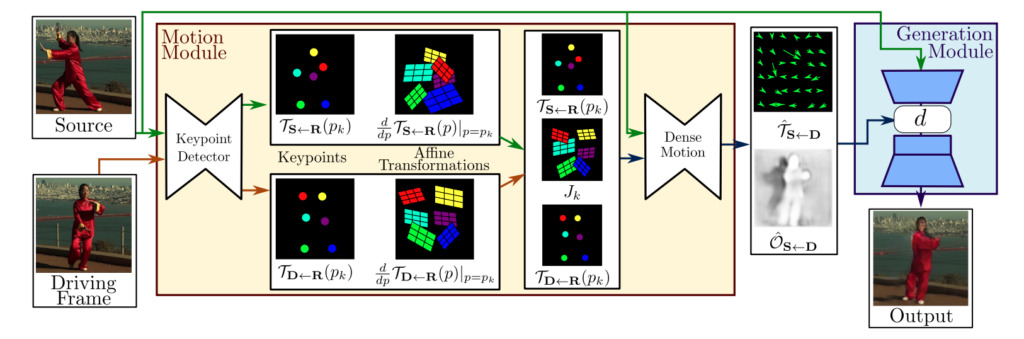
モデルフレームワークの構成
一般に、この 1 次運動モデルのフレームワークは主に 2 つのモジュールで構成されます。動き推定モジュールと画像生成モジュール。
動き推定モジュール:自己教師あり学習により対象物の見た目と動きの情報を分離し、特徴表現を行います。
画像生成モジュール:このモデルは、ターゲットの動き中に発生するオクルージョンをモデル化し、ビデオ合成のために、指定された有名人の画像から外観情報を抽出し、以前に取得した特徴表現と組み合わせます。
従来のモデルと比べてどのように優れているのでしょうか?
これまでのAI顔変更手法とどう違うの?と疑問を持たれる方もいるかもしれません。著者が解説を行っています。
以前の顔を変更するビデオ操作では、次の操作が必要でした。
- 通常、顔交換に関与する双方の顔画像データについて事前トレーニングを実施する必要があります。
- ソース画像の重要なポイントに注釈を付けて、対応するモデルのトレーニングを実行する必要があります。
しかし実際には、個人の顔データは少なく、トレーニングにあまり時間がかかりません。したがって、特定の画像で使用する場合には従来のモデルの方が優れていることが多いですが、一般向けに使用する場合は品質を保証することが難しく、ひっくり返りやすい傾向があります。

したがって、本論文で提案する手法はデータ依存の問題を解決し、生成効率を大幅に向上させることができる。表現と動きの移行を実現したいなら、のみ同じカテゴリの画像データセットに対してのみトレーニングする必要があります。
たとえば、表情の移行を実現したい場合は、誰の顔を変更するかに関係なく、顔データ セットでトレーニングするだけで済みます。太極拳の動作の移行を実現したい場合は、太極拳のビデオ データ セットを使用できます。トレーニング。
トレーニングが完了したら、対応する事前トレーニング済みモデルを使用して、ソース画像を運転ビデオに合わせて動かす結果を得ることができます。

著者は、この方向で最も先進的な手法である X2Face および Monkey-Net と自分の手法を比較しました。その結果、同じデータセットにおいて、この手法のすべての指標が改善されました。2 つの顔データセット (VoxCeleb と Nemo) に関しても、この方法は、もともと顔生成のために提案された X2Face よりも大幅に優れています。

- 以上 -








