Command Palette
Search for a command to run...
史上最も人気のある ECCV がオープンしました、これらの論文はとても興味深いです

コンピュータビジョン分野の3大国際会議の1つであるECCV 2020が、8月23日から27日までオンラインで開催された。今年、ECCV は合計 1,361 件の論文を受け入れ、その中から最も人気のある 15 件の論文を選択して読者に共有しました。
感染症の影響を受け、今年の ECCV 2020 は他のトップカンファレンスと同様、オフラインからオンラインに変更され、8 月 23 日に開幕しました。

ECCV、正式名称はEuropean Conference on Computer Vision(ヨーロッパ国際コンピュータビジョン会議)、これは、コンピュータ ビジョンに関する 3 つのトップ国際会議の 1 つ (他の 2 つのトップ会議は CVPR と ICCV) で、2 年ごとに開催されます。
今年の感染症の流行により多くの人々の計画が中断されましたが、科学研究と論文投稿に対するみんなの熱意は衰えることがありません。統計によると、ECCV 2020 では、合計 5,025 件の有効な提出があり、前回のセッション (2018 年) の提出数の 2 倍以上であり、「史上最も人気のある ECCV」とみなされています。
最終的に 1,361 件の論文が受理され出版され、受理率は 27% でした。採択された論文のうち、口頭論文は 104 件で有効投稿総数の 2% を占め、スポットライト論文は 161 件で約 3% を占めました。残りの紙はポスターです。
姿勢推定、3D点群、優秀論文リスト
コンピュータビジョン分野におけるこの一大イベントは、今年どのような素晴らしい研究成果をもたらしてくれたのでしょうか?
選出された論文の中から、3D ターゲット検出、姿勢推定、画像分類、顔認識など多方向をカバーする 15 件の論文を選出しました。
歩行者の再識別「邪魔しないでください: 他の歩行者の妨害下での歩行者の再識別」

ユニット:華中科技大学、中山大学、テンセントYoutu研究所
まとめ:
従来の人物の再識別では、切り取られた画像に 1 人の人物のみが含まれていることを前提としています。ただし、混雑したシーンでは、既製の検出器が複数の人物、背景の歩行者の大部分、または人体のオクルージョンを含む境界ボックスを生成する場合があります。
これらの画像から抽出された歩行者干渉のある特徴には干渉情報が含まれている可能性があり、誤った検索結果を招く可能性があります。
この問題を解決するために、本論文では新しいディープネットワーク (PISNet) を提案します。 PISNet はまず、Query 画像誘導アテンション モジュールを使用して、画像内のオブジェクトの特徴を強化します。
さらに、注意モジュールによる他の歩行者の干渉を抑制するための逆注意モジュールと多人分離損失機能を提案する。私たちの手法は 2 つの新しい歩行者干渉データセットで評価され、その結果は、この手法が既存の Re-ID 手法よりも優れていることを示しています。

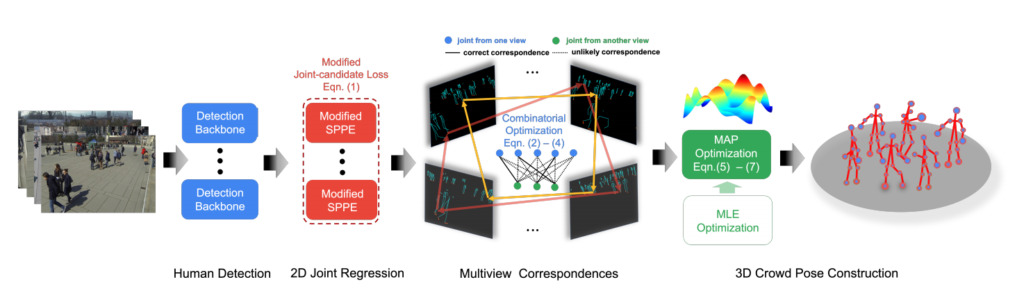
姿勢推定 「混雑シーンにおける多視点幾何学に基づく複数人の三次元姿勢推定」

ユニット:ジョンズ・ホプキンス大学、シンガポール国立大学
まとめ:
外側極制約は、現在のマルチマシン 3 次元人間姿勢推定方法における特徴マッチングと奥行き推定の中核問題です。この定式化は、まばらな群衆のシーンでは満足のいくパフォーマンスを発揮しますが、密集した群衆のシーンでは、主に 2 つのソースのあいまいさにより、その有効性が疑問視されることがよくあります。
1 つ目は、関節とエピポーラ線の間のユークリッド距離によって提供される単純な手がかりによる人間の関節の不一致です。 2 番目の問題は、単純に問題を最小二乗に最小化するため、ロバスト性が欠如していることです。
この記事では、私たちは複数人の 3D 姿勢推定式から脱却し、それを群衆姿勢推定として再定義します。私たちの方法は、2 つの重要なコンポーネントで構成されています。1 つは高速クロスビュー マッチングのためのグラフィカル モデル、もう 1 つは 3D 人間の姿勢再構成のための最大事後推定 (MAP) 推定器です。 4 つのベンチマーク データセットでこの手法の有効性と優位性を実証します。
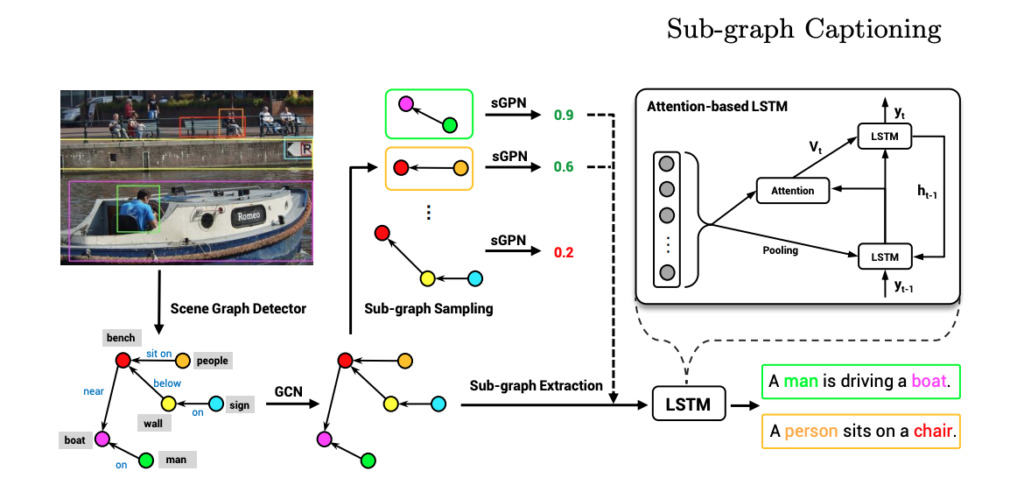
画像の記述「シーングラフ分解に基づく自然言語記述生成」

ユニット:Tencent AI Lab、ウィスコンシン大学マディソン校
まとめ:
本稿ではシーングラフ分解に基づく自然言語記述生成手法を提案する。
自然言語を使用して画像を記述することは困難な課題である。本論文では、画像シーングラフ表現を再検討することにより、シーングラフ分解に基づく画像の自然言語記述生成方法を提案する。この方法の核心は、画像に対応するシーン グラフを複数のサブ画像に分解することであり、各サブ画像はコンテンツの一部または画像の一部の記述に対応します。この方法では、ニューラル ネットワークを通じて重要なサブグラフを選択し、画像を説明する完全な文を生成することで、正確で多様かつ制御可能な自然言語記述を生成できます。研究者らは広範な実験も実施し、実験結果はこの新しいモデルの利点を実証しました。
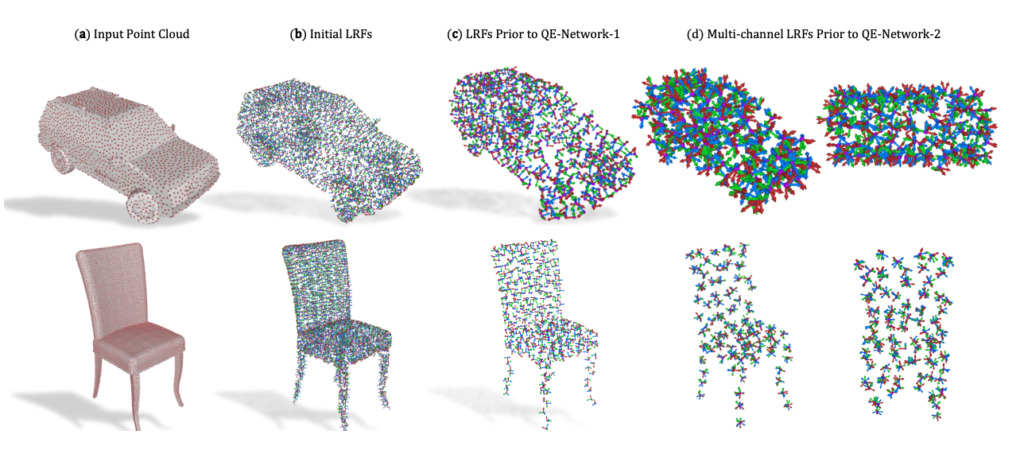
3D点群「3D点群用クォータニオン等変カプセルネットワーク」

ユニット:スタンフォード大学、ドルトムント工科大学、パドヴァ大学
まとめ:
我々は、順序付けされていない入力セットの回転、平行移動、および順列の SO(3) セットと同等の点群を処理するための 3D カプセル アーキテクチャを提案します。
ネットワークは、入力点群から計算されたローカル参照フレームの疎なセット上で動作します。ネットワークは、等分散ダイナミック ルーティング プロセスを含む、新しい 3 次元クォータニオン グループ カプセル層を通じてエンドツーエンドの分散を確立します。
カプセル レイヤーを使用すると、ジオメトリをポーズから解きほぐすことができ、より有益で構造化された潜在空間への道が開かれます。その際、理論的には、カプセル間の動的ルーティング プロセスを、証明可能な収束特性を持つ反復再重み付け最小二乗 (IRLS) 問題を解くために使用されるよく知られた Weiszfeld アルゴリズムに関連付けます。これにより、カプセル層間のロバストな姿勢推定が達成されます。
スパース等変クォータニオン カプセルのおかげで、私たちのアーキテクチャではオブジェクトの共同分類と方向推定が可能になり、一般的なベンチマーク データセットで経験的に検証できます。
顔認識「説明可能な顔認識」

ユニット:システムおよびテクノロジー研究、Visym Labs
まとめ:
Explainable Face Recognition (略して XFR) は、顔マッチャーによって返された照合結果を解釈する問題です。検出器があるアイデンティティに一致し、別のアイデンティティに一致しない理由について洞察を得ることができます。この原則を理解すると、人々が顔認識を信頼し、解釈するのに役立ちます。
このペーパーでは、XFR の最初の包括的なベンチマークとベースライン評価を提供します。我々は、「修復ゲーム」と呼ばれる新しい評価スキームを定義しました。これは、95 人の被験者から構成される 3,648 個の三つ組 (プローブ、メイト、非メイト) の選択されたセットであり、特定の顔の特徴 (鼻、眉毛、口など) が合成的に修復されます。パッチ適用された非合致を作成します。
XFR アルゴリズムのタスクは、トリプレットごとに修復された不一致領域ではなく、プローブ画像内のどの領域がペア画像と最もよく一致するかを示すネットワーク アテンション マップを生成することです。これは、どの画像領域が顔の照合に寄与するかを定量化するための基礎を提供します。
最後に、このデータセットに関する包括的なベンチマークを提供し、3 つの顔照合機能で 5 つの最先端のアルゴリズムを比較します。このベンチマークには、サブツリー EBP と入力サンプルの密度ベースの解釈 (DSE) と呼ばれる 2 つの新しいアルゴリズムが含まれており、既存の最先端技術よりもはるかに優れたパフォーマンスを発揮します。
また、新しい画像に対するこれらのネットワーク アテンション技術の定性的な視覚化を示し、これらの解釈可能な顔認識モデルが顔照合器の透明性と信頼性をどのように向上させることができるかを探ります。

年齢推定「寿命年齢換算合成」

ユニット:ワシントン大学、スタンフォード大学、Adobe Research
まとめ:
私たちは、1 枚の写真の年齢の進行と退行の問題を解決します。つまり、人物が将来または過去にどのように見えるかを予測します。
既存の老化方法はほとんどが質感の変化に限定されており、人間の老化と成長に伴う頭の形状の変化は無視されています。このため、以前の方法の適用範囲は高齢者に限定され、子供の写真に適用しても高品質の結果は得られません。
我々は、学習された潜在空間が連続的な双方向老化プロセスをシミュレートする新しいマルチドメイン画像対画像生成敵対的ネットワーク構造を提案します。ネットワークは FFHQ データセットでトレーニングされ、年齢、性別、セマンティック セグメンテーションに基づいてラベル付けされます。固定年齢クラスをアンカーとして使用して、連続的な年齢変換を近似します。私たちのフレームワークは、たった 1 枚の写真に基づいて 0 歳から 70 歳までの完全なアバターを予測し、頭のテクスチャと形状を変更します。私たちはさまざまな写真やデータセットで結果を実証し、最先端技術に比べて大幅な改善が見られることを示しています。

ポータル: 書類、コード、すべてワンクリックで利用可能
上記は ECCV 2020 に選ばれた数千の論文の中の氷山の一角にすぎませんが、1,361 もの膨大な論文を前にして、興味のある論文、および原文リンク、コードを見つけるのは簡単ではありません。 、など。
しかし、ある人が呼んだのは、 論文ダイジェストチーム チームは、読者が論文やコードを見つけることがもはや問題ではないように道を切り開きました。
チームは最近、「ECCV 2020 論文ハイライトの一文レビュー」の概要を発表しました。各論文は一文に簡潔かつ包括的にまとめられており、論文アドレスが付けられています。読者が最も読みたい論文をすぐに見つけられるようにします。

住所を教えていただきありがとうございます:
さらに、コードを公開した 170 件の論文も慎重に整理されており、読者は対応するリンクをクリックしてコードを表示できます。
さらに、crossminds.ai は口頭論文のプレゼンテーションも編集しており、読者はそのデモ デモンストレーションを通じて論文内のテクノロジーをより明確かつ直感的に理解できます。これは非常に興味深いものです。
https://crossminds.ai/category/eccv%202020/
- 以上 -








