Command Palette
Search for a command to run...
情報検索、経路計画、電子商取引、KDDの主戦場は何ですか?

データマイニング分野のトップ国際カンファレンスであるKDD 2020が来週開幕する。今年は 2,035 件の論文が提出され、合計 338 件の論文が採択されました。中でも国内テクノロジー大手のBAT、滴滴出行、ファーウェイなどが好調だった。
データマイニングと知識発見に関する年次国際会議 ACM SIGKDD 2020 (知識発見とデータマイニングに関する会議、以下 KDD)、8月23日から27日までオンラインで開催。

データベース技術の発展とデータの継続的な蓄積に伴い、データマイニングの分野もますます注目を集めています。
近年の KDD への投稿数も、2016 年の 1,115 件から今年は 2,035 件へと、目に見えるペースで増加しています。これらの論文では中国人の貢献も増えており、その成果は非常に印象的です。
KDD26年目に入り、中国人の科学研究力は年々高まっています。
KDD は 1995 年に始まり、ACM のデータ マイニングと知識発見に関する特別委員会 (SIGKDD) によって主催されています。CCF(中国コンピュータ連盟)よりクラスA国際会議として推薦され、データマイニングの分野では「ワールドカップ」として知られています。
データマイニング分野における世界最高レベルの国際会議として、KDDの論文採択率は毎年20%を超えないほど厳しいことで知られており、今年も例外ではありません。
5月25日、KDD 2020は採択された論文を正式に発表しました。今年は、合計 1,279 件の論文がリサーチ トラック (研究コミュニティ向けの学術論文) に投稿され、合計 216 件の論文が採択されたため、採択率は 16.8% です。
Applied Data Science トラック (応用データ サイエンスの方向性、産業向けの実践的なトラック) には 756 件の論文が投稿されています。121 件の論文が受理され、受理率は 16% でした。
KDDは今年で26回目を迎え、論文数や受賞歴などの統計データによると、近年KDDへの中国人の参加は年々増加しており、その実績はますます高まっている。数多くの論文が選ばれ、数え切れないほどの賞が受賞しました。
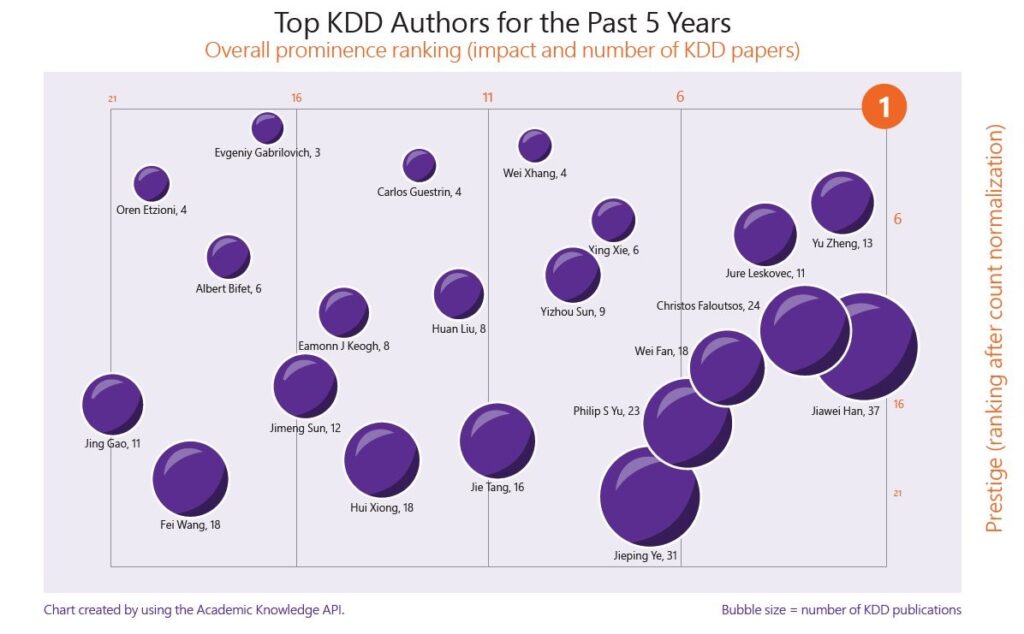
国内テクノロジー企業は近年、KDDにおいてますます目覚ましい成果を上げている。
統計によると、2018年にBAT大手3社が合計12本の論文を発表した。今年はアリババだけで25本の論文、テンセントが10本の記事、百度がそれに加えて滴滴出行、ファーウェイ、JD.comがそれぞれ9本の記事を発表した。 6件の記事を公開しました。
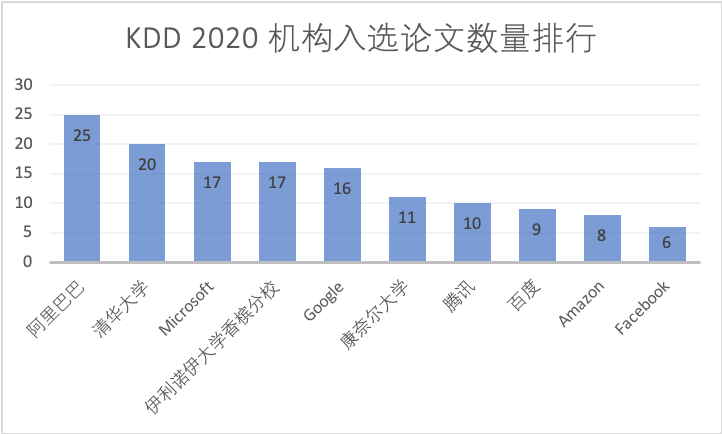
KDD 2020:大手メーカーの戦場はどこ?
国内大手メーカーの論文を、誰もが学び、参考にできるよう、応用シーンに応じて分類・整理しました。これらの論文の一部は arXiv に公開されており、こっそり見ることができます。
情報検索「タオバオが推奨する特権機能の抽出」

単位: アリババ
まとめ:特徴は、電子商取引の予測タスクにおいて重要な役割を果たします。オフライン トレーニングとオンライン サービスの一貫性を確保するために、通常は両方の同じ特性を利用します。ただし、この一貫性はいくつかの特徴を無視しています。たとえば、アイテムの詳細ページに費やした時間などの特性は、コンバージョン率 (CVR)、つまりユーザーがアイテムをクリックした後にそのアイテムを購入する可能性を見積もる際の情報を提供します。ただし、CVR 予測はクリックが発生する前にオンラインでランク付けされる必要があります。特徴的だがトレーニングでのみ使用できる機能を特権機能として定義します。この論文では、トレーニングと推論の間のギャップを埋める蒸留技術に基づいて、特徴蒸留 (PFD) アルゴリズムを提案します。私たちは、淘宝網のレコメンデーションに関する 2 つの基本的な予測タスク、つまり、粗いランキングのクリックスルー率と、細かいランキングの CVR について実験を実施しました。 CTR サービス中に禁止されているインタラクティブ機能と CVR のポストイベント機能を抽出することで、堅牢なベースラインを超える大幅な改善を実現します。オンライン A/B テスト中に、クリックスルー率タスクのクリック指標が +5.0% 改善されました。 CVR タスクでは、コンバージョン指標が 2.3% 改善されました。さらに、PFD トレーニングのいくつかの問題を解決することにより、蒸留することなくベースラインと同等のトレーニング速度が得られます。
用紙のアドレス:
https://arxiv.org/abs/1907.05171
情報検索「制御可能な多関心レコメンデーションフレームワーク」

単位: アリババ
まとめ:近年、ディープラーニング技術の急速な発展に伴い、ニューラルネットワークは電子商取引のレコメンデーションシステムに広く利用されています。私たちは、レコメンダー システムの推奨問題を、ユーザーが次に操作する可能性のあるアイテムを予測することを目的とした逐次的な推奨問題として形式化します。最近の研究では、通常、ユーザーの行動シーケンスから全体的な埋め込みが提供されます。ただし、統合されたユーザーの埋め込みでは、一定期間にわたるユーザーの複数の関心を反映することはできません。本稿では、逐次レコメンデーションのための、ComiRecと呼ばれる新しい制御可能な多関心フレームワークを提案します。当社の多関心モジュールは、ユーザーの行動シーケンスから複数の関心を取得し、大規模なアイテム プールから候補を取得するために使用できます。次に、これらの項目が集約モジュールに入力されて、全体的な推奨情報が取得されます。集約モジュールは、制御可能な要素を利用して、推奨事項の精度と多様性のバランスをとります。私たちは、Amazon と Taobao という 2 つの現実世界のデータセットに対して、順次レコメンデーション実験を実施します。実験結果は、私たちのフレームワークが最先端のモデルに比べて大幅な改善を達成していることを示しています。私たちのフレームワークは、アリババのオフライン分散クラウド プラットフォームにもうまく導入されました。
用紙のアドレス:
https://arxiv.org/abs/2005.09347
情報検索「ベイジアングラフ畳み込みニューラルネットワークに基づく正確かつ多様なレコメンドフレームワーク」

ユニット: ファーウェイ
まとめ:レコメンドシステムでは、ユーザーやアイテムの表現を正確に学習することが非常に重要な課題となります。グラフ畳み込みネットワークの広範な研究と応用により、グラフ畳み込みネットワークを推奨システムに適用することがますます注目を集めています。既存のグラフベースのレコメンデーション モデルはすべて、観察されたユーザーとアイテムのインタラクション グラフをユーザーとアイテム間のグラウンド トゥルースとみなします。ただし、レコメンダー システムのシナリオでは、この設定が常に適切であるとは限りません。たとえば、この設定では、インタラクション グラフ内のエッジのないインタラクションは負の例とみなされます。この未観測のインタラクションは将来潜在的なインタラクションになる可能性がありますが、一方で、観測されたエッジの一部は実際のインタラクションであるか、ノイズによって引き起こされる可能性があります。 。この問題を解決するには、この研究では、ベイジアン グラフ畳み込みネットワーク BGCN を使用して、ユーザーとアイテムの相互作用グラフの不確実性をモデル化します。
トレーニング プロセス用の詳細な BPR 損失関数を提案し、モデルに基づいて予測を行う方法についても詳細に説明します。 4つの公開データで検証したところ、BGCNモデルはさまざまな評価指標において既存のグラフベースの推奨モデルよりも優れています。製品データセットでも検証したところ、BGCN モデルの精度も向上していることがわかりました。さらに、BGCN モデルの推奨結果は精度と多様性の両方を考慮しており、「コールド スタート」ユーザーに対する推奨効果がより顕著であることもわかりました。
関連リンク:
https://zhuanlan.zhihu.com/p/142812078
ルート計画「Polestar: インテリジェントで効率的な全国公共交通ルート エンジン」

単位: 百度
まとめ:公共交通機関は人々の日常生活において重要な役割を果たしています。公共交通機関は、他のどの交通機関よりも環境に優しく、効率的で経済的であることが証明されています。しかし、交通網の拡大と旅行状況の複雑化により、公共交通機関を利用してある場所から別の場所への最適なルートを効率的に見つけることが困難になっています。この目的を達成するために、本稿では、スマートで効率的な公共交通ルートのためのデータ駆動型エンジンである Polaris を提案します。具体的には、まず、時間や距離などのさまざまな移動コストに対する公共交通システムの新しい公共交通グラフ (PTG) モデルを提案します。次に、一般的なものを紹介しますルート探索アルゴリズムと効率的なサイトバインディング手法により、候補ルートを効率的に生成します。これに基づいて、動的旅行シナリオにおけるユーザーの好みを捕捉するためのデュアルパス候補ルートランキングモデルを提案します。最後に、2 つの現実世界のデータセットでの実験により、効率と有効性の点で Polaris の利点が実証されました。実際、2019 年の初めに、Polaris は世界最大の地図サービスの 1 つである Baidu Maps にすでに導入されていました。これまでに、Polaris は 330 以上の都市にサービスを提供し、毎日 1 億件以上のクエリに答え、ユーザーのクリックスルー率の大幅な向上を達成しました。
用紙のアドレス:
https://arxiv.org/abs/2007.07195
経路計画「ハイブリッド時空間グラフ畳み込みネットワーク: ナビゲーション データを使用して交通予測を改善する」

単位: アリババ
まとめ:オンライン ナビゲーション サービス、ライドシェアリング、スマート シティ プロジェクトの人気により、最近では交通予測への関心が高まっています。道路交通の非定常的な性質により、コンテキスト情報が欠如していると、予測の精度が根本的に制限されます。この問題に対処するために、私たちはハイブリッド時空間グラフ畳み込みネットワーク (H-STGCN) を提案します。これは、今後の交通量データを活用して将来の移動時間を「推測」することができます。具体的には、オンラインナビゲーションエンジンから今後のトラフィックを取得するアルゴリズムを提案します。区分的な線形の流れと密度の関係を利用して、新しい変圧器構造が今後の体積を同等の移動時間に変換します。この信号を一般的に使用される移動時間信号と組み合わせて、グラフの畳み込みを適用して空間依存性をキャプチャします。特に、固有トラフィックの近接性を反映する複合隣接行列を構築します。私たちは現実世界のデータセットに対して広範な実験を行っています。結果は、H-STGCN が、特に非反復的な輻輳の予測において、さまざまな指標において最先端の方法よりも大幅に優れていることを示しています。
用紙のアドレス:
https://arxiv.org/abs/2006.12715
経路計画「シェア自転車エコノミーのもとで:大規模チーム競技における個人処理効果の予測」

ユニット: ディディ
まとめ:連続的なレコメンデーションにおける累積ユーザー エンゲージメント (累積クリック数など) を最大化するには、即時のユーザー エンゲージメント (クリックスルー率など) の向上とユーザーの閲覧促進という 2 つの潜在的に矛盾する目標の間にトレードオフが存在することがよくあります。さらに多くの項目)。既存の研究では、これら 2 つのタスクを別々に研究することが多いため、最適とはいえない結果が得られることがよくあります。この論文では、オンライン最適化の観点からこの問題を研究し、ユーザーの閲覧時間の延長と即時のユーザー エンゲージメントの向上を明示的にトレードオフする柔軟で実用的なフレームワークを提案します。具体的には、アイテムをアクション、ユーザーのリクエストを状態、ユーザーの離脱を吸収状態とみなして、各ユーザーの行動をパーソナライズされたマルコフ決定プロセス (MDP) として定式化します。これにより、累積的なユーザー エンゲージメントを最大化するという問題が確率論的に還元されます。最短パス (SSP) の問題。同時に、即時のユーザー参加と離脱確率の推定を通じて、SSP 問題が動的計画法によって効果的に解決できることが示されました。現実世界のデータセットでの実験により、このアプローチの有効性が実証されています。さらに、この方法は大規模な電子商取引プラットフォームに導入され、累計クリック数が 7% 以上増加しました。
用紙のアドレス:
消費者サービス「継続的なレコメンデーションにおける累積ユーザー エンゲージメントの最大化: オンライン最適化の観点」

単位: アリババ
まとめ:連続したレコメンデーションで累積ユーザー エンゲージメント (累積クリック数など) を最大化するには、多くの場合、相反する可能性がある 2 つの目標の間でトレードオフが必要になります。つまり、より高い即時ユーザー エンゲージメント (クリックスルー率など) を追求することと、ユーザーの閲覧を奨励すること (つまり、プロジェクトの露出が増える)。既存の研究では、これら 2 つのタスクを別々に研究することが多く、そのため次善の結果が得られることがよくあります。
この論文では、オンライン最適化の観点からこの問題を研究し、ユーザーの閲覧時間の延長と即時のユーザー エンゲージメントの向上を明示的にトレードオフする柔軟で実用的なフレームワークを提案します。具体的には、アイテムをアクション、ユーザーのリクエストを状態、ユーザーの離脱を吸収状態として扱うことで、各ユーザーの行動を個別化されたマルコフ決定プロセス (MDP) として定式化し、ユーザーの累積参加を最大化する問題を確率的最短経路に単純化します。 (SSP) の問題。同時に、瞬間的なユーザーの参加と離脱の確率を推定することにより、動的計画法が SSP 問題を効果的に解決できることが証明されました。実際のデータセットでの実験により、このアプローチの有効性が実証されました。さらに、この方法は大規模な電子商取引プラットフォームに導入され、累計クリック数が 7% 以上増加しました。
用紙のアドレス:
消費者サービス「顧客サービスのためのインテリジェントなチャットボットの構築: タイムリーな対応方法を学ぶ」

ユニット: ディディ
まとめ:
近年、インテリジェントなチャットボットが顧客サービスの分野で広く使用されています。チャットボットが顧客とのスムーズな会話を維持するための主な課題の 1 つは、適切なタイミングで応答することです。ただし、ほとんどの高度なチャットボットは、対話ごとのスキームに従っています。このようなチャットボットは顧客が発話するたびに応答するため、場合によっては不適切な応答が発生したり、会話の方向を誤ったりする可能性があります。
この論文では、この問題を解決するためにマルチラウンド応答トリガモデル (MRTM) を提案します。 MRTM は、自己教師あり学習スキームを通じて、顧客とエージェント間の大規模な人間と機械の会話から学習します。コンテキストと応答の間の意味的一致関係を使用して意味的一致モデルをトレーニングし、非対称セルフアテンション メカニズムを通じてコンテキスト内で共起する発話の重みを取得します。次に、重みを使用して、特定のコンテキストに応答する必要があるかどうかが決定されます。
私たちは、現実世界のオンライン顧客サービス システムから収集した 2 つの会話データセットに対して広範な実験を行っています。結果は、MRTM がベースラインを大幅に上回っていることを示しています。さらに、MRTM を Didi の顧客サービス チャットボットに統合しました。チャットボットは、適切な応答時間を特定する機能に基づいて、複数回の会話にわたる情報を段階的に集約し、適切なタイミングでよりインテリジェントに応答できます。
用紙のアドレス:
https://dl.acm.org/doi/10.1145/3394486.3403390
電子商取引「デュアル異種グラフ アテンション ネットワーク、電子商取引における店舗検索のロングテール パフォーマンスの向上」

単位: アリババ
まとめ:
「デュアル異種グラフ アテンション ネットワーク、電子商取引における店舗検索のロングテール パフォーマンスを向上」
タオバオのユーザーと店舗の大幅な増加に伴い、店舗検索はいくつかの特有の課題に直面しています。
1) 多くの店舗名は、販売する商品、つまりユーザーのクエリと店舗名の間の意味上のギャップを完全に表現できません。
2) ユーザーとの対話が欠如しているため、ロングテール クエリに対して適切な検索結果を提供したり、クエリに関連性の高いロングテール ストアを取得したりすることが困難です。これら 2 つの主要な課題に対処するために、グラフ ニューラル ネットワーク (GNN) に目を向けます。具体的には、店舗検索と製品検索からのユーザーインタラクションデータを使用して、2 タワーアーキテクチャと統合されたデュアルヘテロジニアスグラフアテンションネットワーク (DHGAT) を提案します。まず、ユーザーの検索行動、ユーザーのクリック行動、ユーザーの購入記録からの一次および二次近接性を活用して、店舗検索のコンテキストで異種グラフを構築します。次に、DHGAT は、クエリとストアの異種および同種の近傍を使用して自身の表現を強化することに重点を置くように設計されており、これによりロングテール現象の軽減に役立ちます。さらに、DHGAT は、関連するアイテムのタイトルを結合することで意味論的なギャップを軽減し、それによってクエリ テキストと店舗名の意味論を強化します。
用紙のアドレス:
https://dl.acm.org/doi/10.1145/3394486.3403393
Eコマース「リクエストレベルで納期を保証する広告プランニング:予測と配分」》
単位: テンセント
まとめ:オンライン広告配信に関する既存の研究は、通常、サービスをグループ レベルまたはユーザー レベルの供給配分問題としてモデル化し、検索結果が利用可能で契約が締結されていることを前提としているため、オンライン サービスの最適な配分を探索することに焦点を当てています。そして、これらのテクノロジーは、今日の業界トレンドのニーズを満たすには十分ではありません。
1) 広告主はより正確なターゲティングを追求しており、これにはユーザーレベルの属性だけでなくリクエストレベルの属性も必要です。
2) ユーザーはよりフレンドリーな広告サービスを好みますが、これにより配信制限が増加します。
3) パブリッシャーの収益成長のボトルネックは、広告サービスだけでなく、予測精度や販売戦略にもあります。
リクエストレベルのモデルの規模は人口レベルやユーザーレベルのモデルよりも桁違いに大きいため、これらの問題を解決するのは簡単ではありません。
この課題に直面して、私たちは、インプレッション予測、販売、サービスを含む 3 つの重要な要素を注意深く最適化し、リクエストレベルで配信を保証した総合的に設計された広告プランニングシステムを提案しました。当社のシステムは Tencent のオンライン配信保証型広告システムに導入され、1 年近くにわたって数十億人のユーザーにサービスを提供してきました。大規模な実世界のデータと展開されたシステムのパフォーマンスの評価により、私たちの設計によりリクエストレベルのインプレッション予測の精度と配信速度が大幅に向上できることがわかりました。
論文アドレス: まだ公開されていません
医療予測「INPREM: 解釈可能で信頼できる医療予測モデル」

単位: テンセント
まとめ:
過去の電子医療記録に基づいて個別化医療のための予測モデルを構築することは、活発な研究分野となっています。強力な特徴抽出機能のおかげで、深層学習手法は多くの臨床予測タスクで良好な結果を達成しています。しかし、解釈可能性と信頼性が欠如しているため、実際の臨床意思決定のケースに適用することは困難です。
この問題を解決するために、この論文では、医療向けの解釈可能で信頼できる予測モデル (INPREM) を提案します。まず、INPREM は、解釈可能性を実現するために、解釈可能性の線形モデルとして設計されています。同時に、非線形関係が学習重みにエンコードされ、各訪問間および各訪問内の依存関係がモデル化されます。これにより、入力変数の寄与行列を取得できます。予測結果の証拠として機能し、医師がモデルがなぜそのような予測を与えるのかを理解するのに役立ち、モデルをより解釈しやすくします。次に、信頼性を高めるために、モデルの各重みにランダム ゲート (ベルヌーイ分布に従ってオンまたはオフにする) を配置し、データ ノイズを推定するための追加の分岐を配置します。このモデルは、モンテカルロ サンプリングとデータ ノイズを考慮した目的関数を使用して、各予測の不確実性を取得します。次に、捕捉された不確実性によってモデルの信頼レベルが医師に通知され、モデルの信頼性が高まります。私たちの経験は、提案された INPREM が既存の方法に比べて大きな利点があることを示しています。
用紙のアドレス:
https://dl.acm.org/doi/abs/10.1145/3394486.3403087
KDD 2020 オンラインカンファレンスの登録を開始しました
KDD 2020 は進行中であり、カンファレンスの登録チャンネルがオープンしています。
https://www.kdd.org/kdd2020/#!
完全な議題は発表されています。興味のある学生は Zoom を通じてリモートで参加できます。学生チケットは 50 ドルです。最も注目されているリンクの 1 つである開会式と授賞式は、現地時間 8 月 25 日の 8:00 ~ 10:00 に開催されますので、ご期待ください。
完全なスケジュールについては、以下を参照してください。
https://www.kdd.org/kdd2020/schedule
ソース:
https://www.kdd.org/kdd2020/accepted-papers#ads-papers
https://www.aminer.cn/conf/kdd2020/papers
- 以上 -








