Command Palette
Search for a command to run...
1.1 T arXiv データセット: 170 万件の論文、来世でも見ることができる
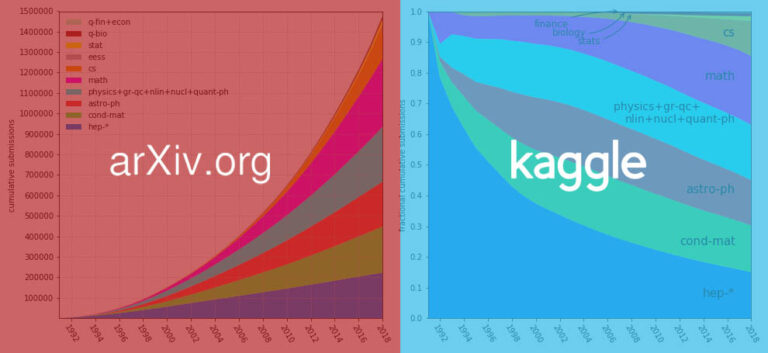
最近、arXiv は 170 万件以上の論文をデータセットにパッケージ化し、kaggle プラットフォームに配置しました。将来的には、論文へのアクセスとダウンロードがより便利になるでしょう。データセットのサイズは現在約 1.1 TB で、毎週の更新で増加し続けています。
170 万件以上の学術論文、サイズ 1.1 TB、これは arXix によって最近 kaggle で公開されたデータセットで、ネチズンはそれについて尋ね、「とてもクールだ!」と叫びました。
データセット編集チームは、これによって関連する研究者がより豊富な機械学習テクノロジーを探索し、より多くの発見や革新を生み出すきっかけとなることを期待していると述べた。
オープンデータセットで論文検索が簡単に
arXiv は 30 年近くにわたり、一般の人々や研究チームに幅広い分野をカバーする学術論文へのオープン アクセスを提供してきました。物理学の膨大な分野から、コンピューターサイエンスの多くの分野、さらには数学、統計学、電気工学、定量生物学、経済学に至るまで、あらゆる分野に及びます。
arXiv には多くの研究論文があり、多くの人が恩恵を受けていますが、ただし、閲覧、検索、並べ替えが不便であるなどの欠点があることがよく報告されています。arXiv で論文検索のヒントを見つけて共有した人もいます。
したがって、arXiv をよりアクセスしやすくするために、コーネル大学は現在、Kaggle で無料のオープン arXiv データ セットを提供しています。
このデータ セットには 170 万件の学術論文が含まれており、論文のタイトル、著者、カテゴリー、要約、全文 PDF などの論文関連の要素 (特徴) も含まれています。
arXiv のエグゼクティブ ディレクターである Eleonora Presani 氏は、「arXiv コーパス全体が Kaggle にあることで、arXiv 論文の可能性が大幅に高まります。データセットを Kaggle で利用できるようにすることで、人々がこれらの論文を読んで知識を学ぶだけではなくなりました。」さらに重要なことは、arXiv の背後にあるデータと情報が機械可読形式で公開されていることです。 」

Presani 氏はまた、「arXiv は単なる紙のライブラリではなく、知識を共有するためのプラットフォームです。そのためには、利用可能な知識を提示し説明する方法で革新を続ける必要があります。そして、Kaggle ユーザーは、この革新の限界を押し上げるのに貢献することができます」と述べました。私たちにとってコミュニティと協力するための新しいチャネルになりました。」
視聴: arXiv データ セットには何が含まれますか?
arXiv データセットの基本情報は次のとおりです。
arXiv データセット
投稿者: ポール・ギンスパーグ、ムーンショット・ファクトリー、ジャック・ヒダリー
含まれる数量:170万以上の学術論文
データ形式:json
データサイズ:1.1TB
発売時期:2020年8月
ダウンロードアドレス:https://www.kaggle.com/Cornell-University/arxiv
現在、arXiv データセットは、次のような各論文に関連するエントリを含むメタデータ ファイルを json 形式で提供します。
- id: 論文アクセスアドレス。論文にアクセスするために使用できます。
- 提出者: 論文提出者。
- 著者: 論文の著者。
- タイトル: 論文のタイトル;
- コメント: 論文のページ数や図表などのその他の情報。
- Journal-ref: 論文が掲載された雑誌情報。
- doi: デジタルオブジェクト識別子。
- 要約: 論文の要約。
- カテゴリ: arXiv 上で論文が属するカテゴリまたはタグ。
- バージョン: 紙版。
これらの膨大な論文を簡単に閲覧、フィルタリング、レビューすることができます。
さらに、ユーザーは次の 2 つのリンクを介して arXiv 上の各論文に直接アクセスできます。
- https://arxiv.org/abs/{id}: 抄録およびその他のリンクを含む紙のページ。
- https://arxiv.org/pdf/{id}: 論文の PDF ダウンロード ページ。
バッチ アクセスも利用できます。ユーザーは、Google Cloud Storage のバケット gs://arxiv-dataset で、または Google API (json ドキュメントと xml ドキュメント) を通じて完全な PDF ファイルを無料で入手できます。
論文の PDF ファイルは、tarpdfs フォルダー内の複数の .tar.gz ファイルにグループ化されており、データセット全体のサイズは約 1.1 TB です。詳細は次のとおりです (以下は 2010 年 1 月 (1001) のフィールド 1、2、および 3 です)。
tarpdfs/arXiv_pdf_1001_001.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_001.tar.gz)tarpdfs/arXiv_pdf_1001_002.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_002.tar.gz)tarpdfs/arXiv_pdf_1001_003.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_003.tar.gz)
ユーザーは、gsutil などのツールを使用してデータをローカル コンピューターにダウンロードすることもできます。

しかし、このデータセットの具体的な使用シナリオは何でしょうか?多くのネチズンは、トピックモデリング、このデータを使用した GPT-3 のトレーニングなどのアイデアをすでに持っています。
arXiv: 学術論文の巨大なリソース ライブラリ
科学研究や学術界の学生は、arXiv に精通している必要があります。
これは、物理学、数学、コンピューター サイエンス、生物学の論文のプレプリントを集めた Web サイトであり、科学研究者がアイデアを「活用する」ためのプラットフォームを提供するだけでなく、誰もが論文を検索して読むための巨大なリソース ライブラリでもあります。 。
2008 年 10 月の時点で、arXiv.org は 500,000 を超えるプレプリントを収集し、2014 年末までにそのコレクションは 100 万に達しました。2016 年 10 月の時点で、arXiv への投稿は月間 10,000 記事を超えました。
arXiv はもともと、1991 年に物理学者のポール ギンズバーグによって設立された Web サイトでした。当初は物理学の論文のプレプリントを収集することを目的としていたが、後に天文学、数学、その他の分野も含まれるようになりました。
arXiv はもともとロス アラモス国立研究所 (LANL) でホストされていたため、初期の頃は「LANL プレプリント データベース」と呼ばれていました。 arXiv は現在コーネル大学に拠点を置き、世界中にミラー サイトを持っています。この Web サイトは 1999 年に arXiv.org に名前変更されました。
さて、平たく言えば、arXiv は「他人を利用する」ために使用される Web サイトであり、論文に掲載される前に自分のアイデアが他人に盗用されるのを防ぐために、研究者はまず arXiv 上でその素案を公開し、自分の独創性を証明します。 。
参考文献:
https://www.kaggle.com/Cornell-University/arxiv?select=arxiv-metadata-oai-snapshot.json
https://zh.wikipedia.org/wiki/ArXiv
- 以上 -








