Command Palette
Search for a command to run...
Lyft が最大の L5 自動運転予測データセットを公開し、スポーツ予測コンテストを開始
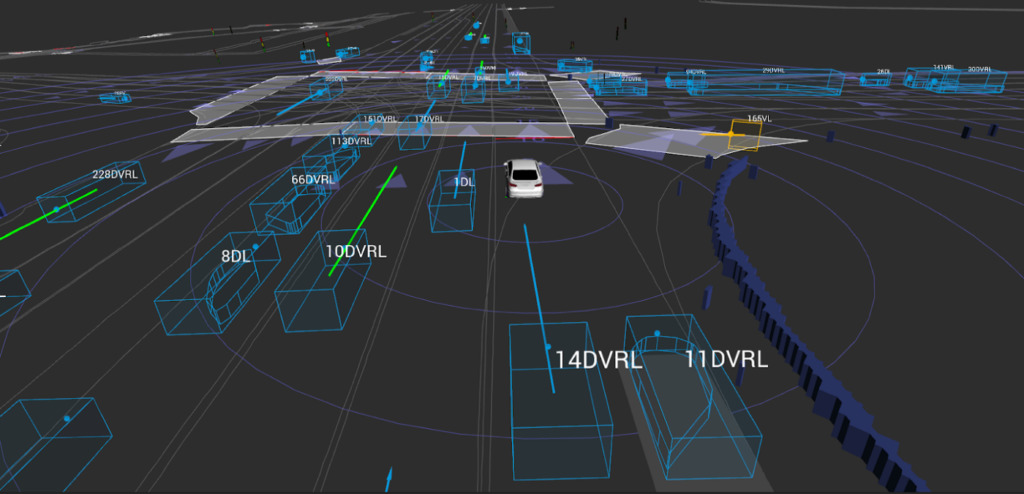
Lyft は最近、1,000 時間以上の運転記録を含むレベル 5 の自動運転予測データセットをリリースしました。さらに、同社は賞金総額 30,000 ドルの自動運転スポーツ予測チャレンジも開始しました。
Lyft は新しいデータセットをリリースしました。
昨年 7 月、Lyft は L5 レベルの自動運転知覚データセットをリリースしました。これには、人間がラベルを付けた 55,000 以上の 3D 注釈フレームが含まれています。当時、これは公式には、同様の製品の中で最大の公開データ セットと呼ばれていました。
ちょうど 1 年ほど前、Lyft は別の L5 レベルの自動運転予測データセットをリリースしました。

アプリケーションのダウンロード アドレス: https://www.catalyzex.com/paper/arxiv:2006.14480/dataset
170,000 のシーンと 2,500 キロメートルを超える道路データ
Lyft がリリースしたデータセットは動き予測に焦点を当てています。当局者らは、自動運転分野における長期的な研究課題は、交通の動きを予測するのに十分な堅牢性と信頼性を備えたモデルを作成することであると述べた。
データは、カリフォルニア州パロアルトの固定ルートで 23 台の自動運転車からなるフリートによって 4 か月間にわたって収集されました。遭遇した車、歩行者、その他の障害物の運転ログが含まれます。
データセットには具体的には次のものが含まれます。
- 1000時間:1,000 時間以上の自動運転車の移動記録。
- 170,000 シーン:各シーンは約 25 秒続き、信号機、航空地図、歩道などが含まれます。
- 16,000マイル: 公道からの 16,000 マイル (約 2,575 キロメートル) のデータ。
- 15242 個の注釈付き画像:ラベル付き要素の高解像度セマンティック マップと、エリアの高解像度航空写真が含まれています。

このモーション データは、Lyft 車両の屋根に取り付けられたセンサー アレイによって収集され、車両が数万マイル走行する際に LIDAR、カメラ、レーダー データを捕捉します。
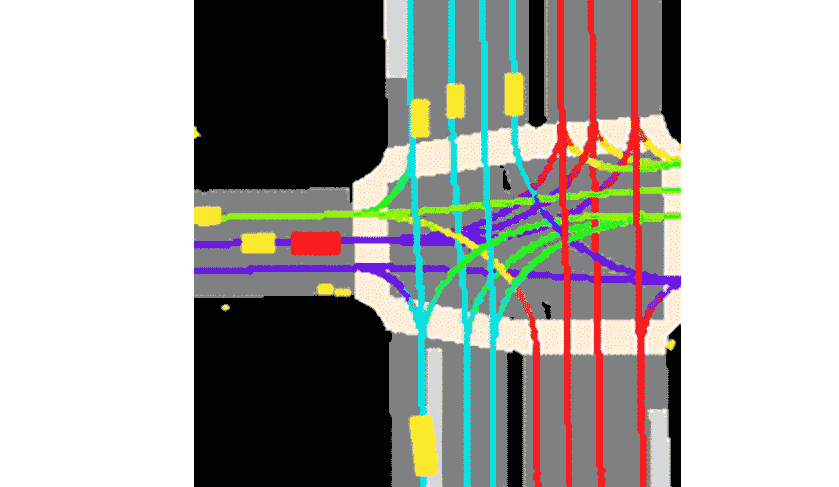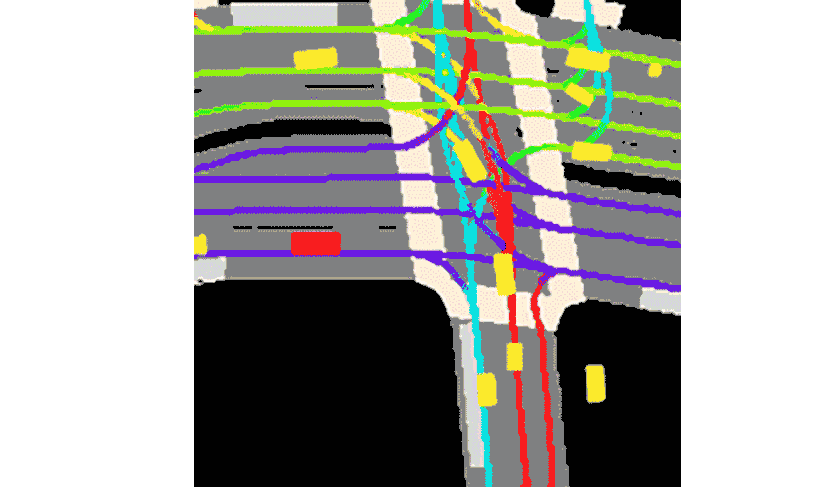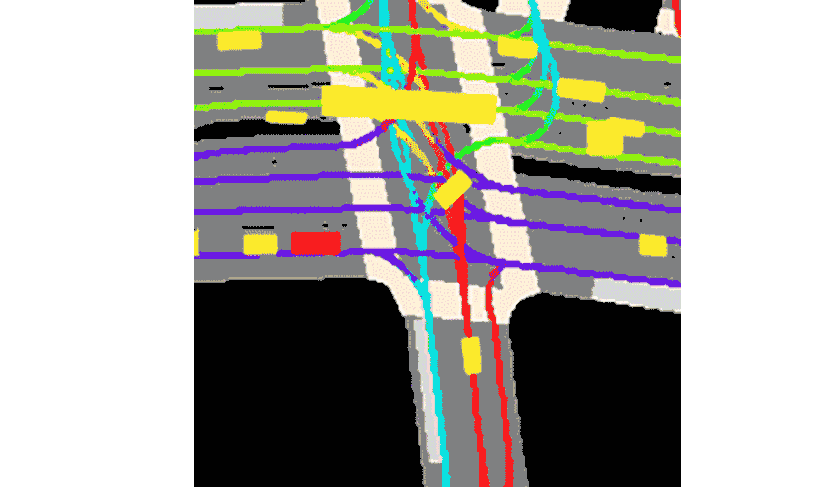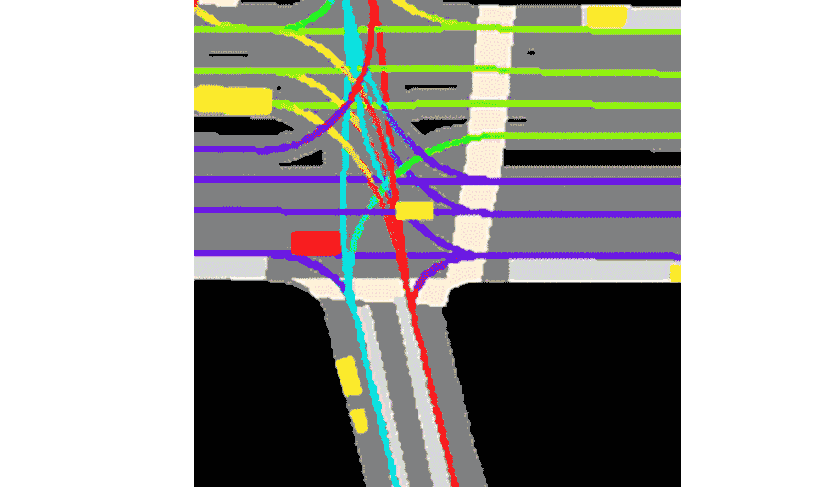
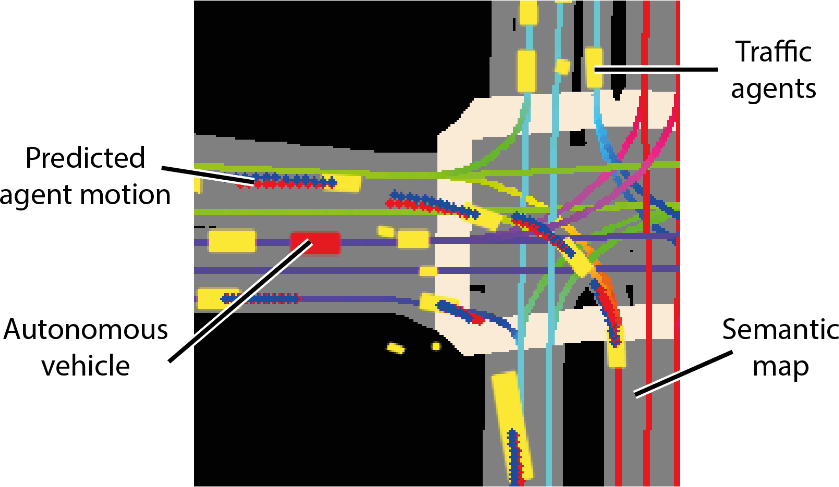
Lyft によれば、コレクションと提供されるツールキットは次のとおりです。これまでで最大かつ最も完全かつ詳細なデータセットを構成し、自動運転の開発、動作予測、計画、シミュレーションなどの機械学習タスク用。
現在、このデータ セットの一部のサブセットのみがダウンロードできます。
- サンプル データセット (53 MB)
- トレーニングデータセット(3分割、合計69.4GB)
- 鳥瞰図 (2 GB)
- セマンティック グラフ (2 MB)
ダウンロードアドレス:
賞金総額 30,000 ドルのチャレンジを開始する
同時に、Lyft はまた、Google Kaggle プラットフォーム上で 8 月に開始されるチャレンジを開始し、総額 30,000 ドルの賞金を授与する予定です。

このチャレンジのハイライト:
- 競技要件:出場者は車両の動きを予測します。
- 準備:公式通知によると、今後、研究者やエンジニアはトレーニング データ セットと Python ベースのソフトウェア パッケージをダウンロードして、データの実験を行うことができます。テストおよび検証スイートはコンテストの一環としてリリースされるためです。
- 最終目的:データセットやコンテストを通じて研究コミュニティに力を与え、イノベーションを加速します。
Lyft エンジニアリング担当シニアディレクターの Sacha Arnoud 氏とオーディオおよびビデオリサーチ担当ディレクターの Peter Ondruska 氏はブログ投稿で次のように書いています。「データは、最新の機械学習技術を試す原動力です。大規模で高品質な自動運転データへのアクセスは限られていますが、それがこの研究での実験を妨げるものではありません。 」
「私たちは自動運転が交通システムのより便利で、より安全で、より持続可能な部分になると信じています」とアルノウド氏とオンドルスカ氏は語った。「研究コミュニティとデータを共有することで、自動運転における重要かつ未解決の課題を特定したいと考えています。」
クリック元の記事を読む、より高品質のデータセットを入手できます。
ブログアドレス:
用紙のアドレス:
https://arxiv.org/pdf/2006.14480.pdf
GitHub アドレス:
https://github.com/lyft/l5kit/
- 以上 -








