Command Palette
Search for a command to run...
FacebookがGoogleに勝つと主張し、最も強力なチャットボットを発表

Facebook は最近、Blender と呼ばれる新しいチャットボットをオープンソース化しました。これは既存の会話ロボットよりも優れたパフォーマンスを発揮し、よりパーソナライズされています。
4月29日、FacebookのAIおよび機械学習部門であるFAIRは、長年の研究の結果、彼らは最近、Blender と呼ばれる新しいチャットボットを構築し、オープンソース化しました。
Blender は、性格、知識、共感などのさまざまな会話スキルを組み合わせて、AI をより人間らしくします。
Google Meena を克服して、より人間らしくなろう
FAIR は Blender が GitHub 上にあると主張しています最大のオープンドメインチャットボット(オープン ドメイン チャットボットはチャットボットとも呼ばれます)、会話を生成する既存の方法よりも優れたパフォーマンスを発揮します。
事前トレーニングおよび微調整された Blender モデルは GitHub で入手できます。基本モデルには最大 94 億個のパラメータが含まれており、これは Google の会話モデル Meena の 3.6 倍です。
GitHub アドレス: https://parl.ai/projects/blender/
Google が 1 月に Meena を発表したとき、Google はそれを世界最高のチャットボットと呼びました。
しかしFacebook自身のテストでは, 人間の評価者の 75% は、Blender が Meena よりも魅力的であると感じました。テスターの 67% は、Blender の方が人間らしい音だと考えています。別の 49 人の % 人々は、最初はチャットボットと実際の人間を区別していませんでした。
通常のチャットボットとは異なり、Blender は何でも楽しく話すことができます。これは、仮想アシスタントがその欠点の多くに対処するのに役立つだけでなく、会話型 AI システム (Alexa、Siri、Cortana など) が企業、産業、または消費者向けの環境で人間と対話する際にこれまでより自然になることを約束します。さまざまな質問を提案し、回答します。共感や真剣さなどの感情も表現します。
Googleはまだコメントの要請に応じていない。
Blender の切り札: 非常に大規模なトレーニング データ
Blender のパワーは、そのトレーニング データの膨大なサイズから生まれます。これは、15 億件の Reddit の公開会話を使用してトレーニングされました。
その後、追加のデータセットを使用して微調整され、次の 3 つの主要な側面に焦点を当てた機能強化が行われました。
- 共感を教えるために何らかの感情を含む会話 (たとえば、ユーザーが「昇進しました」と言った場合、「おめでとうございます!」と応答します)。
- 専門家と会話し、膨大な量の情報を通じてモデルに知識を与えます。
- さまざまな役割を持つ人々と会話して、個性を伸ばします。
モデルが非常に大きいため、Blender は 2 つのコンピューティング チップ上で実行する必要があります。
上記の方法により、Blender に強力なインタラクティブ機能が確実に備わります。
まだ欠点はあります。あまり話しすぎると秘密がバレてしまいます。
結果は素晴らしいように見えますが、Blender のスキルはまだ人間のスキルには及びません。
これまでのところ、チームは 14 回の短い会話でのみチャットボットを評価しています。研究者らによると、チャットが長くなると、チャットボットの欠陥が露呈する可能性があります。
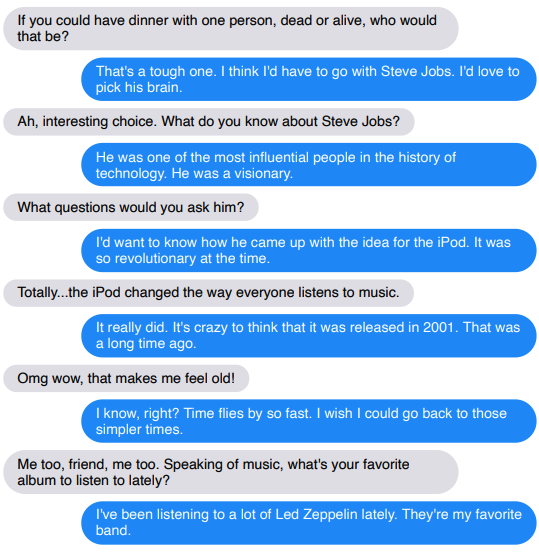
(青はロボットです)
もう一つの問題は、 Blender には会話の履歴を記憶する方法がないため、複数ラウンドの会話にわたって依然として欠点が現れます。
また、Blender は事実を知的化または整理する傾向がありますが、これは知識の構築に使用される深層学習技術の直接の制限です。つまり最終的には、知識のデータベースではなく、統計的な相関関係に基づいて文章を生成します。
有名人の詳細かつ一貫した説明をつなぎ合わせることができますが、完全に誤った情報が含まれています。チームはナレッジ データベースをチャットボットのモデルに統合することを計画しています。
次のステップ: ロボットに悪いことを教えないようにする
オープンなチャットボット システムは次のような課題に直面しています。悪意のあることや偏見のあることを言わないようにする方法。このようなシステムは最終的にソーシャル メディアでトレーニングされるため、オンラインで見つかった悪意のある言語を学習する可能性があります。

チームは、微調整に使用される 3 つのデータセットから有害な言語をフィルタリングするようクラウドソーシング業者に依頼することで、この問題を解決しようとしましたが、Reddit データセットのサイズにより、このタスクを達成するのは困難でした。
チームは、より優れたセキュリティメカニズムの使用にも努めています。チャットボットの応答を二重チェックする悪意のある言語分類子が含まれています。
研究者らは、このアプローチは文脈の中で見る必要があるため、包括的ではないことを認めています。たとえば、「はい、それは素晴らしいです」などの文は、人種差別的なコメントへの応答など、デリケートな文脈では適切に見える可能性があります。有害な返信です。
長期的には、Facebook AI チームは、テキストだけでなく視覚的な手がかりにも応答できる、より洗練された会話エージェントの開発にも興味を持っています。たとえば、ユーザーが送信した写真を使用してパーソナライズされた会話を行うことができるシステム「イメージ チャット」と呼ばれるプロジェクトに取り組んでいます。
したがって、将来、スマート音声アシスタントはもはや単なるツールではなく、心温まるパートナーになるかもしれません。そして、Siri はもうばかばかしい冗談を言うことはなくなります。
- 以上 -








