Command Palette
Search for a command to run...
PyTorch 1.5 がリリース、TorchServe が AWS と提携

最近、PyTorch はバージョン 1.5 へのアップデートをリリースしました。人気が高まっている機械学習フレームワークとして、今回は大幅な機能アップグレードも行われました。さらに、Facebook と AWS も協力して 2 つの重要な PyTorch ライブラリを立ち上げました。
PyTorch が実稼働環境で使用されることが増えているため、トレーニングを効率的に拡張し、モデルをデプロイするためのより優れたツールとプラットフォームをコミュニティに提供することが PyTorch の最優先事項となっています。
PyTorch 1.5 が最近リリースされました。主要な torchvision、torchtext、torchaudio ライブラリがアップグレードされ、Python API から C++ API へのモデルの変換などの機能が導入されました。

その上、Facebook はまた、Amazon と協力して、TorchServe モデル サービス フレームワークと TorchElastic Kubernetes コントローラーという 2 つの重要なツールを立ち上げました。
TorchServe は、PyTorch モデル推論の大規模な展開に優れた互換性を備えたクリーンな産業グレードのパスを提供することを目的としています。
TorchElastic Kubernetes コントローラーを使用すると、開発者は Kubernetes クラスターをすばやく使用して、PyTorch でフォールトトレラントな分散トレーニング ジョブを作成できます。
これは、Facebook が Amazon と協力して、大規模なパフォーマンス AI モデル フレームワークの TensorFlow に宣戦布告する動きであると思われます。
TorchServe: 推論タスク用
推論用の機械学習モデルを大規模に展開するのは簡単な作業ではありません。開発者は、モデル アーティファクトの収集とパッケージ化、安全なサービス スタックの作成、予測用のソフトウェア ライブラリのインストールと構成、API とエンドポイントの作成と使用、監視用のログとメトリックの生成、および場合によっては複数のサーバー モデル バージョンの複数のシステムを管理する必要があります。
これらの各タスクにはかなりの時間がかかるため、モデルのデプロイメントが数週間、場合によっては数か月も遅くなる可能性があります。さらに、低遅延のオンライン アプリケーション向けにサービスを最適化することも必須です。
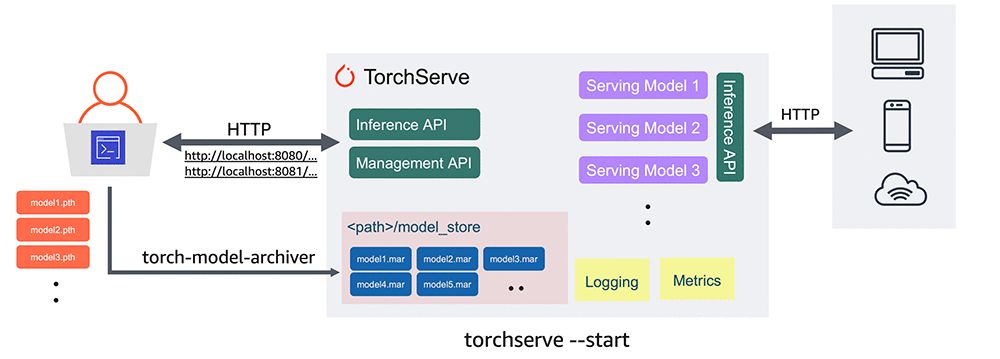
以前に PyTorch を使用していた開発者には、PyTorch モデルをデプロイするための公式にサポートされている方法がありませんでした。プロダクション モデル サービス フレームワークの TorchServe のリリースにより、この状況は変わり、モデルをプロダクションに導入しやすくなります。
次の例では、Torchvision からトレーニング済みモデルを抽出し、TorchServe を使用してデプロイする方法を説明します。
#Download a trained PyTorch modelwget https://download.pytorch.org/models/densenet161-8d451a50.pth#Package model for TorchServe and create model archive .mar filetorch-model-archiver \--model-name densenet161 \--version 1.0 \--model-file examples/image_classifier/densenet_161/model.py \--serialized-file densenet161–8d451a50.pth \--extra-files examples/image_classifier/index_to_name.json \--handler image_classifiermkdir model_storemv densenet161.mar model_store/#Start TorchServe model server and register DenseNet161 modeltorchserve — start — model-store model_store — models densenet161=densenet161.mar
トーチサーブのベータ版が利用可能になりました。特徴は次のとおりです。
- 独自のエコロジーAPI: 予測のための推論 API とモデル サーバーを管理するための管理 API をサポートします。
- 安全な導入: 安全な展開のための HTTPS サポートが含まれます。
- 強力なモデル管理機能: コマンド ライン インターフェイス、構成ファイル、またはランタイム API を介して、モデル、バージョン、および個々のワーカー スレッドの完全な構成を可能にします。
- モデルアーカイブ: モデル、パラメータ、およびサポート ファイルを単一の永続的なアーティファクトにパッケージ化するプロセスである「モデル アーカイブ」を実行するツールを提供します。シンプルなコマンド ライン インターフェイスを使用して、PyTorch モデルを提供するために必要なものすべてを含む単一の ".mar" ファイルとしてパッケージ化し、エクスポートできます。 .mar ファイルは共有して再利用できます。
- 組み込みモデルハンドラー: 画像分類、オブジェクト検出、テキスト分類、画像セグメンテーションなどの最も一般的なユースケースをカバーするモデル ハンドラーをサポートします。 TorchServe はカスタム ハンドラーもサポートしています。
- ロギングとメトリクス: 推論サービスとエンドポイント、パフォーマンス、リソース使用率、およびエラーを監視するための信頼性の高いロギングとリアルタイム メトリクスをサポートします。カスタム ログを生成し、カスタム メトリクスを定義することもできます。
- モデル管理: 複数のモデルまたは同じモデルの複数のバージョンの同時管理をサポートします。モデル バージョンを使用して、以前のバージョンに戻ったり、A/B テストのためにトラフィックを別のバージョンにルーティングしたりできます。
- 事前に構築されたイメージ: 準備ができたら、T orchServe の Dockerfile と Docker イメージを CPU および NVIDIA GPU ベースの環境にデプロイできます。最新の Dockerfile とイメージはここにあります。
ユーザーは、インストール手順、チュートリアル、ドキュメントを pytorch.org/serve から入手することもできます。
TorchElastic: 統合された K8S コントローラー
RoBERTa や TuringNLG など、現在の機械学習トレーニング モデルはますます大規模になっており、分散クラスターにスケールアウトする必要性がますます重要になっています。このニーズを満たすために、プリエンプティブル インスタンス (Amazon EC2 スポット インスタンスなど) がよく使用されます。
しかし、これらのプリエンプティブル インスタンス自体は予測不可能であるため、2 番目のツールである TorchElastic が登場します。
Kubernetes と TorchElastic の統合により、PyTorch 開発者は一連の計算ノード上で機械学習モデルをトレーニングできるようになります。これらのノードは、モデルのトレーニング プロセスを中断することなく動的に変更できます。
ノードに障害が発生した場合でも、TorchElastic の組み込みフォールト トレランスにより、ノード レベルでトレーニングを一時停止し、ノードが再び稼働したときにトレーニングを再開できます。
さらに、TorchElastic で Kubernetes コントローラーを使用すると、ハードウェアやノードのリサイクルの問題にもかかわらず、ノードが交換されたクラスター上で分散トレーニングを実行するという重要なタスクが可能になります。
トレーニング タスクは、要求されたリソースの一部を使用して開始でき、停止または再起動することなく、リソースが利用可能になると動的にスケーリングできます。
これらの機能を活用するには、ユーザーは単純なジョブ定義でトレーニング パラメーターを指定するだけで、Kubernetes-TorchElastic パッケージがジョブのライフサイクルを管理します。
以下は、Imagenet トレーニング ジョブの TorchElastic 構成の簡単な例です。
apiVersion: elastic.pytorch.org/v1alpha1kind: ElasticJobmetadata:name: imagenetnamespace: elastic-jobspec:rdzvEndpoint: $ETCD_SERVER_ENDPOINTminReplicas: 1maxReplicas: 2replicaSpecs:Worker:replicas: 2restartPolicy: ExitCodetemplate:apiVersion: v1kind: Podspec:containers:- name: elasticjob-workerimage: torchelastic/examples:0.2.0rc1imagePullPolicy: Alwaysargs:- "--nproc_per_node=1"- "/workspace/examples/imagenet/main.py"- "--arch=resnet18"- "--epochs=20"- "--batch-size=32"
マイクロソフトさん、グーグルさん、パニックになっていませんか?
新しい PyTorch ライブラリを立ち上げるための両社の協力には、その背後に深い意味があるかもしれません。なぜなら、フレームワーク モデルの開発の歴史の中で、「プレイに連れて行かない」ルーチンが登場したのはこれが初めてではないからです。
2017 年 12 月、AWS、Facebook、Microsoft は本番環境向けの ONNX を共同開発すると発表しました。これは、産業用途における Google の TensorFlow 独占に対抗するために使用されます。
その後、Apache MXNet、Caffe2、PyTorch などの主流のディープ ラーニング フレームワークは、ONNX に対するさまざまな程度のサポートを実装し、異なるフレームワーク間でのアルゴリズムとモデルの移行を容易にしました。

学術界と産業界を結び付けるという ONNX のビジョンは、実際には当初の期待を満たしていませんでした。基本的に、各フレームワークは依然として独自のサービス システムを使用しています。
そして今、PyTorchが独自のサービス体系を立ち上げ、ONNXは存在意義を失いかけた(MXNetは途方に暮れていたという)。
一方、PyTorch はフレームワークの互換性と使いやすさを向上させるために継続的にアップグレードおよび更新されています。最強の敵である TensorFlow に近づいているか、追いつきつつあります。
Google は独自のクラウド サービスとフレームワークを持っていますが、AWS のクラウド リソースと Facebook のフレームワーク システムの組み合わせにより、Google が抵抗することが難しくなる可能性があります。
そして Microsoft は、元 ONNX トリオの友人 2 人によってグループ チャットから追い出されました。次に何をすればよいかわかりません。
- 以上 -








