Command Palette
Search for a command to run...
このアマチュア エンジニアのグループは中国の NLP を大きく前進させました

NLP (自然言語処理) を勉強したことがある方なら、中国語の NLP がいかに難しいかわかるだろうと誰かが言っていました。
どちらもNLPに属しますが、英語と中国語の分野では言語習慣の違いにより、両者の分析や処理には大きな違いがあり、難しさや課題も異なります。

さらに、現在人気のあるモデルのほとんどは英語用に開発されており、中国語の独特の習慣と相まって、多くのタスク (単語の分割など) が非常に難しく、その結果、中国語 NLP の分野での進歩が非常に遅れています。
しかし、昨年以来、多くの優れたオープンソースプロジェクトが次々に登場し、中国のNLP分野の発展を大きく促進したため、この種の問題はすぐに変わるかもしれません。
モデル: 事前訓練を受けた中国人 ALBERT
2018 年に、Google は Transformers の言語モデル BERT (双方向エンコーダー表現) を発表しました。その非常に強力なパフォーマンスのため、リリースされるとすぐに多くの NLP 標準のリストのトップとなり、すぐに正規化されました。
しかし、BERT の欠点の 1 つは、BERT-large には 3 億個のパラメータがあり、トレーニングが非常に難しいことです。 2019 年、Google AI は軽量の ALBERT (A Little BERT) を発表しました。これは BERT モデルよりもパラメータが 18 倍小さいにもかかわらず、パフォーマンスはそれを上回っています。
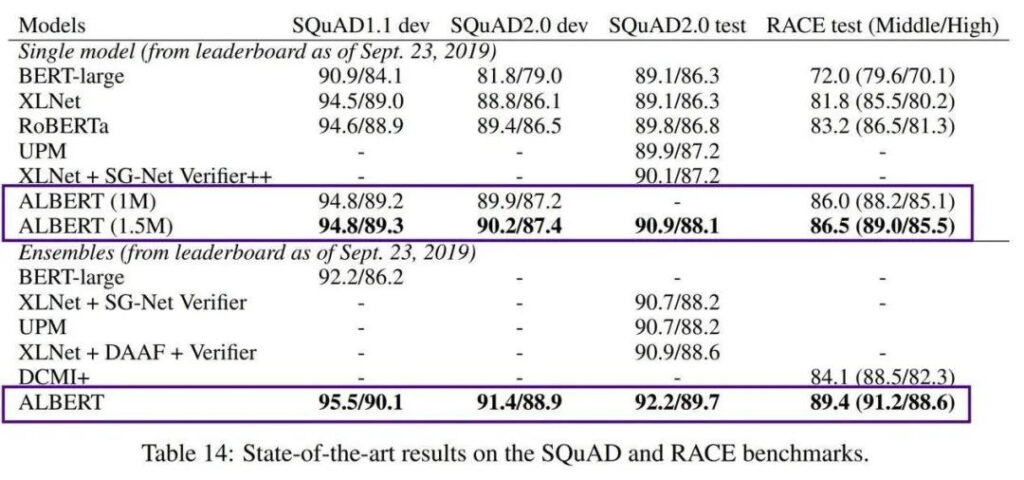
AlBERT は、高い学習コストと事前学習済みモデルの膨大なパラメータ量の問題を解決していますが、依然として英語のコンテキストのみを対象としているため、中国語の開発に注力しているエンジニアは無力感を感じています。
このモデルを中国のコンテキストで使用できるようにし、より多くの開発者に利益をもたらすために、データ エンジニアの Xu Liang のチームは、2019 年 10 月に最初の中国の事前トレーニング済み中国語バージョンの ALBERT モデルをオープンソース化しました。
プロジェクトアドレス
https://github.com/brightmart/albert_zh
この中国語の事前トレーニング済み ALBERT モデル (albert_zh と表記) は、10 億を超える中国語の文字を含む 30G の中国語コーパスを含む、複数の百科事典、ニュース、インタラクティブ コミュニティから取得されています。
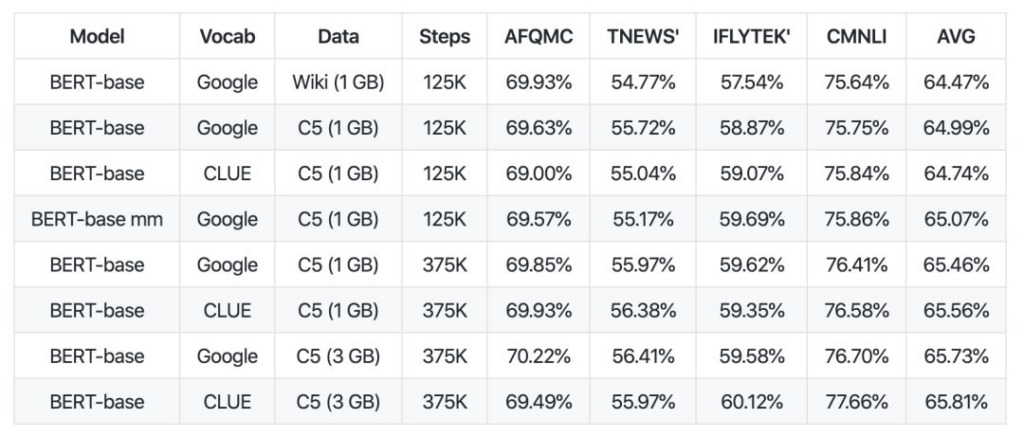
データの比較から、albert_zh の事前トレーニング シーケンスの長さは 512 に設定され、バッチは 4096 で、トレーニングによって 3 億 5,000 万のトレーニング データが生成されますが、別の強力な事前トレーニング モデル roberta_zh の場合、事前トレーニングでは 2 億 5,000 万のトレーニングが生成されます。データの長さは 256 です。
albert_zh 事前トレーニングは、より多くのトレーニング データを生成し、より長いシーケンス長を使用します。albert_zh は roberta_zh よりも優れたパフォーマンスを発揮し、長いテキストをより適切に処理できることが期待されます。
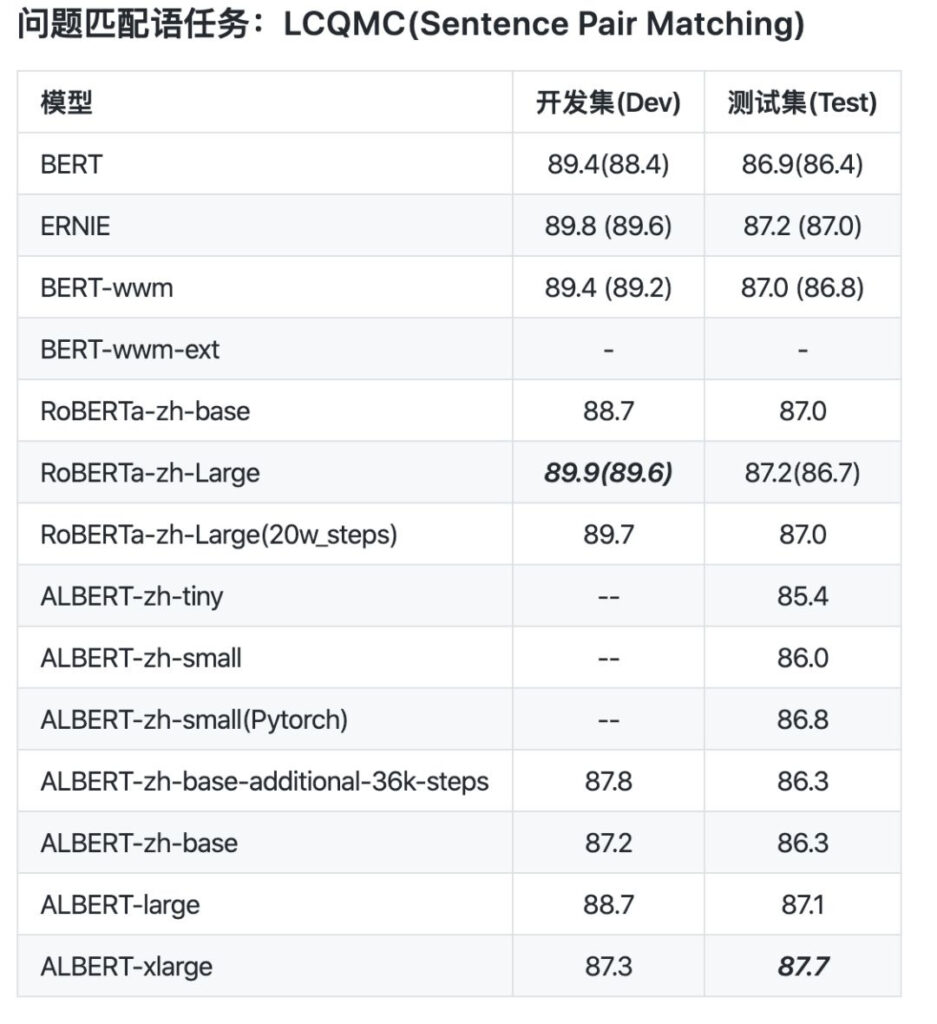
さらに、albert_zh は、tiny バージョンから xlarge バージョンまで、さまざまなパラメーター サイズで一連の ALBERT モデルをトレーニングしました。これにより、中国語 NLP 分野での ALBERT の人気が大幅に高まりました。
2020 年 1 月に Google AI が ALBERT V2 をリリースし、その後、ALBERT の Google 中国語版をゆっくりとリリースしたことは注目に値します。
ベンチマーク: ChineseGLUE (中国語 GLUE 用)
モデルができたら、それが良いか悪いかをどのように判断しますか?これには十分なテスト ベンチマークが必要です。また、昨年、中国語 NLP のベンチマーク テストである ChineseGLUE もオープンソース化されました。
ChineseGLUE は、業界でよく知られたテスト ベンチマークである GLUE を利用しています。GLUE は、9 つの英語理解タスクを集めたもので、一般的で堅牢な自然言語理解システムの研究を促進することです。
以前は、GLUE に対応する中国語版がなく、さまざまなタスクに関する一部の事前トレーニング済みモデルの公開テストを評価できず、その結果、中国分野での NLP の開発と適用にずれが生じ、さらには技術的な遅れさえ生じていました。応用。
この状況に直面して、AlBERT の最初の著者である Lan Zhenzhong 博士と albert_zh の開発者である Xu Liang を含む 20 人以上のエンジニアが共同で中国語 NLP のベンチマークである ChineseGLUE を立ち上げました。
プロジェクトアドレス
https://github.com/chineseGLUE/chineseGLUE
ChineseGLUE の登場により、新しいモデルの評価指標として中国語を含めることが可能になり、中国語の事前トレーニング モデルのテストのための完全な評価システムが形成されました。
この強力なテスト ベンチマークには次の側面が含まれます。
1) 複数の文または文のペアを含む中国語タスクのベンチマーク テスト。さまざまなレベルの複数の言語タスクをカバーします。
2) 性能評価のためのランキングリストを提供します。ランキングリストはモデル選択の基準として定期的に更新されます。
3) 開始コードと事前トレーニング済みモデルの ChineseGLUE タスクのベンチマークを含む、いくつかのベンチマーク モデルを収集しました。これらのベンチマークは、TensorFlow、PyTorch、Keras およびその他のフレームワークで利用できます。
4) 事前学習や言語モデリング研究用の膨大なオリジナルコーパスがあり、その量は約10G(2019年)に達しており、2020年末までに十分なオリジナルコーパス(100Gなど)に拡張する予定です。
ChineseGLUE の立ち上げと継続的な改善により、GLUE が BERT の出現を目撃したのと同じように、より強力な中国語 NLP モデルの誕生を目撃することが期待されます。
2019 年 12 月末と 11 月に、プロジェクトはより包括的で技術的にサポートされたプロジェクト CLUEbenchmark/CLUE に移行されました。
プロジェクトアドレス
https://github.com/CLUEbenchmark/CLUE
データ: 史上最も完全なデータセットと最大のコーパス
事前トレーニングされたモデルとテスト ベンチマークでは、データ セットやコーパスなどのデータ リソースにもう 1 つの重要なリンクがあります。
これにより、CLUE は中国語 GLUE の略称であり、タスクとデータ セット、事前トレーニングされた中国語モデルに重点を置いた評価ベンチマークを提供します。 、コーパスおよびリーダーボードのリリース。
少し前に、CLUE は、10 の主要カテゴリの 142 のデータ セットをカバーする、最大かつ最も完全な中国語 NLP データ セットである CLUEDatasetSearch をリリースしました。

プロジェクトアドレス
https://github.com/CLUEbenchmark/CLUEDatasetSearch
その内容には、NER、QA、センチメント分析、テキスト分類、テキスト配布、テキスト要約、機械翻訳、ナレッジグラフ、コーパス、読解など、現在の研究の主要な方向性がすべて含まれています。
キーワードやWebページ上のフィールドなどの情報を入力するだけで、該当するリソースを検索できます。各データ セットには、名前、更新時間、プロバイダー、説明、キーワード、カテゴリ、用紙アドレスなどの情報が含まれます。
最近、CLUE 組織は 100 GB の中国語コーパスと高品質の中国語事前トレーニング モデルのコレクションを相次いでオープンソース化し、arViv に論文を提出しました。

コーパスに関しては、CLUE は CLUECorpus2020: Large-scale Pre-training Corpus for Chinese 100G 中国語事前トレーニング コーパスをオープンソース化しました。
これらのコンテンツは、Common Crawl データ セットの中国語部分のコーパス クリーニング後に取得されたデータです。
これらは、事前トレーニング、言語モデル、または言語生成タスクに直接使用したり、中国語 NLP タスク専用の小さな語彙を公開したりできます。
プロジェクトアドレス
https://github.com/CLUEbenchmark/CLUECorpus2020
モデル コレクションに関しては、CLUEPretrainedModels がリリースされました。これは、高品質の中国の事前トレーニング済みモデル (最先端の大型モデル、最速の小型モデル、および特殊な類似性モデル) のコレクションです。
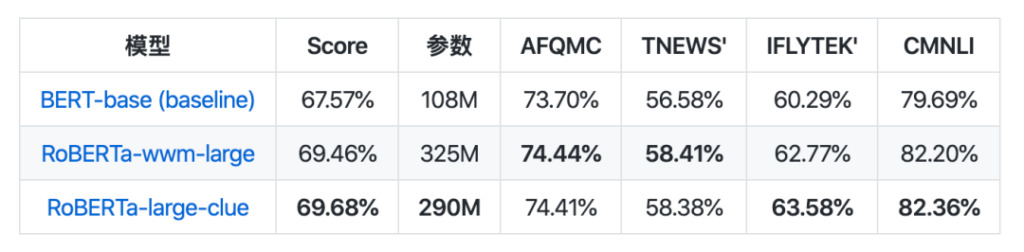
その中で、大規模モデルは現在最高の中国語 NLP モデルと同じ効果を達成し、一部のタスクでは勝利します。意味的類似性または文を処理するために使用される意味的類似性モデルよりも小規模なモデルが約 8 倍高速です。ペアの問題では、事前トレーニングされたモデルを直接使用するよりも優れている可能性が高くなります。
プロジェクトアドレス
https://github.com/CLUEbenchmark/CLUEPretrainedModels
これらのリソースの解放は、ある程度、開発プロセスを促進するための燃料のようなものであり、十分なリソースがあれば、中国の NLP 業界の急速な発展が始まる可能性があります。
中国語の NLP を簡単にします
言語の観点から見ると、中国語と英語は世界で最も話者が多く影響力のある 2 つの言語ですが、言語の特性が異なるため、NLP 分野の研究も異なる問題に直面しています。
中国語 NLP の開発は、機械によってよりよく理解できる英語の研究に比べて確かに困難で遅れていますが、それはまさに、この記事に登場するエンジニアが中国語 NLP の開発を促進し、探求を続ける意欲があるからです。結果を共有することによってのみ、これらのテクノロジーをより適切に反復することができます。
彼らの努力と、数多くの高品質なプロジェクトに貢献してくれてありがとう!同時に、より多くの人々が参加し、共同で中国語 NLP の発展を促進できることを願っています。
- 以上 -








