Command Palette
Search for a command to run...
MV-MATH 数学的推論注釈データセット
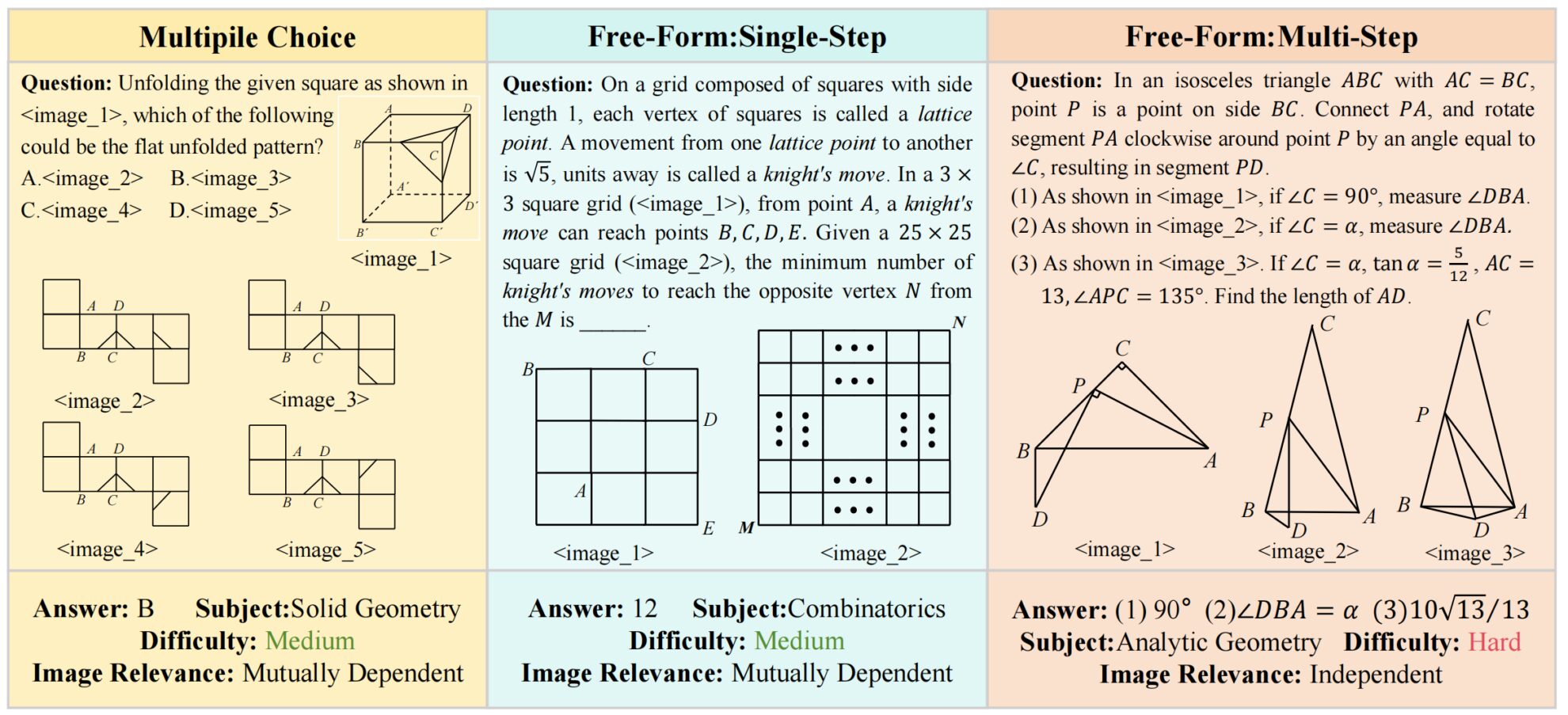
MV-MATH は、2025 年に中国科学院自動化研究所によって提案されたマルチモーダル数学的推論ベンチマーク データセットです。マルチビジュアル シーンにおけるマルチモーダル大規模言語モデル (MLLM) の数学的推論能力を総合的に評価することを目的としています。MV-MATH: マルチビジュアルコンテキストにおけるマルチモーダル数学推論の評価」がCVPR 2025に採択されました。 MV-MATH データセットには、複数選択問題、空欄補充問題、複数ステップのクイズ問題の 3 つのタイプに分かれた 2,009 個の高品質な数学問題が含まれています。データセットには複数の視覚シーンが含まれており、各質問には 2 ~ 8 枚の画像が用意されています。これらの画像はテキストと絡み合って複雑なマルチビジュアルシーンを形成しており、現実世界の数学的問題に近いため、マルチビジュアル情報を処理するモデルの推論能力を効果的に評価できます。第二に、データセットには豊富な注釈が付けられています。各サンプルは、少なくとも 2 人の注釈者によって相互検証されています。注釈には、質問、回答、詳細な分析、画像の関連性が含まれており、モデル評価のための詳細な情報を提供します。さらに、データセットは、解析幾何学、代数、計量幾何学、組合せ論、変換幾何学、論理、立体幾何学、算術、組合せ幾何学、記述幾何学、統計など、基本的な算術から高度な幾何学までの 11 の数学分野をカバーしています。また、データセットは詳細な回答の長さに基づいて 3 つの難易度レベルに分割されており、さまざまな数学分野におけるモデルの推論能力を総合的に評価できます。このデータセットでは、画像相関の特徴ラベルが初めて導入され、データセットが相互依存セット (MD) と独立セット (ID) の 2 つのサブセットに分割されていることは注目に値します。 MD サブセットでは、画像は相互に関連しており、1 つの画像を理解するには他の画像を参照する必要があります。一方、ID サブセットでは、画像は独立しており、個別に解釈できます。 これは実際の K-12 教育のシナリオから生まれたものであり、グラフィックスとテキストの組み合わせを通じて学生が複雑な数学の問題を解くのに役立つインテリジェントな指導システムの開発に使用できるだけでなく、マルチモーダル学習研究のための標準化された評価ツールも提供し、研究者が数学的推論のモデルのパフォーマンスギャップを特定して改善するのに役立ちます。しかし、GPT-4oやQvQなどの主流のマルチモーダル大規模言語モデルのテストでは、MV-MATHデータセットのスコアはそれぞれ32.1と29.3で、どちらも合格ラインを下回っており、現在のマルチモーダル大規模モデルは、マルチビジュアル数学的推論タスクにおいて依然として大きな課題に直面していることを示しています。