Command Palette
Search for a command to run...
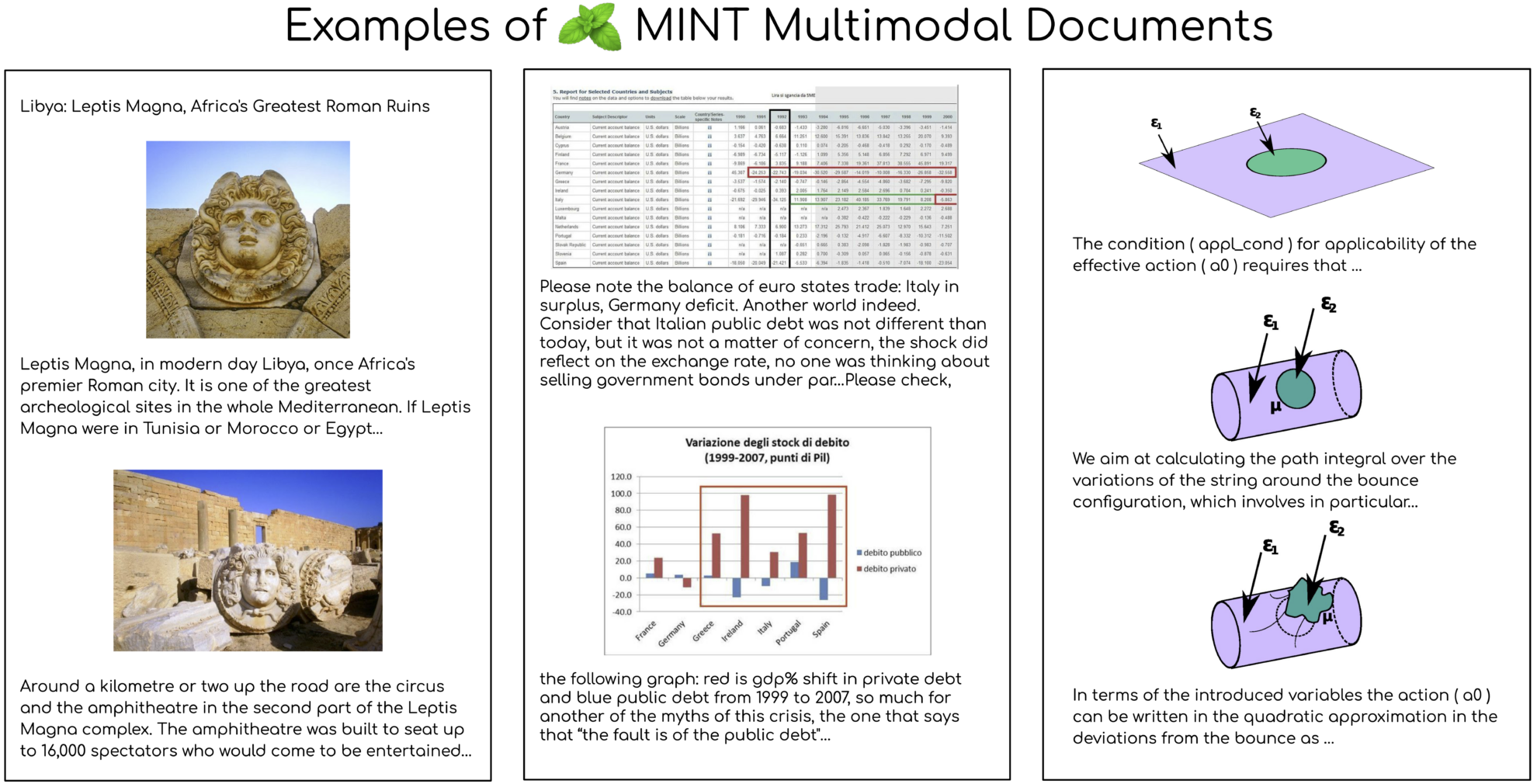
MINT-1T テキストと画像のペアのマルチモーダル データセット
MINT-1T データセットは、Salesforce AI と複数の機関が共同で 2024 年にオープンソース化したマルチモーダル データセットです。その規模は大幅に拡大し、1 兆のテキストタグと 34 億の画像に達しました。この規模は 10 倍です。これまで最大のオープン ソース データ セット、および関連する論文の結果は次のとおりです。MINT-1T: オープンソースのマルチモーダル データを 10 倍に拡張: 1 兆のトークンを含むマルチモーダル データセット”。このデータセットの構築は、規模と多様性の基本原則に従っており、HTML ドキュメントだけでなく、PDF ドキュメントや ArXiv 論文も含まれており、この多様性により科学ドキュメントの範囲が大幅に向上します。 MINT-1T のデータ ソースは、これまでマルチモーダル データセットでは十分に活用されていなかった Web ページ、学術論文、ドキュメントなどを含むがこれらに限定されない多様なものです。
モデル実験に関しては、MINT-1T で事前トレーニングされた XGen-MM マルチモーダル モデルは、画像キャプションと視覚的な質問応答ベンチマークで優れたパフォーマンスを示し、以前の主要なデータセット OBELICS を上回りました。分析を通じて、MINT-1T はサイズ、データ ソースの多様性、品質が大幅に向上しました。特に、平均で大幅に長く、画像密度が高い PDF および ArXiv ドキュメントで顕著です。さらに、LDA モデルによるドキュメントのトピック モデリングの結果は、MINT-1T の HTML サブセットがより広い領域をカバーしているのに対し、PDF サブセットは主に科学および技術分野に集中していることを示しています。
MINT-1T は、特に科学技術分野での ArXiv および PDF ドキュメントの人気のおかげで、複数のタスクで優れたパフォーマンスを示しています。さまざまな数のサンプルを使用した場合のモデルのコンテキスト学習パフォーマンスを評価すると、MINT-1T でトレーニングされたモデルは、すべてのサンプル数でベースライン モデル OBELICS よりも優れています。 MINT-1T のリリースは、研究者や開発者に膨大なマルチモーダル データ セットを提供するだけでなく、マルチモーダル モデルのトレーニングと評価に対する新たな課題と機会も提供します。