Command Palette
Search for a command to run...
GMAI-MMBench 医療複合評価ベンチマーク データセット
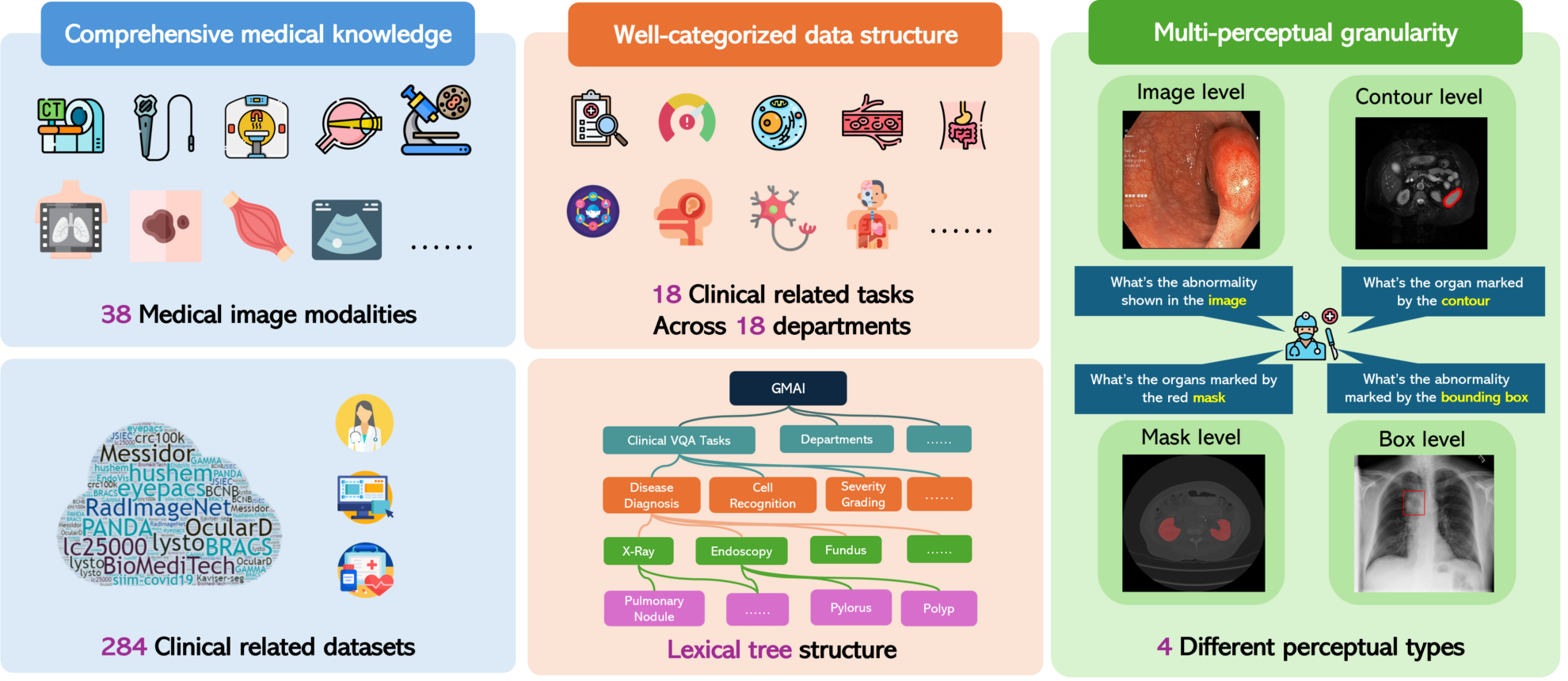
GMAI-MMBench は、一般医療人工知能分野の開発を促進するために設計されたマルチモーダル評価ベンチマークであり、上海人工知能研究所、ワシントン大学、モナシュ大学、華東師範大学、ケンブリッジ大学、上海の専門家で構成されています。交通大学、香港中文大学(深セン)、深センビッグデータ研究所、中国科学院の9機関深セン先進技術研究所が共同で2024年に開始する予定で、関連する論文結果は「GMAI-MMBench: 一般医療 AI に向けた包括的なマルチモーダル評価ベンチマーク”。研究者や開発者が医療分野における大規模視覚言語モデル (LVLM) の適用効果を深く理解し、包括的かつ詳細な評価を提供することで技術的な欠点を特定するのに役立ちます。このベンチマークは、18 の異なる診療科をカバーする 38 の医療画像モダリティと 18 の臨床関連タスクを含む、さまざまなソースからの 284 のデータセットを含む幅広いデータセットをカバーし、複数の LVLM のパフォーマンスを考慮するために 4 つの異なる知覚粒度で評価されました。寸法。 GMAI-MMBenchの特徴は、多感覚の粒度を評価することであり、画像全体レベルの評価だけでなく、領域レベルまで深く踏み込み、より詳細かつ包括的な評価の視点を提供します。さらに、データセットは主に病院から提供され、専門の医師によって注釈が付けられているため、GMAI-MMBench の評価タスクは実際の臨床シナリオに近く、臨床関連性が高くなります。この相関関係により、ベンチマーク結果は実際の医療用途にとって有益になります。 GMAI-MMBench では、語彙ツリー構造を実装することで評価タスクをカスタマイズすることもでき、ユーザーは独自のニーズに応じて評価タスクを定義できるため、医療 AI の研究とアプリケーションに柔軟性が提供されます。研究チームは、一部の先進的な GPT-4o モデルを含む 50 の LVLM を評価したところ、医療専門家の問題への対処では、最も先進的なモデルでも 52% の精度しか達成できていないことがわかりました。これは、現在の LVLM が医療分野でほとんど応用されていないことを示しています。改善の余地はまだたくさんあります。 GMAI-MMBench の開発は、医療分野における LVLM の応用を評価および改善するための貴重なリソースを提供し、現在の技術が直面している課題を明らかにし、将来の研究の方向性を示します。