Command Palette
Search for a command to run...
MMedC 大規模多言語医療コーパス
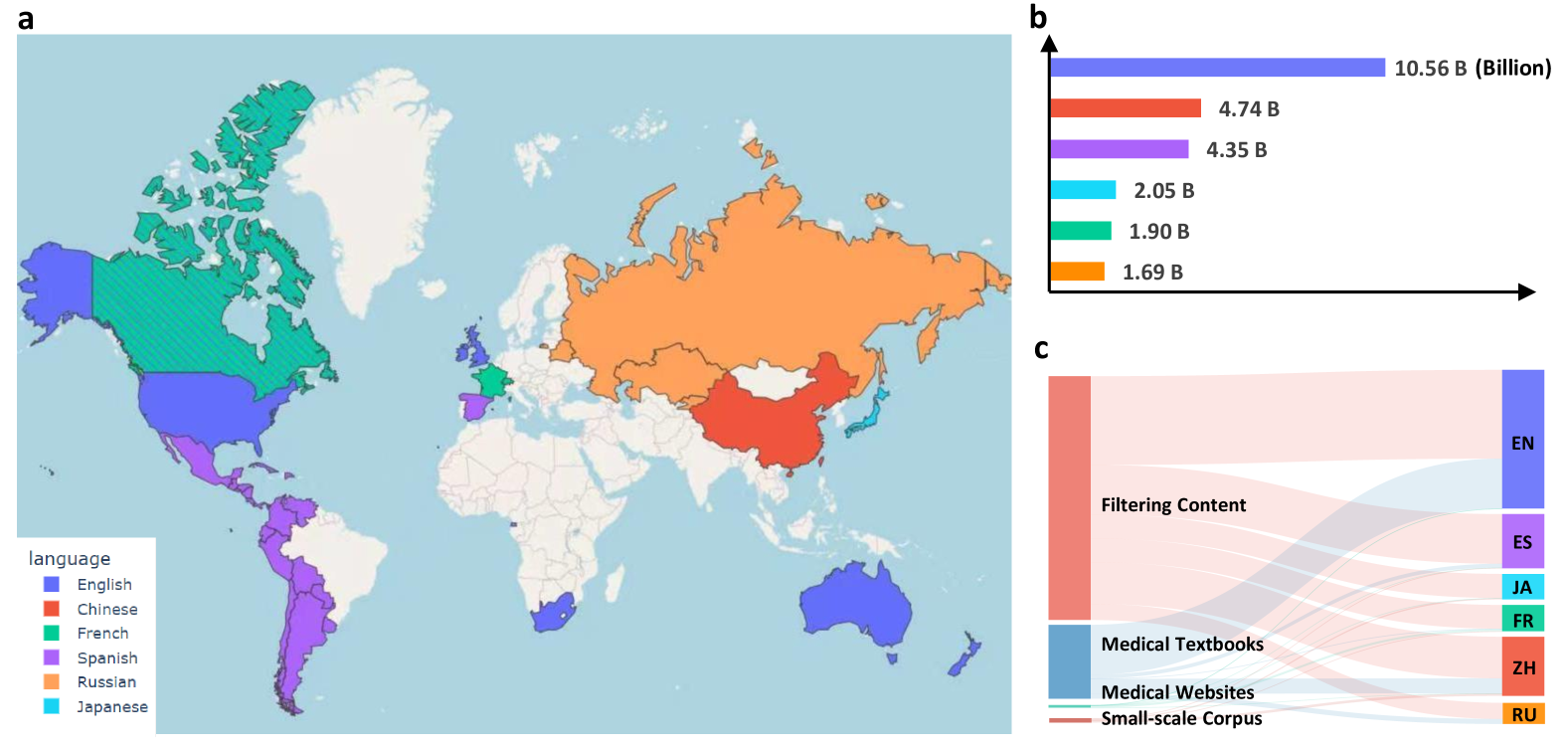
大規模多言語医療コーパス (MMedC) は、2024 年に上海交通大学人工知能学部のスマート医療チームによって構築された多言語医療コーパスです。これには、英語、中国語、日本語、フランス語、ロシア語、スペイン語。このデータセットは、世界の大部分をカバーする多言語医療のための大規模な言語モデルの開発を進めるために構築されており、さらに多くの言語のサポートが現在も更新および拡張されています。関連する論文結果は「医療用の多言語言語モデルの構築に向けて』が『nature communication』に掲載されました。 MMedC のデータ ソースには主に 4 つの側面が含まれます。1 つは、ヒューリスティック アルゴリズムを使用して大規模な一般テキスト データベース (CommonCrawl など) から医療関連コンテンツを除外することです。2 つ目は、光学式文字認識テクノロジ (OCR) を使用して医療データからテキストを抽出することです。次に、多くの国で正式に認可された医療 Web サイトからデータがクロールされ、最後に、いくつかの既存の小規模な医療データ セットが統合されました。 さらに、医療分野における多言語モデルの開発を評価するために、研究チームはMMedBenchという名前の新しい多言語多肢選択式質問と回答の評価基準も設計しました。 MMedBench のすべての質問は、単純に翻訳を通じて入手したものではなく、さまざまな国の医療検査質問バンクから直接得られたものであるため、各国の医療行為ガイドラインの違いによって引き起こされる診断上の理解の逸脱が回避されます。評価プロセス中、モデルは正しい答えを選択するだけでなく、合理的な説明も提供する必要があります。これにより、複雑な医療情報を理解して解釈し、より包括的な評価を達成するモデルの能力がさらにテストされます。 研究チームはまた、多言語医療ベースモデル MMed-Llama 3 をオープンソース化しました。これは、複数のベンチマーク テストで良好なパフォーマンスを示し、既存のオープンソース モデルを大幅に上回り、医療垂直分野でのカスタマイズされた微調整に特に適しています。すべてのデータとコードはオープンソースであり、世界的な研究コミュニティ間でのコラボレーションとテクノロジーの共有がさらに促進されます。 MMedC の構築とオープンソースは、多言語医療言語モデルのトレーニングと評価のための豊富で高品質なデータ サポートを提供し、言語の壁と医療リソースのグローバル化の問題の解決に役立ち、医療分野での応用に大きな可能性を示します。