HyperAI
Command Palette
Search for a command to run...
MedTrinity-25M 大規模マルチモーダル医療データセット
このデータセットは、華中科学技術大学、カリフォルニア大学サンタクルーズ校、ハーバード大学、スタンフォード大学の研究チームが共同で2024年に立ち上げた大規模なマルチモーダル医療データセットです。関連する論文結果は「MedTrinity-25M: 医療向けの多粒度アノテーションを備えた大規模マルチモーダル データセット”。
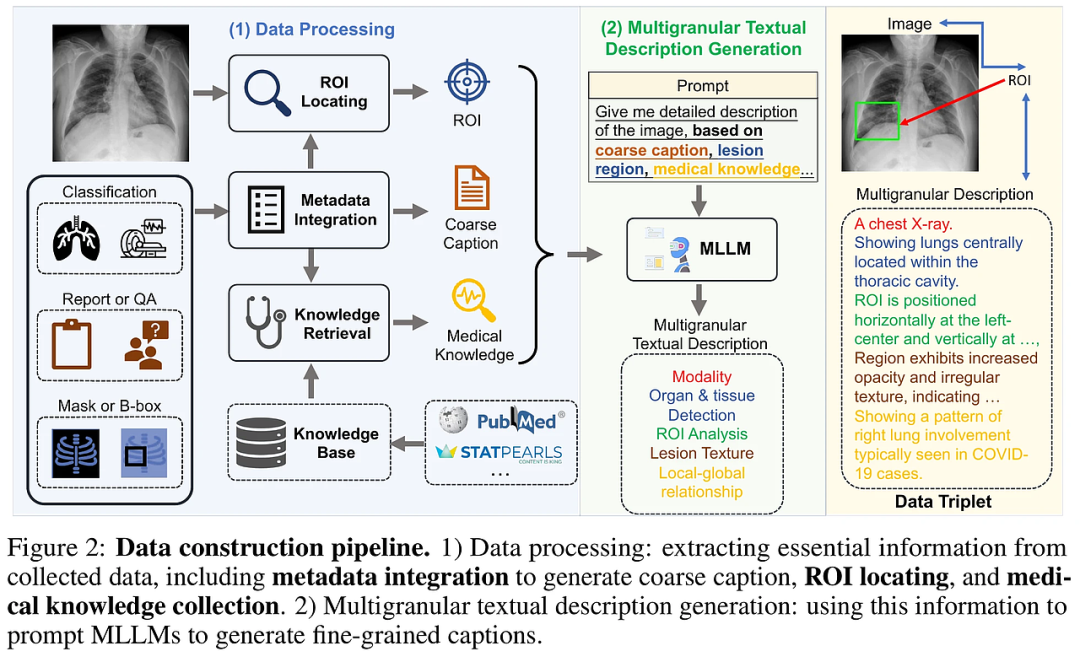
MedTrinity-25M には、10 の画像モダリティをカバーする 2,500 万を超える医療画像が含まれており、65 を超える疾患に注釈が付けられています。このデータ セットには、豊富なグローバルおよびローカル アノテーションが含まれているだけでなく、複数のモダリティ (CT、MRI、X 線など) のマルチレベル情報アノテーションも統合されています。これらの注釈には、疾患または病変の種類、画像診断法、領域固有の説明、臓器間の関係が含まれます。研究チームは、90 を超えるさまざまなソースからのデータを前処理して統合することにより、多層のビジュアルおよびテキストの注釈を生成する独自の自動データ構築プロセスを開発しました。この方法は、画像とテキストのペアに依存する従来の制限を打ち破り、注釈の自動生成を実現します。このデータセットは、医療ベースの人工知能モデルの事前トレーニングを促進しながら、医療画像処理、レポート生成、分類、セグメンテーションなどのマルチモーダル タスクに多大なサポートを提供します。
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。