Command Palette
Search for a command to run...
OceanBench 海洋ベンチマーク評価データセット
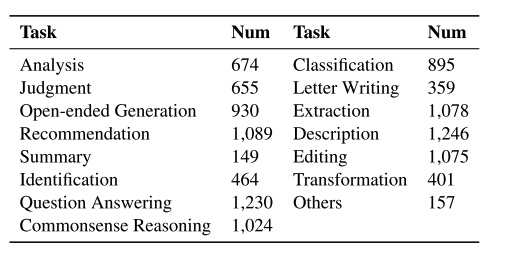
OceanBench は、2024 年に浙江大学の Zhang Ningyu 氏と Chen Huajun 氏のチームによって設計された海洋ミッションに特化して設計されたベンチマーク評価データセットです。このデータセットには、質問応答タスクや説明タスクなど、合計 15 の海洋関連タスクが含まれており、海洋学の分野における大規模言語モデル (LLM) の機能を包括的に評価するように設計されています。 OceanBench のサンプルはシード データ セットから自動的に生成され、データの専門性と正確性を確保するために専門家によって手動で検証されます。 OceanBench は、海洋学の分野で大規模な言語モデルの開発を促進し、標準化されたテスト プラットフォームを提供し、研究者が海洋科学のタスクにおけるモデルの理解を深め、パフォーマンスを向上できるようにするために作成されました。このベンチマークを通じて、研究者は、海洋物理学、海洋化学、海洋生物学、地質学、水文学、その他の分野における質問応答や説明生成タスクを含むがこれらに限定されない、海洋科学のさまざまなサブタスクにおけるモデルの機能を評価できます。 さらに、OceanBench とともに提案されているのは、 OceanInstruct海洋大型モデル命令データセット、これは海洋科学の分野向けに特別に設計された大規模な言語モデルの命令データ セットであり、20,000 の命令が含まれており、海洋分野の大規模な言語モデルのトレーニング データを提供するように設計されています。これらの指示は海洋科学の幅広い知識をカバーしており、モデルが海洋科学の質問と回答、コンテンツ生成、および水中で具現化されたインテリジェンス機能における専門的な機能を備えていることを保証します。このデータ セットは、海洋科学の質問応答やコンテンツ生成で優れたパフォーマンスを発揮する OceanGPT モデルのトレーニングに使用されます。