HyperAI
Command Palette
Search for a command to run...
VEGA 科学論文の画像とテキストデータの理解データセット
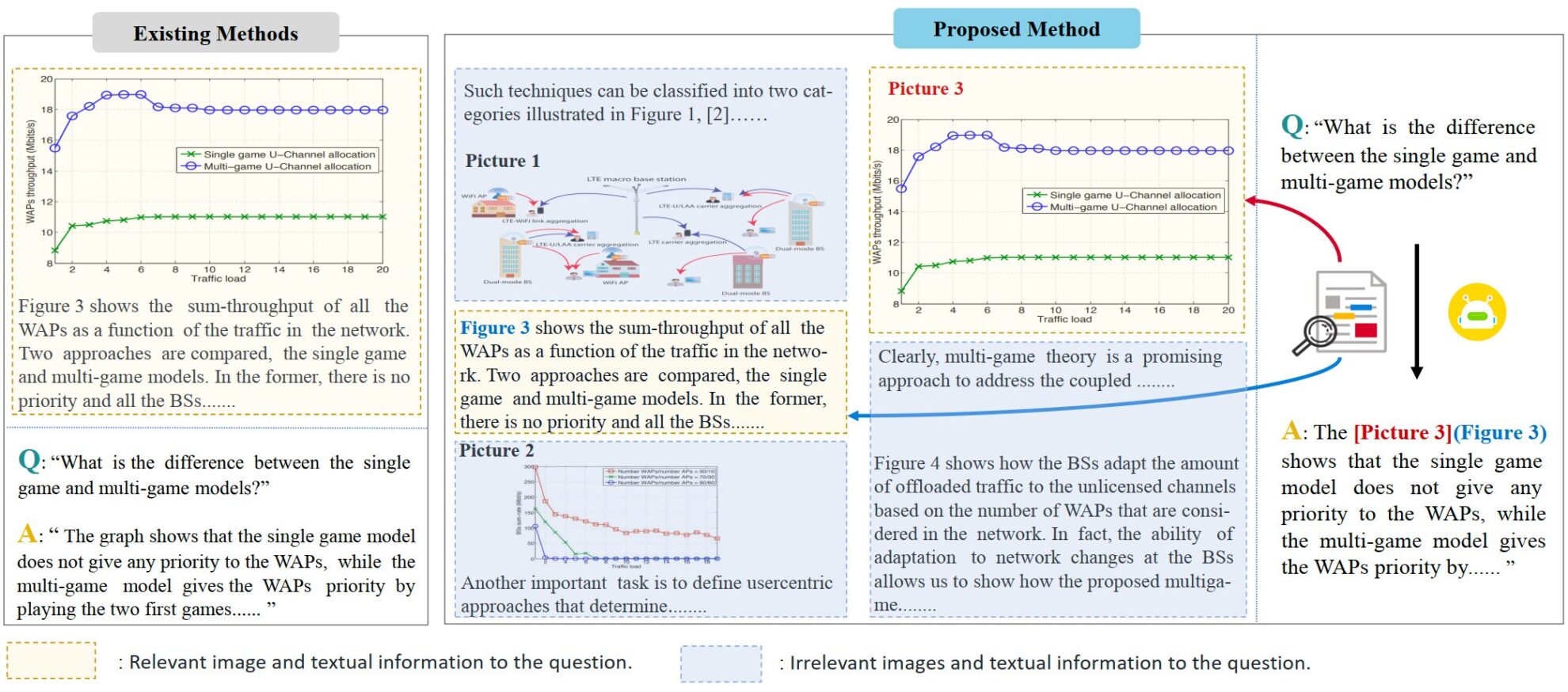
VEGA は、科学論文の理解に焦点を当てたマルチモーダル データ セットで、2024 年にアモイ大学の Ji Rongrong のチームによって提案され、複雑なインターリーブされたグラフィックスとテキスト情報を含む入力を処理する際のモデルのパフォーマンスを評価および改善するように設計されています。 、関連論文は「VEGA: 視覚言語の大規模モデルにおけるインターリーブされた画像とテキストの理解の学習”。このデータ セットには、50,000 を超える科学論文の画像およびテキスト データが含まれており、Interleaved Image-Text Comprehension (IITC) タスク用に特別に構築されています。 VEGA データセットの構築プロセスには、質問のスクリーニング、コンテキストの構築、回答の修正という 3 つのステップが含まれます。これは、より長く複雑なインターレース画像とテキストのコンテンツを入力として提供するように設計されており、回答時にモデルが参照画像を示す必要があります。 VEGA は、紙の画像理解タスク用のデータセットである SciGraphQA データセットに基づいて、研究チームは質問のスクリーニング、コンテキストの構築、および回答の修正の 3 つのステップを実行して、 VEGA データセット。これには、2 つの異なるタスクからの 593,000 個の紙タイプのトレーニング データと 2,326 個のテスト データが含まれており、より長く複雑なインターレース画像とテキスト コンテンツを入力として提供するように設計されており、モデルは回答時に参照画像を示す必要があります。
- 質問のスクリーニング: 元のデータセットの一部の質問には明確な画像の指示が欠けており、入力情報が複数の画像に拡張されると理解に混乱が生じます。
- コンテキストの構築: 元のデータ セット内の質問と回答は 1 つの画像のみに焦点を当てており、提供されるコンテキスト情報は少なくなります。テキストと画像の数を増やすために、研究チームは arxiv で関連論文のソース ファイルをダウンロードし、4k トークンと 8k トークンの 2 つの長さのデータを構築しました。各質問と回答のペアには最大 8 枚の画像が含まれています。
- 回答の変更: 作成者は、IITC タスクの要件を満たすために、元のデータ セット内の回答を変更し、回答時に参照される画像を指定しました。
VEGA.torrent
シーディング 1ダウンロード中 0完了 220総ダウンロード数 299
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。