Command Palette
Search for a command to run...
MMDU超長マルチ画像マルチターン対話理解データセット
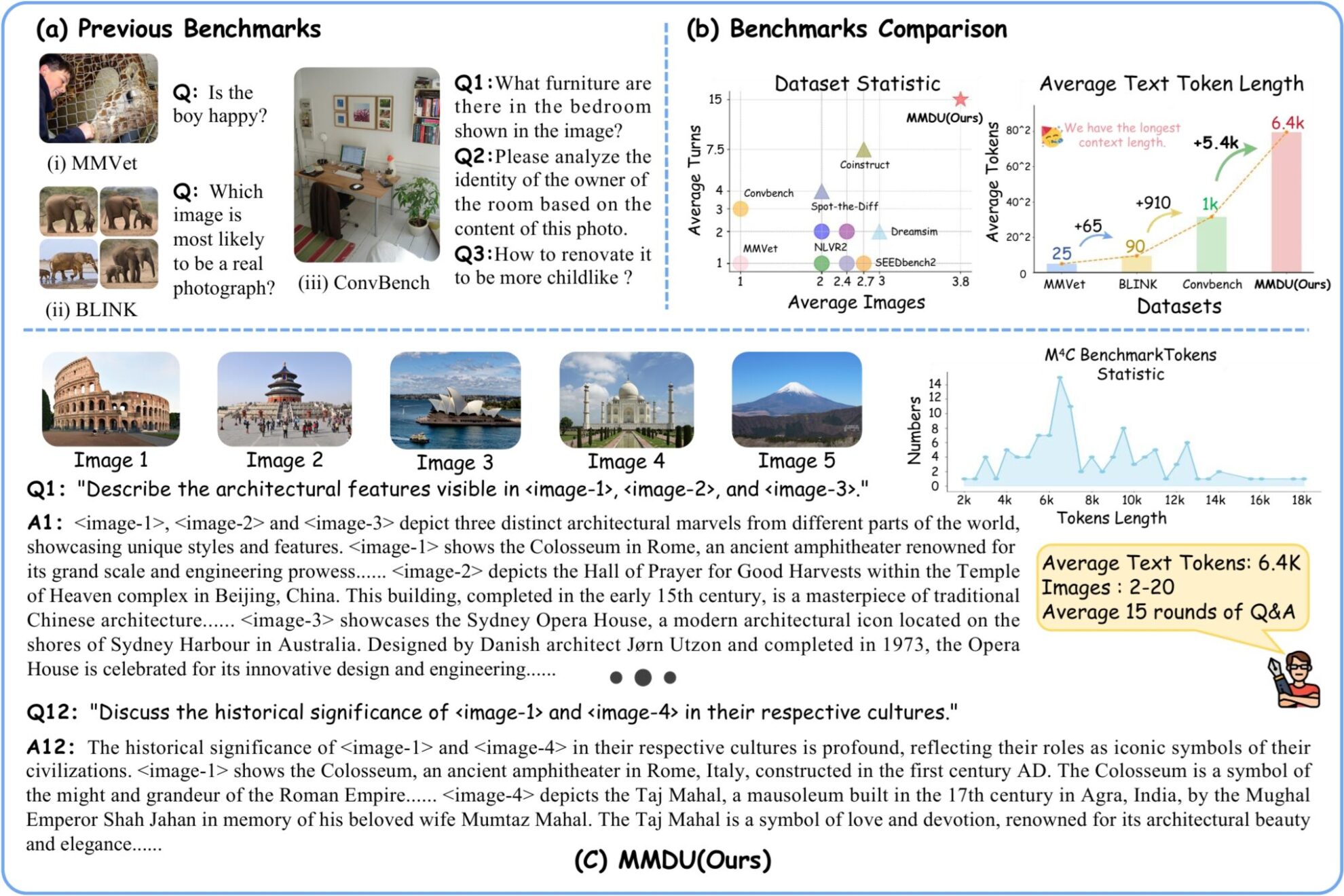
MMDU (Multi-Turn Multi-Image Dialog Understanding) は、武漢大学、上海人工知能研究所、香港中文大学、および Moore Threads が共同で 2024 年に開始した、超長時間のマルチ画像マルチターン対話理解データセットです。論文では「MMDU: LVLM のベンチマークと命令チューニング データセットを理解するマルチターン マルチイメージ ダイアログ」は、マルチラウンドおよびマルチイメージ対話における LVLM のパフォーマンスを評価および改善することを目的として、新しいマルチイメージ マルチラウンド評価ベンチマーク MMDU と大規模命令微調整データセット MMDU-45k を提案しました。 このベンチマークは、1,600 を超える質問を含む 110 の高品質、複数画像、複数ターンの会話で構成されており、それぞれに詳細な長文の回答が付いています。以前のベンチマークでは通常、単一の画像または少数の画像のみが使用され、質問と短い回答が少なくなっていました。ただし、MMDU では、画像の数、Q&A ラウンド、および Q&A コンテキストの長さが大幅に増加します。 MMUD の問題には 2 ~ 20 の画像が関係し、画像とテキストの平均タグ長は 8.2k タグ、画像とテキストの最大長は 18K タグであり、既存のマルチモーダル大規模モデルに重大な課題をもたらします。 MMDU-45k では、研究チームは合計 45k の命令チューニング データ会話を構築しました。 MMDU-45k データ セット内の各データには超長いコンテキストがあり、画像とテキストの平均トークン長は 5k、画像とテキストの最大トークン長は 17k です。各会話には平均 9 ラウンド、最大 27 ラウンドの質問と回答が含まれます。また、各データには写真2~5枚分の内容が含まれております。このデータセットの構築形式は、非常にスケーラブルになるように慎重に設計されており、組み合わせて、より長い複数画像、複数ターンの会話を多数生成できます。 MMDU-45k のグラフの長さとラウンド数は、既存のすべての命令チューニング データセットを大幅に上回っています。この機能強化により、複数の画像認識を理解し、状況に応じた長い会話を処理するモデルの能力が大幅に向上しました。 MMDU ベンチマークには次の利点があります。 **(1) 複数回の対話と複数の画像入力:**MMDU ベンチマーク テストには、最大 20 枚の画像と 27 ラウンドの質疑応答ダイアログが含まれるため、これまでのさまざまなベンチマークを上回り、現実世界のチャット インタラクション シナリオを真に再現します。 **(2) 長い文脈:**MMDU ベンチマークは、最大 18,000 個のテキスト + 画像トークンによる長いコンテキスト履歴を持つコンテキスト情報を処理および理解する LVLM の能力を評価します。 **(3) 公開評価:**MMDU は、従来のベンチマークが依存していたクローズエンドの質問や短い出力 (多肢選択の質問や短い回答など) を取り除き、より現実的で洗練された評価方法を採用し、自由形式の複数のラウンドを通じて LVLM のパフォーマンスを評価します。出力の拡張性と評価結果の解釈可能性を強調します。 MMDU を構築する過程で、研究者はオープンソースの Wikipedia から関連性の高い画像とテキスト情報を選択し、GPT-4o モデルの支援を受けてヒューマン アノテーターが質問と回答のペアを構築しました。