HyperAI
Command Palette
Search for a command to run...
HellaSwag 大規模モデル常識推論データセット
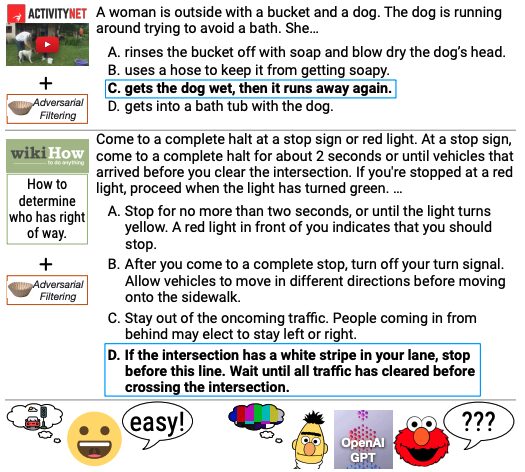
HellaSwag データセットは、常識的な自然言語推論 (commonsense NLI) をテストするための新しいチャレンジ データセットです。ワシントン大学と Allen AI によって 2019 年に開始されたこのデータセットは、既存の最先端モデルに挑戦的なデータセットを構築することで、常識的な推論における深く事前トレーニングされたモデルのパフォーマンスを調査することを目的としています。関連する論文結果」HellaSwag: 機械は本当に文を完成させることができるのでしょうか?「ACL 2019に承認されました。 HellaSwag データセットには 70,000 の問題が含まれており、問題は人間にとっては非常に単純ですが (精度は 95% を超えます)、最も高度なモデルでも人間レベルに近いパフォーマンスを達成するのは困難です (精度は約 48%)。データセットは、敵対的フィルタリング (AF) 手法を通じて構築されます。この手法では、一連の識別子を利用して、機械生成の不正解を繰り返し選択して、データセットの難易度を高めます。 HellaSwag の作成により、事前に深くトレーニングされたモデルの内部動作が明らかになり、NLP 研究に新しい方向性が提供されます。ベンチマークは、より困難なタスクを提供するために、進化する最先端のモデルと敵対的な方法で共進化します。
hellaswag.torrent
シーディング 1ダウンロード中 0完了 218総ダウンロード数 429
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。