HyperAI
Command Palette
Search for a command to run...
AdaTreeFormer-Yoesmite ヨセミテの高解像度樹木検出データセット
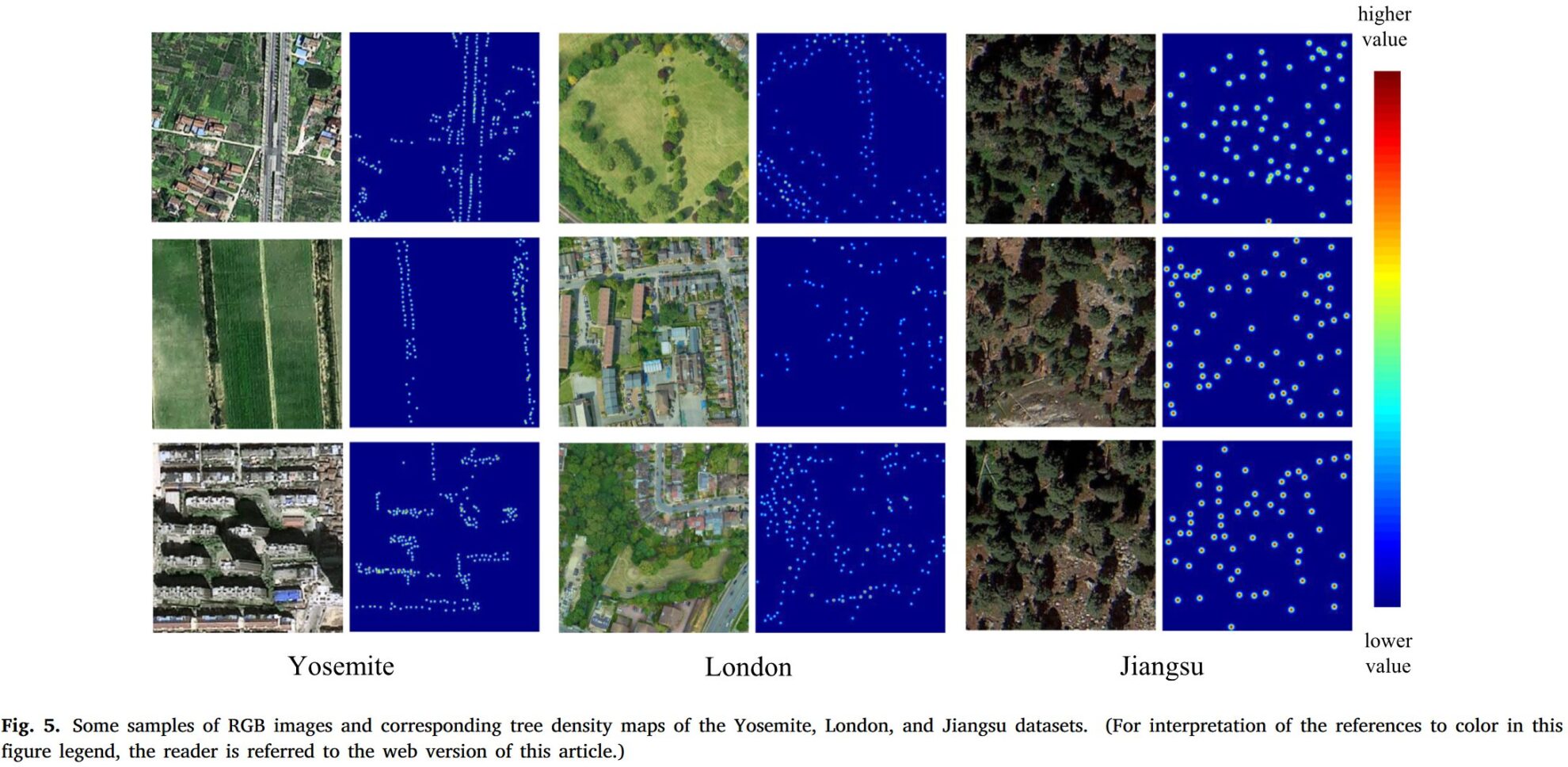
このデータセットは、同済大学とキングス カレッジ ロンドンによって論文「」で開発されました。AdaTreeFormer: 単一の高解像度画像からカウントするツリーの少数ショット ドメイン適応』で提案されました。 この論文には、ロンドン データセット、ヨセミテ データセット、江蘇データセットの 3 つのデータセットが含まれています。 このデータセットは、ロンドンの高解像度樹木検出データセットです。
- 場所: ヨセミテ国立公園、カリフォルニア州、米国
- 景観タイプ: 木質山岳地帯
- 画像あたりの木の平均数: 36
- 木の総数: 98,949
- 画像解像度: 0.12 メートル
- データ分割:トレーニングセット:1350画像、テストセット:1350画像 ヨセミテ データセットは主に、樹木密度が低く複雑な地形の樹木が茂った山岳地帯をカバーしており、複雑な地形でのモデルのパフォーマンスに重要なテスト環境を提供します。
データセットの背景
- 多様な樹木の種類と地形: 樹木の種類、サイズ、形状が異なるだけでなく、地形(都市部、農地、山岳地帯など)も異なるため、樹木のカウントはより複雑になります。
- 高品質のトレーニング データの欠如: 深層学習モデルは多くの場合、大量のラベル付きデータに依存しますが、このデータの取得には費用と時間がかかります。
- ドメイン ギャップの問題: 樹木カウント タスクでは、さまざまなシーン (都市部と農村部など)、さまざまな画像タイプ (航空画像や衛星画像など)、および樹木の密度の違いにより、ソース ドメインとターゲット ドメインの間に大きな違いが生じます。ドメイン。
AdaTreeFormer-Yoesmite.torrent
シーディング 2ダウンロード中 0完了 177総ダウンロード数 298
このデータセットはコミュニティユーザーによって提供されており、教育および情報提供のみを目的としています。著作権侵害に関わるコンテンツがある場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。