Command Palette
Search for a command to run...
Cadre d'optimisation De La Stratégie Hybride HiPO
HiPO (Hybrid Policy Optimization) a été proposé en septembre 2025 par une équipe de recherche de l'Université de Kuaishou et de l'Université de Nanjing. Les résultats de cette recherche ont été publiés dans l'article «HiPO : Optimisation hybride des politiques pour le raisonnement dynamique dans les LLM".
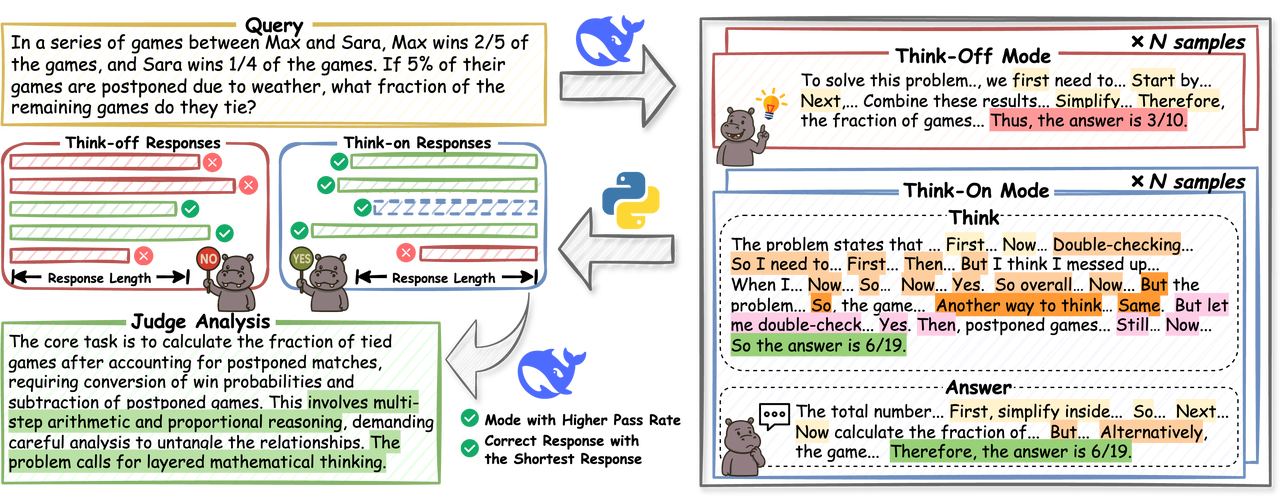
HiPO est un cadre de contrôle adaptatif de l'inférence qui permet aux modèles de langage (LLM) de choisir judicieusement quand effectuer une inférence détaillée (Think-on) et quand fournir des réponses directes (Think-off). Plus précisément, HiPO combine un pipeline de données hybride fournissant des réponses Think-on et Think-off appariées avec un système de récompense d'apprentissage par renforcement hybride. Ce système évite une dépendance excessive à l'inférence détaillée tout en équilibrant précision et efficacité. Des expériences sur des benchmarks mathématiques et de programmation démontrent que HiPO peut réduire significativement la longueur des jetons tout en maintenant, voire en améliorant, la précision.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.