Command Palette
Search for a command to run...
MOSS : Génération De Dialogues texte-parole
Date
Taille
8.4 MB
Balises
Licence
Apache 2.0
GitHub
URL du document
1. Introduction au tutoriel

Ce tutoriel utilise une seule carte RTX 5090 comme ressource.
2. Exemples de projets
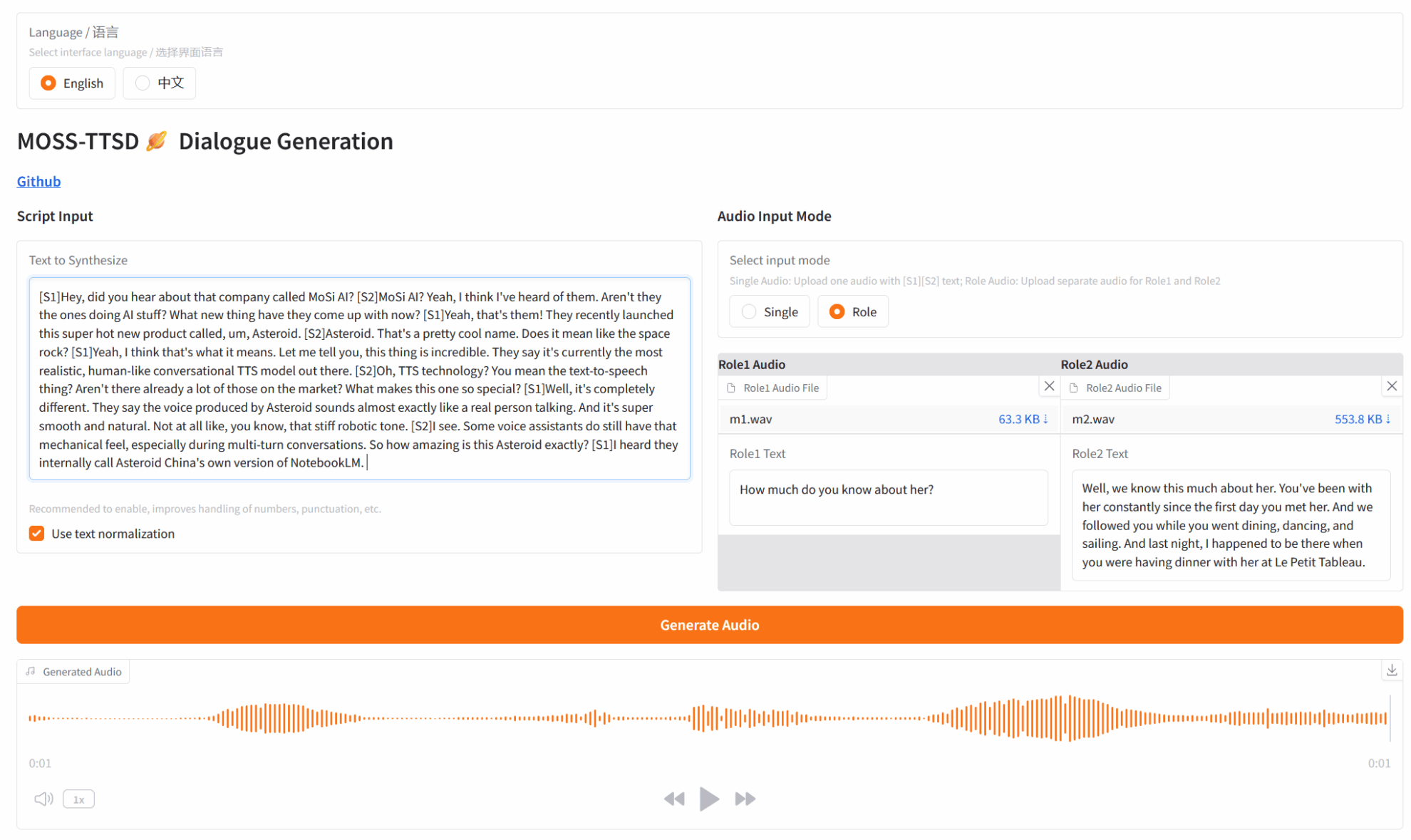
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
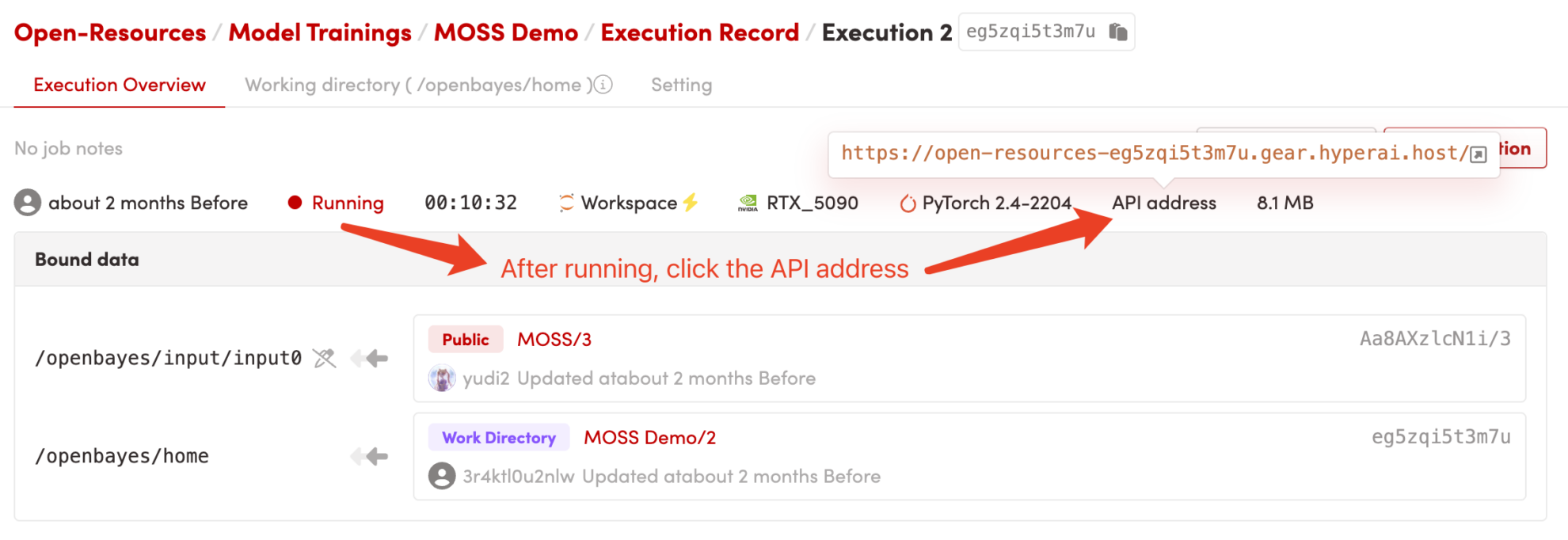
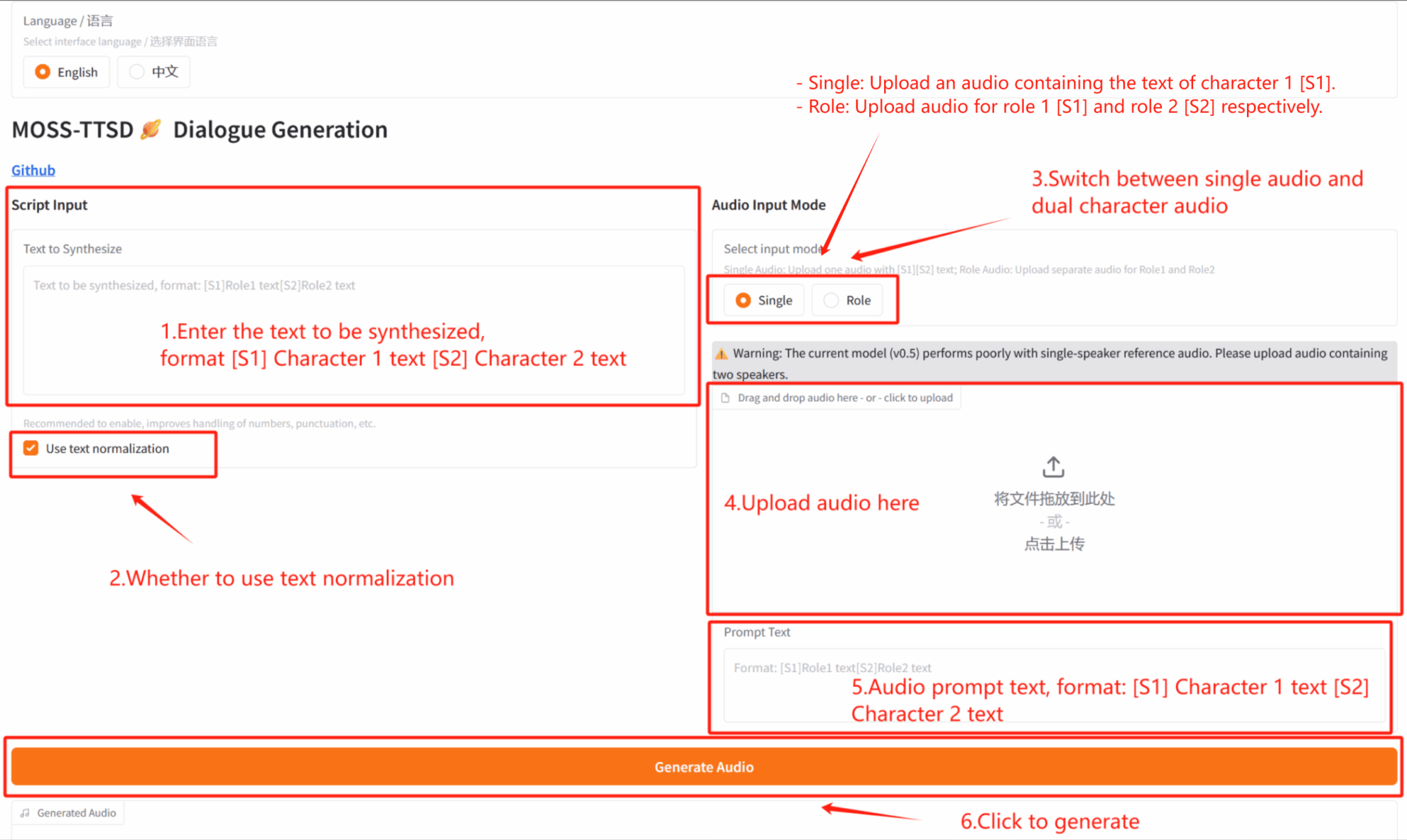
2. Étapes d'utilisation
Si le message « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Le modèle étant volumineux, veuillez patienter 2 à 3 minutes avant d'actualiser la page. Avec Safari, l'audio peut ne pas être lu directement ; il doit être téléchargé avant de pouvoir être lu.
*Ce tutoriel vous permet de choisir entre la génération audio en mode solo (Single) et la génération audio de dialogue à deux joueurs (Role) dans le « Mode d'entrée audio ».
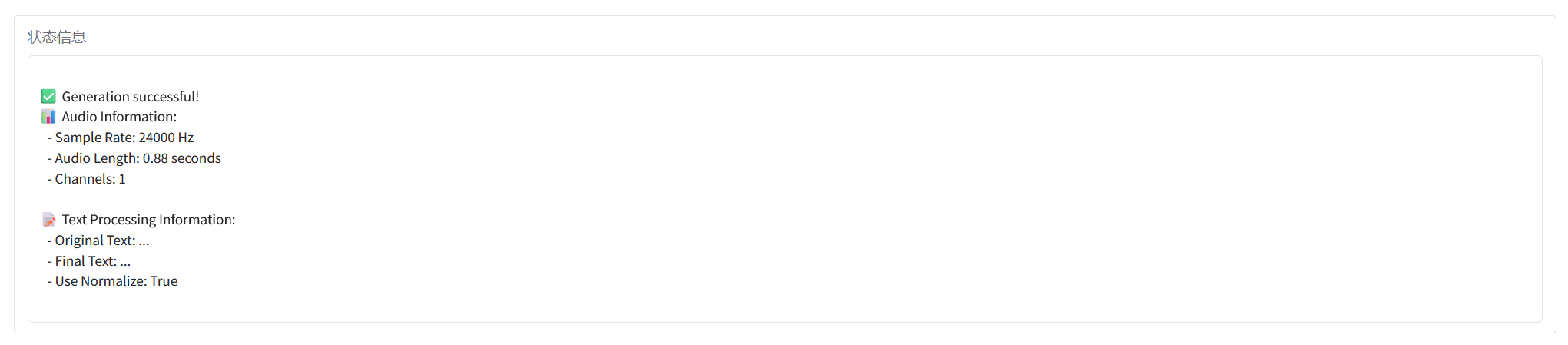
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@article{moss2025ttsd,
title={Text to Spoken Dialogue Generation},
author={OpenMOSS Team},
year={2025}
}Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.