Command Palette
Search for a command to run...
YOLOE : Tout Voir En Temps Réel
Date
Taille
1.94 GB
Balises
Licence
Apache 2.0
GitHub
URL du document
1. Introduction au tutoriel

YOLOE est un nouveau modèle de vision en temps réel proposé par une équipe de recherche de l'Université Tsinghua en 2025, visant à « tout voir en temps réel ». Il hérite des caractéristiques de temps réel et d'efficacité des modèles de la série YOLO et intègre pleinement l'apprentissage zéro-shot et les capacités d'aide multimodale, permettant la détection et la segmentation d'objets dans divers scénarios, y compris le texte, la vision et les scénarios sans aide. Des articles de recherche associés sont disponibles. YOLOE : voir tout en temps réel .
YOLO (You Only Look Once) est un leader dans la détection d'objets et la segmentation d'images depuis son lancement en 2015.Voici l'évolution de la série YOLO et les tutoriels associés :
- YOLOv2 (2016): Présentation de la normalisation par lots, des boîtes d'ancrage et du clustering de dimensions.
- YOLOv3 (2018):Utiliser des réseaux dorsaux plus efficaces, des multi-ancres et un regroupement pyramidal spatial.
- YOLOv4 (2020): Présentation de l'augmentation des données Mosaic, de la tête de détection sans ancrage et de la nouvelle fonction de perte. → Tutoriel :DeepSOCIAL réalise une surveillance de la distance de foule basée sur YOLOv4 et trie le suivi multi-cibles
- YOLOv5 (2020): Ajout de l'optimisation des hyperparamètres, du suivi des expériences et des fonctions d'exportation automatique. → Tutoriel :Modèle de suivi multi-cibles en temps réel YOLOv5_deepsort
- YOLOv6 (2022): Meituan open source, largement utilisé dans les robots de livraison autonomes.
- YOLOv7 (2022): Prend en charge l'estimation de la pose pour l'ensemble de données de points clés COCO. → Tutoriel :Comment former et utiliser un modèle YOLOv7 personnalisé
- YOLOv8 (2023):Ultralytics est sorti, prenant en charge une gamme complète de tâches d'IA visuelle. → Tutoriel :Entraînement de YOLOv8 avec des données personnalisées
- YOLOv9 (2024):Présentation des informations de gradient programmables (PGI) et du réseau d'agrégation de couches efficace généralisé (GELAN).
- YOLOv10 (2024):Lancé par l'Université Tsinghua, il introduit un en-tête de bout en bout et élimine l'exigence de suppression non maximale (NMS). → Tutoriel :Détection d'objets de bout en bout en temps réel YOLOv10
- YOLOv11(2024):Le dernier modèle d'Ultralytics, prenant en charge la détection, la segmentation, l'estimation de la pose, le suivi et la classification. → Tutoriel :Déploiement en un clic de YOLOv11
- YOLOv12 🚀 NOUVEAU (2025):Les doubles pics de vitesse et de précision, combinés aux avantages de performance du mécanisme d'attention !
Fonctionnalités principales
- Tout type de texte

2. Invites multimodales:
- Repères visuels (boîtes/points/formes dessinées à la main/images de référence)

- Détection silencieuse entièrement automatique – Identifier automatiquement les objets de la scène

Environnement de démonstration : séries YOLOv8e/YOLOv11e + RTX4090
2. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Veuillez patienter environ 1 à 2 minutes et actualiser la page.

2. Démonstration de la fonction YOLOE
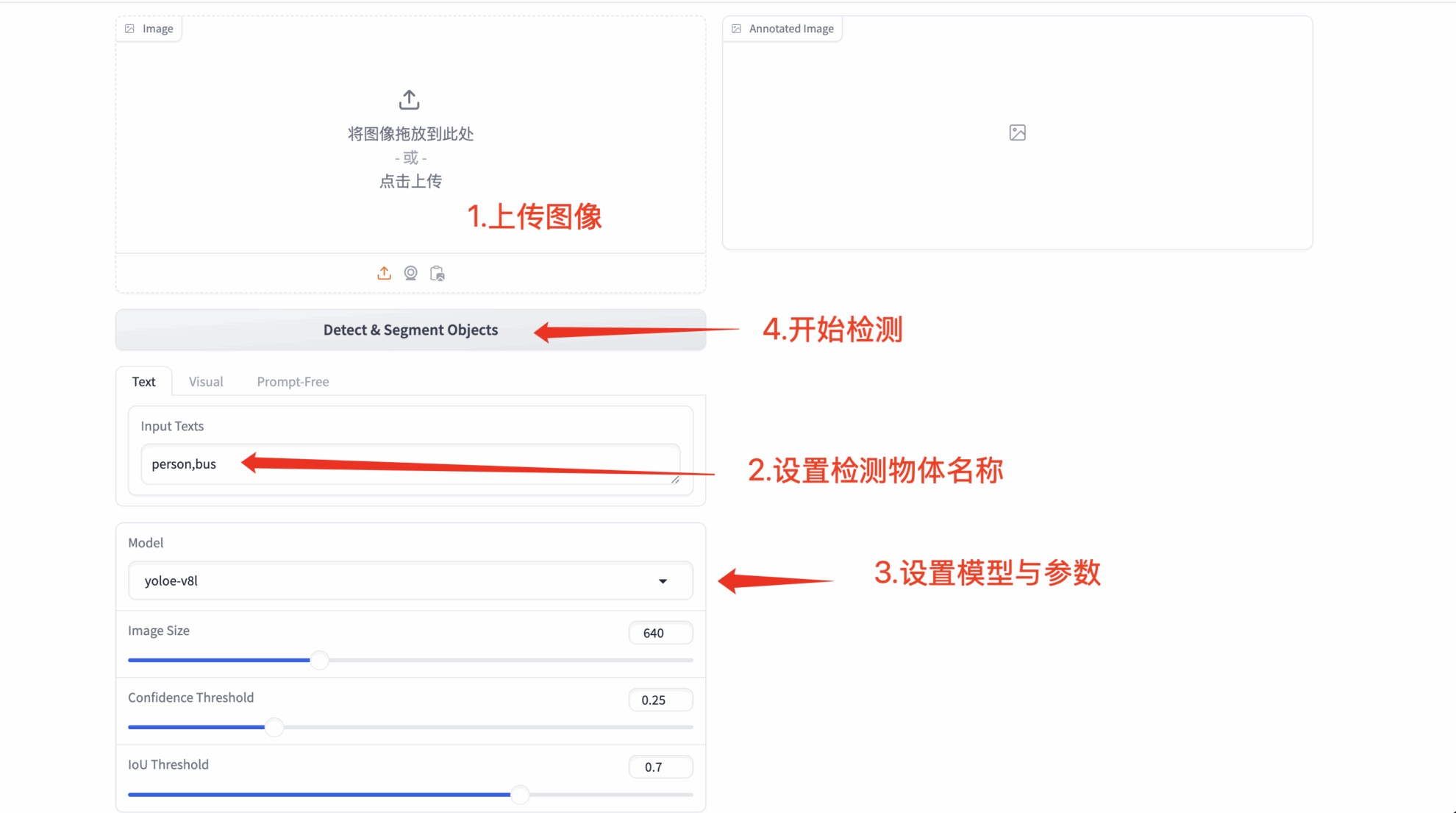
1. Détection d'invite de texte
- Tout type de texte
- Mots d'invite personnalisés: Permet à l'utilisateur de saisir du texte arbitraire (les résultats de la reconnaissance peuvent varier en fonction de la complexité sémantique)

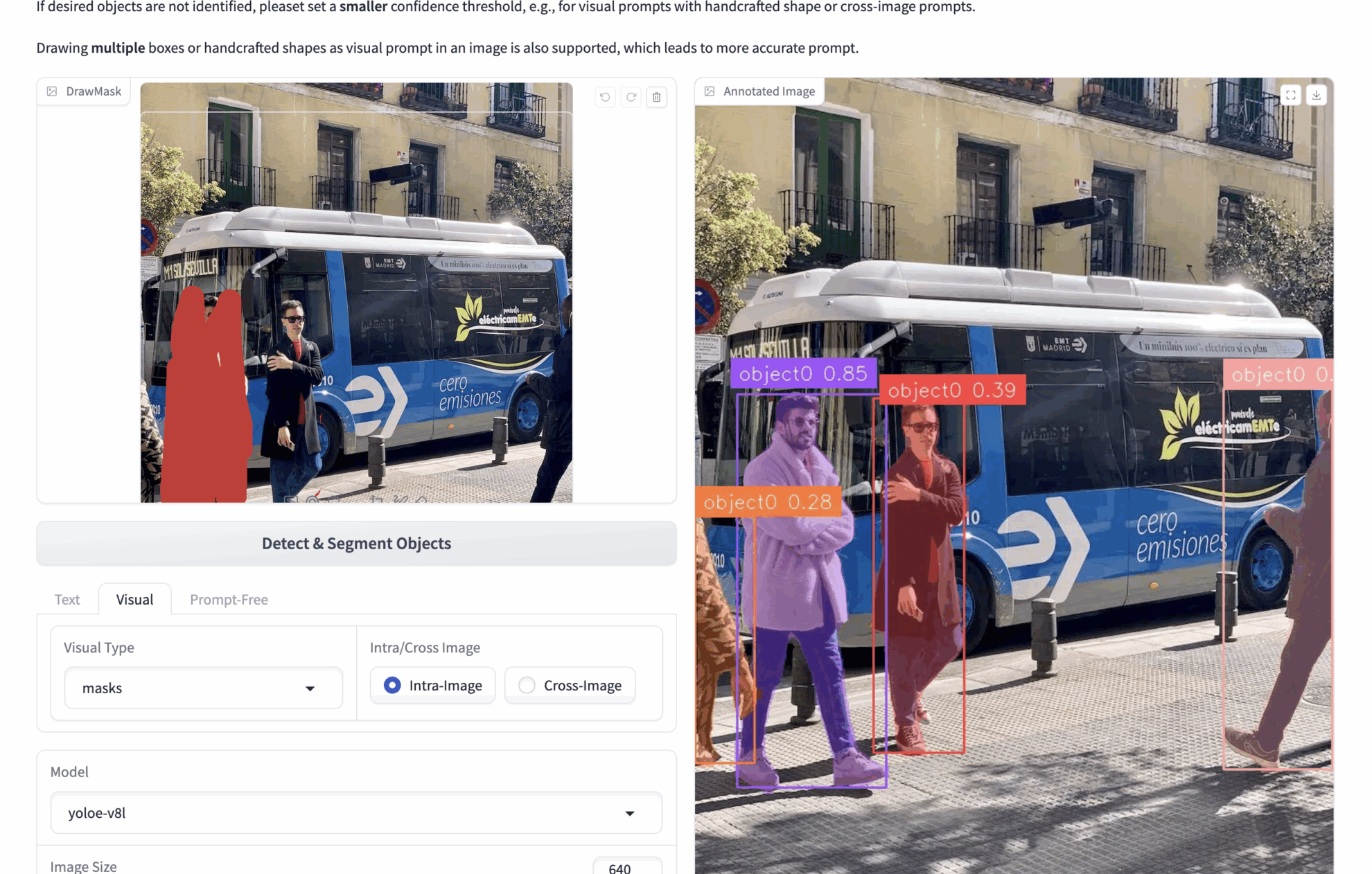
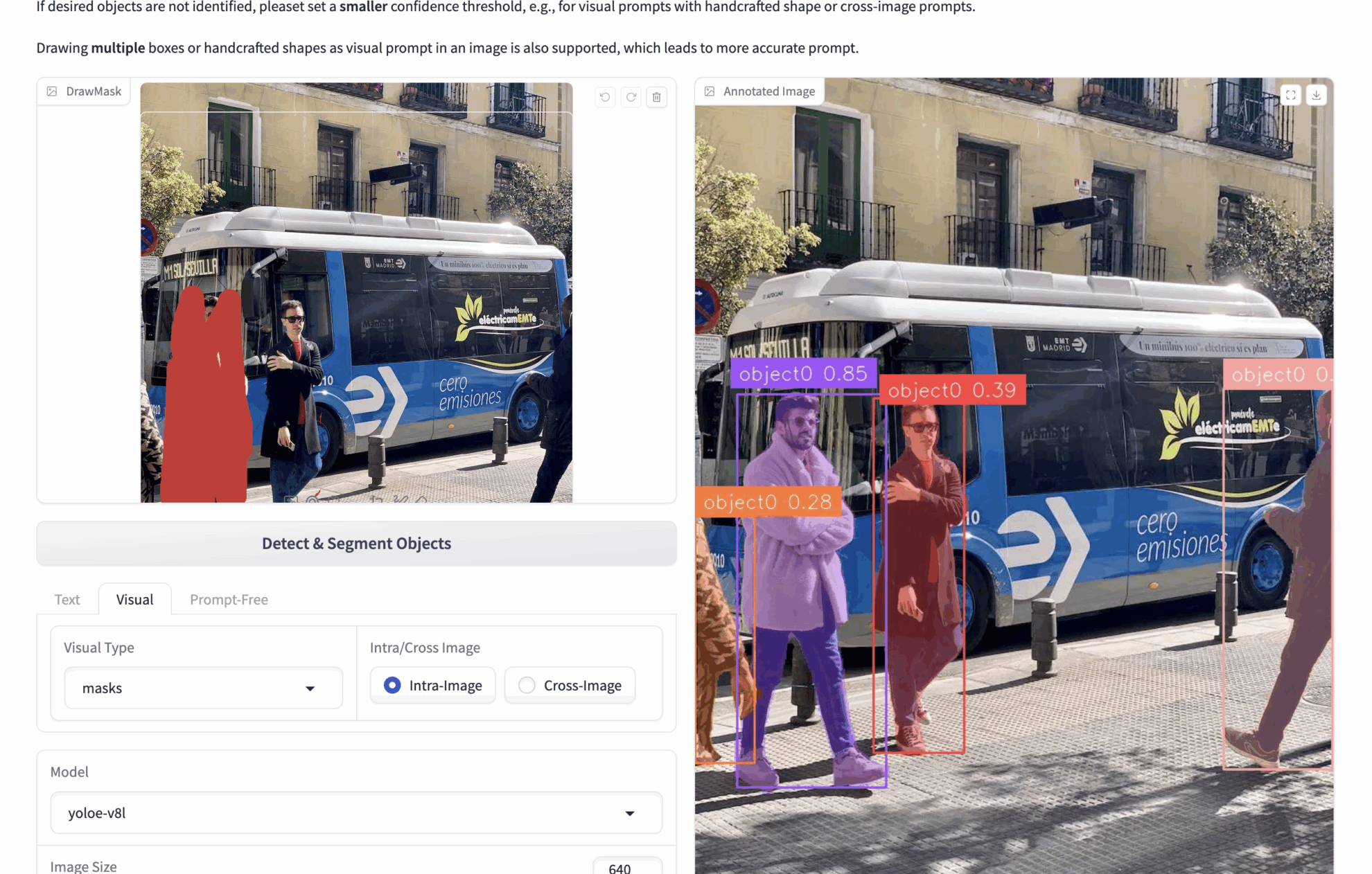
2. Indices visuels multimodaux
- 🟦 Détection de sélection de boîte (boîtes b)
bboxes : Par exemple, si vous téléchargez une image contenant de nombreuses personnes et que vous souhaitez détecter des personnes dans l'image, vous pouvez utiliser des bboxes pour encadrer une personne. Lors de l'inférence, le modèle identifiera toutes les personnes de l'image en fonction du contenu des bbox.
Plusieurs bboxes peuvent être dessinées pour obtenir des repères visuels plus précis. - ✏️ Zone de clic/dessin (masques)
Masques : Par exemple, si vous téléchargez une image contenant de nombreuses personnes et que vous souhaitez détecter des personnes dans l'image, vous pouvez utiliser des masques pour couvrir une personne. Lors de l’inférence, le modèle reconnaîtra toutes les personnes de l’image en fonction du contenu des masques.
Vous pouvez dessiner plusieurs masques pour obtenir des repères visuels plus précis. - 🖼️ Comparaison d'images de référence (Intra/Cross)
Intra : exploitez les bbox ou les masques sur l'image actuelle et effectuez une inférence sur l'image actuelle.
Croix : Exploitez les bbox ou les masques sur l'image actuelle et déduisez-les sur d'autres images.
Concepts de base
| modèle | Description fonctionnelle | Scénario d'application |
|---|---|---|
| Intra-image | Modélisation des relations entre objets au sein d'un même graphique | Positionnement précis de la cible locale |
| Image croisée | Correspondance des caractéristiques entre images | Récupération d'objets similaires |

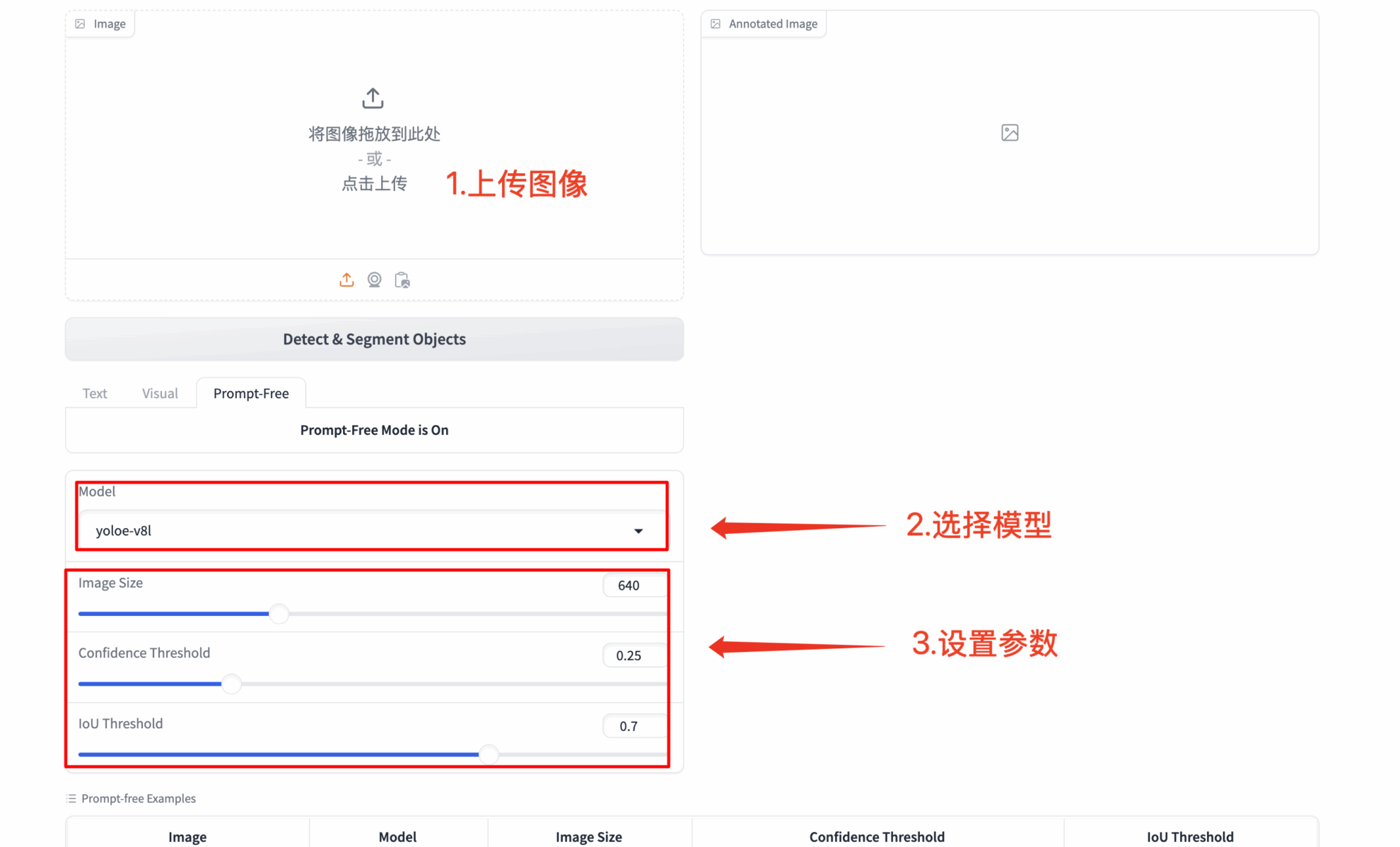
3. Détection entièrement automatique et silencieuse
- 🔍 Analyse de scène intelligente: Identifier automatiquement tous les objets saillants d'une image
- 🚀 Démarrage sans configuration:Fonctionne sans aucune saisie rapide

Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.