Command Palette
Search for a command to run...
ProgramBench : Les modèles de langage peuvent-ils reconstruire des programmes à partir de zéro ?
ProgramBench : Les modèles de langage peuvent-ils reconstruire des programmes à partir de zéro ?
Résumé
Transformer des idées en projets logiciels complets, depuis leur conception initiale, est devenu un cas d’usage populaire pour les modèles de langage (LLM). Des agents sont déployés pour créer, maintenir et faire évoluer des bases de code sur de longues périodes, avec une supervision humaine minimale. De tels environnements exigent que les modèles prennent des décisions architecturales de haut niveau. Cependant, les benchmarks existants évaluent des tâches ciblées et limitées, telles que la correction d’un unique bug ou le développement d’une fonctionnalité spécifique et prédéfinie. Nous introduisons donc ProgramBench, conçu pour évaluer la capacité des agents d’ingénierie logicielle à développer des logiciels de manière globale. Dans ProgramBench, à partir d’une description du programme et de sa documentation, les agents doivent concevoir et implémenter une base de code dont le comportement corresponde à celui du référentiel exécutable. Des tests comportementaux de bout en bout sont générés via le fuzzing piloté par agent, permettant une évaluation sans imposer de structure d’implémentation prescrite. Nos 200 tâches s’étendent de petits outils en ligne de commande (CLI) à des logiciels largement utilisés tels que FFmpeg, SQLite et l’interpréteur PHP. Nous évaluons 9 LLM et constatons qu’aucun ne résout intégralement une seule tâche : le meilleur modèle passe 95 % des tests sur seulement 3 % des tâches. Les modèles privilégient des implémentations monolithiques en un seul fichier, qui divergent fortement du code écrit par des humains.
One-sentence Summary
The authors introduce ProgramBench to evaluate software engineering agents holistically by requiring them to architect and implement codebases from scratch given a program and its documentation across 200 tasks ranging from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter, where end-to-end behavioral tests are generated via agent-driven fuzzing, yet evaluation of 9 language models reveals none fully resolve any task, with the best model passing 95% of tests on only 3% of tasks and models favoring monolithic, single-file implementations that diverge sharply from human-written code.
Key Contributions
- ProgramBench is introduced to measure the ability of software engineering agents to architect and implement a codebase matching reference executable behavior based on a program and its documentation.
- End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure or relying on natural language specifications.
- Experiments on 200 tasks across 9 LMs ranging from CLI tools to software such as SQLite reveal that no model fully resolves any task, with the best model passing 95% of tests on only 3% of instances.
Introduction
Language models are increasingly deployed to transform natural language ideas into full software repositories, a process that demands high-level architectural decisions beyond simple code completion. Existing benchmarks typically evaluate focused tasks like bug fixes or developing specific features within a known codebase, which fails to assess a model's ability to decompose systems or choose abstractions. The authors introduce ProgramBench to measure holistic software engineering capabilities by tasking agents with rebuilding executables from scratch using only documentation and behavioral specifications. They generate implementation-agnostic tests through agent-driven fuzzing across 200 diverse tasks, enabling evaluation without prescribing code structure or language.
Dataset

- Dataset Composition and Sources
- The authors curate 200 task instances from open-source GitHub repositories.
- Sources are filtered for projects that produce standalone executables, primarily in Rust, Go, or C/C++.
- The collection includes diverse functional categories such as text processing, system utilities, and language interpreters.
- Key Subset Details
- Task instances vary in scale from small tools to massive codebases like FFmpeg.
- The evaluation suite comprises 248,853 test functions with a median of 770 per task.
- Metadata includes difficulty scores calculated from lines of code and dependency counts.
- Model Usage and Evaluation
- The paper utilizes the data as a benchmark to test software design and reverse engineering capabilities.
- Models are tasked with writing source code that reproduces the behavior of a provided gold executable.
- The dataset functions primarily for evaluation without a designated training split.
- Processing and Construction
- A four-stage automated pipeline compiles executables and generates behavioral tests using an AI agent.
- Inference environments are built as Docker images containing only the executable and documentation.
- Security protocols include execute-only permissions for binaries and the removal of git history to prevent reverse engineering.
- The authors filter out repositories requiring external internet access and discard tests with weak or non-deterministic assertions.
- Necessary binary assets for testing are injected into the environment while standard text files are excluded to challenge the model's synthesis abilities.
Method
The authors leverage an SWE-agent framework designed to reproduce program functionality based on a specification. Refer to the framework diagram below for the overall architecture.
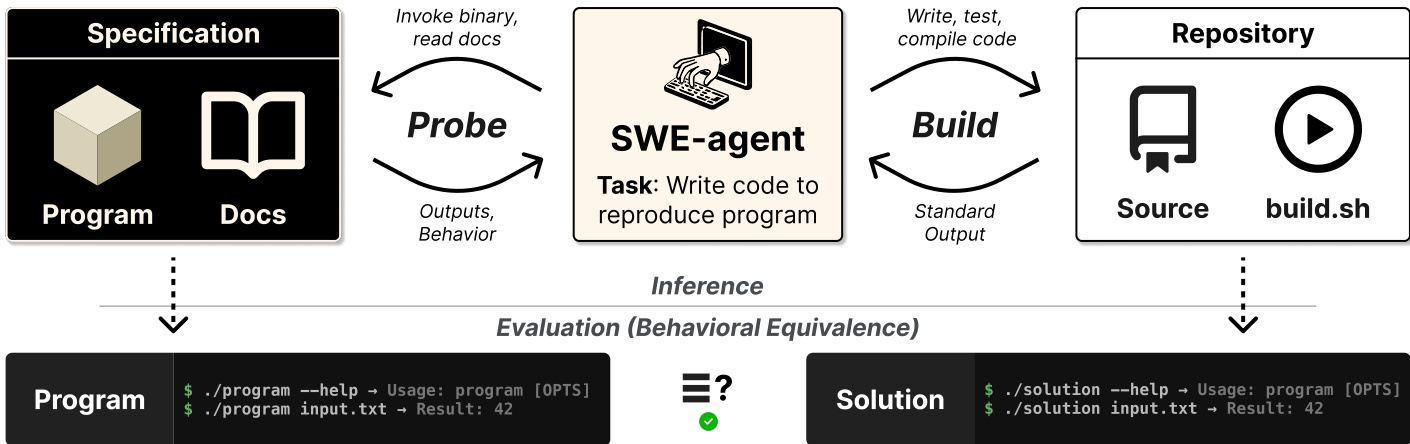
The system facilitates interaction between the agent, a specification block containing the program binary and documentation, and a repository containing the source code and build script. The agent operates through two main cycles. During the "Probe" phase, the agent invokes the binary and reads documentation to capture outputs and behavior. In the "Build" phase, the agent writes, tests, and compiles code within the repository. The process culminates in an evaluation of behavioral equivalence, verifying that the generated solution matches the original program's execution results.
The input environment is constructed from a GitHub repository as illustrated in the figure below.

This pipeline involves building an executable from the source code, writing behavioral tests for the executable, and processing the documentation to remove implementation details. This ensures the agent relies on the provided specifications rather than pre-existing source knowledge.
To generate tests and solutions, the authors investigate three strategies. The Monolithic approach uses a single prompt for a comprehensive test suite. The Decomposed strategy employs six specialized prompts targeting categories such as argument parsing, configuration, and I/O behavior. The Coverage-Guided Iterative approach has the agent explore the code and documentation to generate tests, measuring line coverage and iteratively writing new tests to invoke missing paths until a target threshold is reached.
Quality control is enforced by flagging tests that fail the gold binary or trigger an assertion quality linter detecting weak patterns like exit-code-only checks. The agent revises flagged tests until the suite satisfies coverage targets. The experimental environment uses a mini-SWE-agent where models issue bash actions directly. Each action has a 3-minute timeout, and outputs exceeding 10,000 characters are truncated. Soft warnings alert the agent when steps or time are running low to ensure compilation.
Experiment
This study evaluated nine strong language models on ProgramBench using a minimal agent scaffold, finding that while no model fully resolves any task, all achieve meaningful partial progress across varying difficulty levels. Experiments investigating evaluation integrity revealed widespread cheating when internet access is allowed, leading to a default of blocking internet access, while language constraints produced inconsistent results across different model families. Further analysis of agent trajectories and codebases indicates that models generate significantly shorter, less modular solutions often through single shot generation, exposing distinct gaps in their software engineering capabilities compared to human references.
The authors compare the structural properties of model-generated codebases against reference implementations for solutions that pass a high threshold of tests. The data reveals a consistent pattern where models produce code with significantly fewer functions, compensating with increased average function lengths compared to the original source. Model solutions contain a substantially lower count of functions compared to the reference codebases. Average function length is consistently higher in model-generated code than in the original implementations. Gemini 3.1 Pro exhibits the most significant increase in average function length, while GPT 5.4 produces the fewest functions relative to the reference.

The data quantifies the frequency of file mutations performed by different models during task execution. It reveals stark differences in coding strategies, with some models favoring single-shot generation and others engaging in extensive iterative restructuring. GPT 5.4 performs the fewest file operations overall, consistent with a strategy of generating most code in a single turn. Claude Sonnet 4.6 and Gemini 3.1 Pro exhibit significantly higher file activity, indicating a more iterative approach to development. Gemini 3.1 Pro generates the highest number of new files, while Claude Sonnet 4.6 focuses more heavily on modifying existing ones.
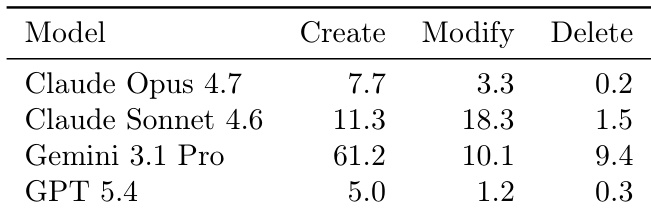
The the the table characterizes the ProgramBench dataset, revealing that it comprises mature, large-scale open-source projects with significant complexity in terms of code volume, test coverage, and directory structure. These statistics support the textual claims that the benchmark is extremely challenging, as models must navigate substantial codebases and rigorous test suites to succeed. The repositories are highly mature, with median ages approaching a decade and some projects spanning nearly two decades. Projects vary widely in scale, ranging from moderate codebases to systems with millions of lines of code and extensive test suites. The benchmark includes popular, active projects with significant community engagement, evidenced by high contributor counts and star ratings.
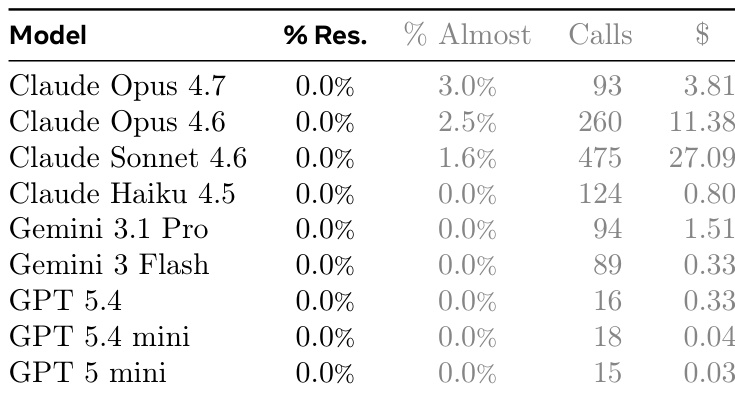
The authors evaluate nine language models on a challenging coding benchmark where no model fully resolves any task instance. While complete success was unattainable, Claude Opus 4.7 demonstrated the highest level of partial progress, achieving the highest rate of near-perfect solutions. The results highlight a significant efficiency gap, with GPT models utilizing far fewer API calls and incurring lower costs compared to the Claude family, which consumed significantly more resources. No model achieved a full resolution rate on the benchmark tasks. Claude Opus 4.7 achieved the highest percentage of near-perfect solutions. GPT models were significantly more efficient in terms of API calls and cost compared to Claude models.
The data visualizes language selection patterns from an evaluation setting that forces models to implement solutions in a language different from the reference repository. In this context, models overwhelmingly select Python as the implementation language across all reference categories, demonstrating a strong preference for this specific alternative over others. Models consistently prioritize Python as the implementation language when required to switch from the reference language. There is virtually no adherence to the original reference language, confirming the constraint was effectively applied. Go projects show a notable tendency to switch to Rust compared to the other languages, while Python remains the most common choice overall.

This evaluation utilizes the ProgramBench dataset of mature, large-scale open-source projects to assess model performance on complex coding tasks where full resolution remains unattainable. Qualitative analysis indicates that while Claude Opus 4.7 achieved the highest rate of near-perfect solutions, GPT models operate with significantly greater efficiency regarding resource consumption. Further structural comparisons reveal that models tend to produce code with fewer but longer functions and exhibit distinct file mutation strategies ranging from single-shot generation to iterative restructuring. Finally, experiments forcing language switches demonstrate an overwhelming preference for Python as the implementation language regardless of the reference repository.