Command Palette
Search for a command to run...
Rapport technique Qwen3-TTS
Rapport technique Qwen3-TTS
Résumé
Dans ce rapport, nous présentons la série Qwen3-TTS, une famille de modèles avancés de synthèse vocale texte-parole multilingue, contrôlables, robustes et en flux continu. Le modèle Qwen3-TTS intègre des fonctionnalités de pointe telles que la création de voix en 3 secondes et le contrôle basé sur des descriptions, permettant à la fois la génération de voix entièrement nouvelles et une manipulation fine du signal vocal produit. Entraîné sur plus de 5 millions d’heures de données vocales couvrant 10 langues, Qwen3-TTS repose sur une architecture de modèle linguistique à deux voies (dual-track LM) permettant une synthèse en temps réel, associée à deux tokenisateurs vocaux :1) Qwen-TTS-Tokenizer-25Hz, un codec à codebook unique mettant l’accent sur le contenu sémantique, qui permet une intégration transparente avec Qwen-Audio et une reconstruction en flux continu du signal audio via un modèle DiT par blocs ;2) Qwen-TTS-Tokenizer-12Hz, qui réalise une réduction extrême du débit binaire et une latence ultra-faible, permettant l’émission immédiate du premier paquet (en 97 ms) grâce à sa conception à 12,5 Hz, 16 couches et multi-codebooks, ainsi qu’à un réseau convolutif causal léger.Des expérimentations étendues démontrent des performances de pointe sur diverses évaluations objectives et subjectives (par exemple, ensemble de tests multilingue pour la synthèse vocale, InstructTTSEval, ainsi que notre propre ensemble de tests sur des énoncés longs). Afin de favoriser la recherche et le développement au sein de la communauté, nous mettons à disposition à la fois les tokenisateurs et les modèles sous licence Apache 2.0.
One-sentence Summary
The Qwen Team introduces Qwen3-TTS, a multilingual, controllable, streaming text-to-speech system built on a dual-track LM architecture and two tokenizers—Qwen-TTS-Tokenizer-25Hz for semantic-rich, Qwen-Audio-compatible streaming synthesis and Qwen-TTS-Tokenizer-12Hz for ultra-low-latency output with 97 ms first-packet emission—enabling 3-second voice cloning and state-of-the-art performance across multilingual, instructive, and long-form speech benchmarks.
Key Contributions
- Qwen3-TTS introduces a dual-track autoregressive architecture with two speech tokenizers: Qwen-TTS-Tokenizer-25Hz for semantic-aware streaming synthesis and Qwen-TTS-Tokenizer-12Hz for ultra-low-latency generation (97 ms first-packet emission), enabling real-time, high-fidelity TTS across 10 languages trained on 5M+ hours of speech data.
- The models achieve state-of-the-art performance in zero-shot voice cloning (lowest WER on Seed-TTS), cross-lingual synthesis (e.g., Chinese-to-Korean), and instruction-based voice control, outperforming ElevenLabs and GPT-4o-mini-tts while sustaining stable, artifact-free generation over 10-minute utterances.
- Qwen3-TTS unifies voice cloning, cross-lingual transfer, and fine-grained controllability within a single framework, with all models and tokenizers released under Apache 2.0 to advance open research in streaming, expressive multilingual speech synthesis.
Introduction
The authors leverage a dual-track language model architecture paired with two novel speech tokenizers to build Qwen3-TTS, a family of multilingual, controllable, and streaming text-to-speech models trained on over 5 million hours of speech. Prior TTS systems often struggle to balance naturalness, low latency, and fine-grained control—especially in streaming or cross-lingual settings—while discrete tokenization approaches typically sacrifice expressivity or introduce error accumulation. Qwen3-TTS addresses this by introducing Qwen-TTS-Tokenizer-25Hz for semantic-rich, streaming synthesis integrated with Qwen-Audio, and Qwen-TTS-Tokenizer-12Hz for ultra-low-latency output via a multi-codebook design and causal ConvNet, enabling first-packet emission in under 100 ms. Their main contribution is a unified autoregressive framework that delivers state-of-the-art performance in voice cloning, cross-lingual synthesis, instruction-based control, and long-form generation—all while being open-sourced under Apache 2.0 to accelerate community innovation.
Dataset

The authors use a multi-source dataset for training Qwen3-TTS, composed of publicly available and internally curated speech data. Key details include:
-
Dataset Composition and Sources:
- Combines public datasets (e.g., LibriTTS, VCTK, AISHELL-3) with proprietary in-house recordings.
- Includes multilingual and multi-speaker speech samples to support diverse voice synthesis.
-
Subset Details:
- Public subsets: ~500 hours total, filtered for clean audio, clear pronunciation, and minimal background noise.
- Internal subsets: ~1,200 hours, collected under controlled conditions, with speaker metadata and phonetic alignment.
- All subsets are filtered by SNR > 20dB, duration between 1–15 seconds, and validated by human annotators.
-
Usage in Training:
- Training split uses a 90:10 train-validation ratio.
- Data mixture: 60% public data, 40% internal data, balanced by speaker and language distribution.
- Text normalization and phoneme conversion applied uniformly across all sources.
-
Processing and Cropping:
- Audio cropped to 1–15 seconds; silence trimmed at start/end using energy thresholds.
- Metadata includes speaker ID, language tag, duration, and phoneme sequence.
- Augmentation: speed perturbation (±5%), noise injection, and volume normalization applied during training.
Method
The authors leverage a dual-path architecture for Qwen3-TTS, integrating text and speech modalities through a unified large language model backbone while supporting streaming synthesis and fine-grained voice control. The system operates on two distinct tokenization schemes—Qwen-TTS-Tokenizer-25Hz and Qwen-TTS-Tokenizer-12Hz—each tailored for different trade-offs between latency, fidelity, and expressivity.
For the 25 Hz variant, the tokenizer is built upon Qwen2-Audio and trained in two stages. In Stage 1, the audio encoder is augmented with a resampling layer and a vector quantization (VQ) layer inserted at an intermediate position, and the model is pretrained on an ASR task. In Stage 2, a convolution-based mel-spectrogram decoder is added to reconstruct mel-spectrograms from the quantized tokens, thereby injecting acoustic structure into the token representations. The resulting single-codebook tokens are then processed by a Diffusion Transformer (DiT) trained with Flow Matching, which maps token sequences to mel-spectrograms. These are subsequently converted to waveforms via a modified BigVGAN. To enable streaming, the authors implement a sliding-window block attention mechanism: tokens are grouped into fixed-length blocks, and the DiT’s attention is restricted to a receptive field of four blocks—current, three lookback, and one lookahead. This ensures low-latency generation while preserving contextual coherence. The same chunked decoding strategy is applied to BigVGAN to maintain streaming compatibility.
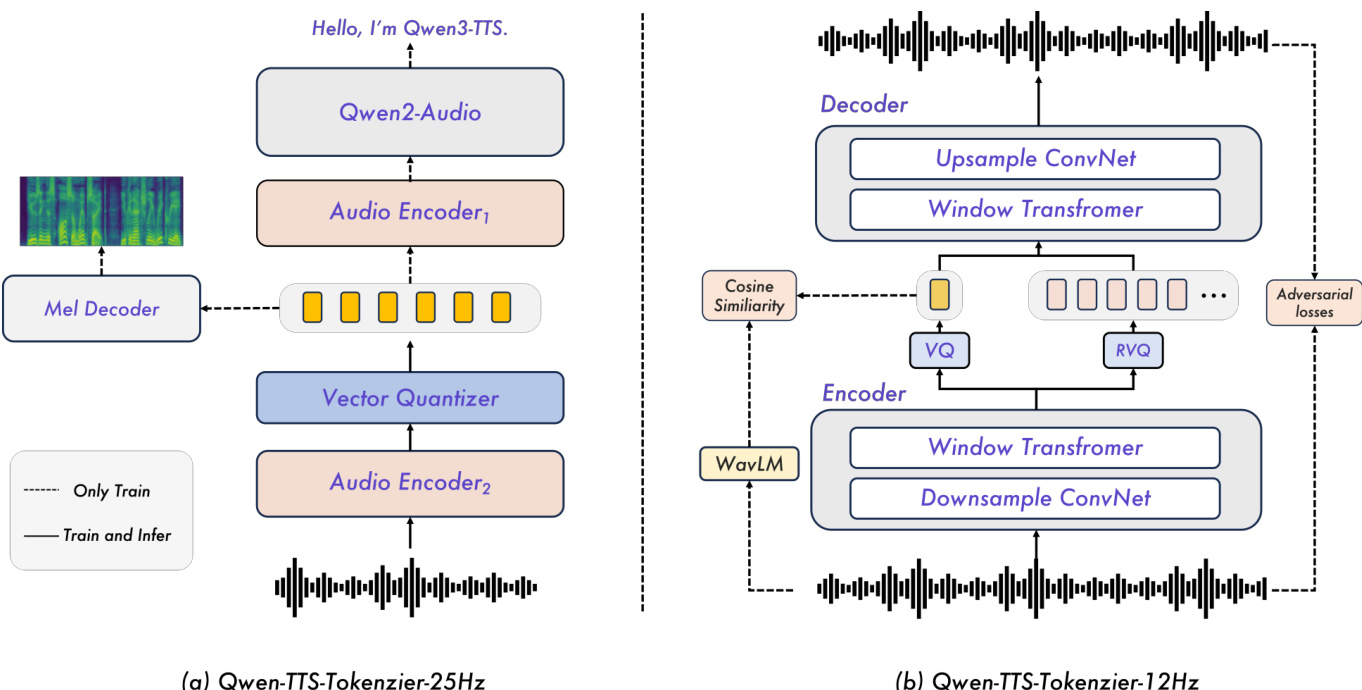
In contrast, the 12.5 Hz tokenizer adopts a multi-codebook design inspired by the Mimi architecture, disentangling semantic and acoustic information into two parallel streams. The semantic path uses WavLM as a teacher to guide the first codebook layer toward semantically meaningful representations, while the acoustic path employs a 15-layer residual vector quantization (RVQ) module to progressively refine fine-grained acoustic details. Training is conducted within a GAN framework: the generator operates directly on raw waveforms to extract and quantize both streams, while the discriminator enhances naturalness and fidelity. A multi-scale mel-spectrogram reconstruction loss further enforces time-frequency consistency. For streaming, both encoder and decoder are fully causal, emitting tokens at 12.5 Hz without look-ahead and reconstructing audio incrementally.
The Qwen3-TTS backbone integrates text and acoustic tokens via a dual-track representation, concatenating them along the channel axis. Upon receiving a textual token, the model predicts the corresponding acoustic tokens in real time. For the 25 Hz variant, the backbone predicts single-level tokens, which are then refined by a chunk-wise DiT for waveform reconstruction. For the 12 Hz variant, a hierarchical prediction scheme is employed: the backbone first predicts the zeroth codebook from aggregated features, and an MTP (Multi-Token Prediction) module generates all residual codebooks in parallel. This enables single-frame generation while capturing intricate acoustic details, improving vocal consistency and expressivity.
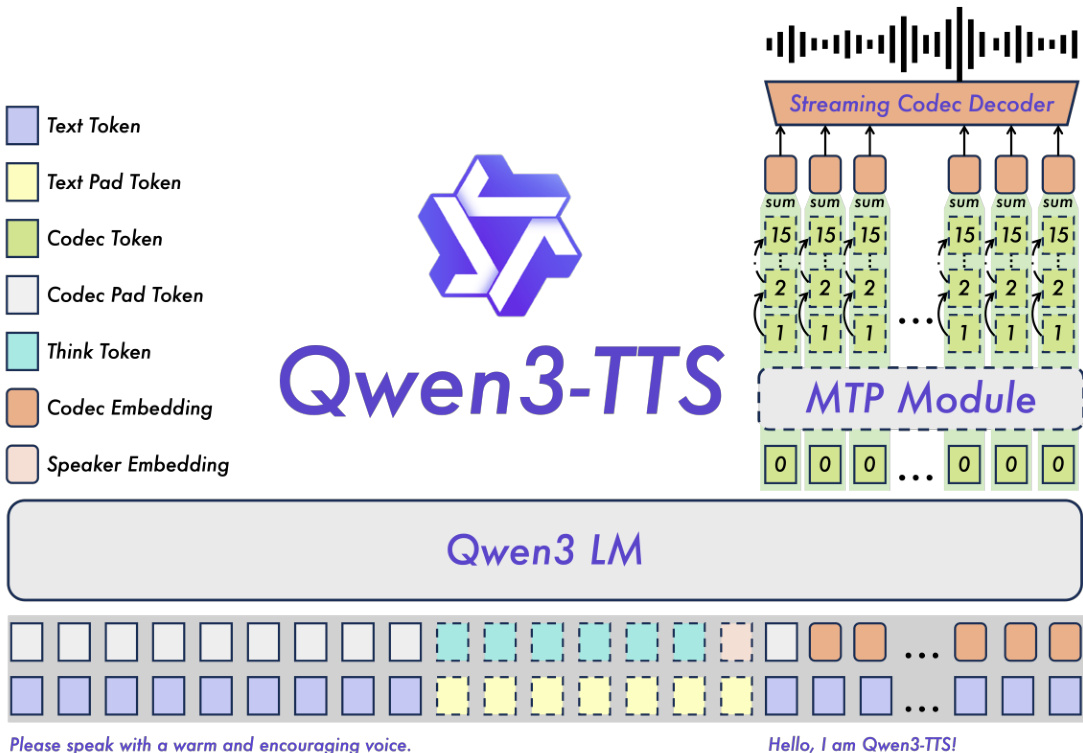
To support voice cloning and design, the system prepends user instructions containing control signals to the input sequence. Voice cloning is achieved either via a speaker embedding derived from reference speech (enabling real-time cloning) or through in-context learning from a text-speech pair (better preserving prosody). Voice design leverages the Qwen3 text model’s strong comprehension and instruction-following capabilities, enhanced by a probabilistically activated “thinking” pattern during training. This allows Qwen3-TTS to interpret complex voice descriptions and generate speech with predefined styles or traits.
Training proceeds in two phases: pre-training and post-training. Pre-training is structured into three stages: (1) General Stage (S1) trains on over 5 million hours of multilingual data to establish text-to-speech mapping; (2) High-Quality Stage (S2) uses stratified, high-quality data to reduce hallucinations; (3) Long-Context Stage (S3) extends the maximum token length to 32,768 and upsamples long speech to improve handling of extended inputs. Post-training includes: (1) Direct Preference Optimization (DPO) using human preference pairs to align outputs with human judgment; (2) rule-based rewards and GSPO to enhance stability and cross-task performance; and (3) lightweight speaker fine-tuning to enable voice adoption while improving naturalness and controllability.
Experiment
Qwen3-TTS was evaluated across efficiency, speech tokenization, and diverse speech generation tasks, using internal and public benchmarks with metrics like WER, SIM, STOI, and PESQ. The 12Hz tokenizer enables lower first-packet latency and superior reconstruction quality, setting new state-of-the-art scores on LibriSpeech, while the 25Hz variant excels in long-form synthesis with 1.53 WER on internal datasets. In zero-shot and multilingual generation, Qwen3-TTS-12Hz-1.7B achieved 1.24 WER on Seed-TTS and outperformed commercial systems in speaker similarity across 10 languages; it also reduced cross-lingual error rates by 66% in zh-to-ko tasks and demonstrated strong instruction-following and target-speaker adaptation, surpassing GPT-4o in 7 of 10 languages.
The authors evaluate Qwen3-TTS variants against commercial baselines across 10 languages, measuring content consistency and speaker similarity. Results show Qwen3-TTS achieves the lowest WER in 6 languages and highest speaker similarity across all 10 languages. The 1.7B model generally outperforms the 0.6B variant, with 12Hz variants excelling in speaker fidelity and 25Hz variants showing stronger content accuracy in some languages. Qwen3-TTS-12Hz-1.7B achieves best speaker similarity in all 10 languages Qwen3-TTS-25Hz-1.7B delivers lowest WER in Chinese, English, Italian, French, Korean, and Russian ElevenLabs shows lowest WER only in German and Portuguese among commercial baselines

The authors evaluate Qwen-TTS-Tokenizer-25Hz against S3 Tokenizer variants on ASR tasks across English and Chinese datasets. Results show Qwen-TTS-Tokenizer-25Hz in Stage 1 achieves the lowest or near-lowest WER on multiple benchmarks, outperforming S3 Tokenizer variants. In Stage 2, WER slightly increases due to added acoustic detail, reflecting a trade-off for improved speech generation quality. Qwen-TTS-Tokenizer-25Hz Stage 1 achieves best WER on C.V. EN and Fleurs EN Stage 2 shows mild WER increase, trading semantic fidelity for acoustic richness S3 Tokenizer variants show higher WER across most datasets compared to Qwen variant

The authors evaluate Qwen-TTS-Tokenizer-12Hz against prior semantic-aware tokenizers on speech reconstruction using LibriSpeech test-clean. Results show Qwen-TTS-Tokenizer-12Hz achieves state-of-the-art scores across all metrics including PESQ, STOI, UTMOS, and speaker similarity. It also maintains high efficiency with 16 quantizers and 12.5 FPS. Qwen-TTS-Tokenizer-12Hz sets new SOTA in PESQ_NB (3.68) and UTMOS (4.16) Achieves highest speaker similarity (SIM 0.95) among compared models Uses 16 quantizers at 12.5 FPS, balancing quality and efficiency

The authors evaluate Qwen3-TTS variants against leading zero-shot TTS systems on the SEED test set, measuring content consistency via Word Error Rate. Results show that Qwen3-TTS-12Hz-1.7B achieves the lowest WER on both Chinese and English subsets, outperforming baselines including CosyVoice 3 and MiniMax-Speech. The 12Hz variants consistently surpass 25Hz counterparts, indicating coarser temporal resolution improves long-term dependency modeling. Qwen3-TTS-12Hz-1.7B achieves state-of-the-art WER of 0.77 on test-zh and 1.24 on test-en 12Hz variants consistently outperform 25Hz variants in content accuracy across both languages Model scaling from 0.6B to 1.7B yields consistent WER improvements for both tokenizer variants

The authors evaluate Qwen3-TTS efficiency across model sizes and tokenizers under varying concurrency levels. Results show that 12Hz tokenizers achieve significantly lower first-packet latency and RTF compared to 25Hz variants, especially under higher concurrency. Larger models exhibit higher latency but maintain acceptable real-time factors for streaming use. 12Hz tokenizers reduce first-packet latency by up to 50% compared to 25Hz variants Higher concurrency increases latency but 12Hz models maintain lower RTF under load Larger models (1.7B) show higher latency but better efficiency than smaller (0.6B) counterparts

Qwen3-TTS variants were evaluated across multilingual, zero-shot, and efficiency benchmarks, consistently outperforming commercial and prior systems in speaker similarity and content accuracy, with the 1.7B model and 12Hz tokenizer achieving state-of-the-art results in speaker fidelity and WER on Chinese and English, while also demonstrating superior streaming efficiency under concurrency. The Qwen-TTS-Tokenizer-25Hz excelled in ASR tasks with low WER in Stage 1, while the 12Hz variant set new SOTA in speech reconstruction metrics like PESQ and UTMOS on LibriSpeech, balancing quality and speed at 12.5 FPS. In zero-shot settings, Qwen3-TTS-12Hz-1.7B achieved the lowest WER on SEED test sets, surpassing CosyVoice 3 and MiniMax-Speech, and 12Hz variants consistently outperformed 25Hz in content consistency, indicating better long-term modeling. Efficiency tests confirmed 12Hz tokenizers reduce latency by up to 50% under load, with larger models maintaining acceptable real-time factors despite higher latency.