Command Palette
Search for a command to run...
AnyFlow : Modèle de diffusion vidéo à toute étape avec distillation de carte de flux en politique
AnyFlow : Modèle de diffusion vidéo à toute étape avec distillation de carte de flux en politique
Yuchao Gu Guian Fang Yuxin Jiang Weijia Mao Song Han Han Cai Mike Zheng Shou
Résumé
La génération vidéo en quelques étapes a été considérablement améliorée par la distillation de cohérence. Cependant, les performances des modèles distillés par cohérence se dégradent souvent lorsque davantage d’étapes d’échantillonnage sont allouées lors de l’inférence, ce qui limite leur efficacité pour la diffusion vidéo à tout nombre d’étapes. Cette limitation provient du fait que la distillation de cohérence remplace la trajectoire d’équation différentielle ordinaire (EDO) à flux de probabilité original par une trajectoire d’échantillonnage de cohérence, affaiblissant ainsi le comportement souhaitable de mise à l’échelle au moment de l’inférence propre à l’échantillonnage par EDO. Pour remédier à cette limitation, nous introduisons AnyFlow, le premier cadre de distillation de diffusion vidéo à tout nombre d’étapes basé sur des cartes de flux. Au lieu de distiller un modèle pour un nombre fixe et réduit d’étapes d’échantillonnage, AnyFlow optimise la trajectoire complète d’échantillonnage par EDO. À cette fin, nous déplaçons la cible de distillation de la mappage de cohérence entre l’état initial et final (z_{t}rightarrow z_{0}) vers l’apprentissage de transitions par carte de flux (z_{t}rightarrow z_{r}) sur des intervalles de temps arbitraires. Nous proposons en outre la Simulation à rebours par carte de flux, qui décompose un déroulement complet d’Euler en transitions de carte de flux en raccourci, permettant une distillation on-policy efficace qui réduit les erreurs au moment de l’inférence (c’est-à-dire l’erreur de discrétisation dans l’échantillonnage en quelques étapes et le biais d’exposition dans la génération causale). De nombreuses expériences menées sur des architectures bidirectionnelles et causales, à des échelles allant de 1,3 milliard à 14 milliards de paramètres, démontrent que AnyFlow atteint des performances équivalentes ou supérieures à celles des modèles basés sur la cohérence dans le régime à quelques étapes, tout en s’adaptant aux budgets d’étapes d’échantillonnage.
One-sentence Summary
The authors introduce AnyFlow, an any-step video diffusion framework that replaces endpoint consistency mapping with flow-map transition learning via Flow Map Backward Simulation to enable efficient on-policy distillation of the full ODE trajectory, thereby reducing test-time discretization and exposure errors while supporting flexible sampling across step budgets and achieving VBench scores of 84.05 for causal text-to-video and 87.87 for image-to-video at four steps, matching or exceeding baselines such as Krea-Realtime-14B and Wan2.1-I2V-14B.
Key Contributions
- Introduces AnyFlow, the first any-step video diffusion distillation framework based on flow maps, which shifts the distillation target from fixed-point endpoint mapping to transition learning across arbitrary time intervals. This formulation enables a single model to support flexible inference budgets while preserving the desirable test-time scaling behavior of probability-flow ODE sampling.
- Proposes Flow Map Backward Simulation, a trajectory decomposition technique that breaks full Euler sampling paths into shortcut flow transitions to enable efficient on-policy distillation. This mechanism corrects discretization errors during few-step sampling and mitigates exposure bias in causal generation.
- Validates the framework across 1.3B to 14B parameter models, demonstrating performance that matches or surpasses consistency-based baselines in few-step regimes while improving with additional sampling steps. The method achieves competitive VBench scores in causal and bidirectional text-to-video and image-to-video generation, reaching 84.41 at 32 NFEs for text-to-video and 87.87 for image-to-video at 4 NFEs.
Introduction
Video diffusion models have achieved remarkable generation quality, yet most pipelines remain constrained to fixed inference budgets, creating a practical need for systems that can dynamically trade latency for fidelity at test time. Existing few-step distillation methods predominantly rely on consistency models that map intermediate states directly to the initial noise distribution. This fixed-point approach induces cumulative trajectory drift during multi-step sampling, causing performance to degrade as step counts increase while introducing severe discretization and exposure biases. To resolve these structural bottlenecks, the authors introduce AnyFlow, the first any-step video diffusion distillation framework built on flow maps. Instead of targeting endpoint consistency, the model learns transitions between arbitrary time pairs, naturally supporting variable step sizes. The authors further propose flow map backward simulation for on-policy distillation, which decomposes full Euler rollouts into efficient shortcut segments to correct rollout mismatches and maintain robust test-time scaling across diverse computational budgets.
Method
The authors leverage a flow map formulation to enable any-step video diffusion, building on the concept of generalized transition operators that model mappings between arbitrary points along probability-flow ODE trajectories. This framework generalizes consistency modeling and standard flow matching, providing a unified perspective for diffusion distillation. The core of the method is the neural flow map model, which learns an approximation fθ(zt,t,r)≈zr for 1≥t>r≥0, parameterizing transitions between arbitrary time pairs. This formulation supports variable step sizes and any-step inference by learning a continuous transition operator rather than endpoint-only mappings. The model is trained using the MeanFlow objective, which approximates the averaged transport velocity on [r,t] and optimizes the predicted velocity field uθ. To address the computational cost of Jacobian-vector products in the derivative term, the authors adopt a finite difference approximation, which requires only two forward passes per training step and is compatible with Fully Sharded Data Parallel (FSDP) training.
The training process is structured in two complementary stages. In the first stage, forward flow map training, a pretrained video diffusion model is fine-tuned to learn a stable transition operator fθ. This stage employs several design choices to improve performance and stability. An interpolated timestep conditioning scheme is used to maintain alignment with the pretrained model's embedding norms, avoiding over-saturation. A time sampling strategy with a reweighting function w(t) balances the training objective across different noise levels. Guidance-fused training incorporates classifier-free guidance (CFG) by fusing the CFG objective into the prediction, which aligns with the guidance scale of the pretrained model and allows CFG to be omitted at test time. An adaptive loss reweighting scheme dynamically scales the loss for non-boundary time steps using the regression loss at t=r as a baseline, preserving the learned instantaneous velocity and preventing gradient instability.
In the second stage, on-policy flow map distillation, the model is further refined to reduce train-test mismatch, particularly addressing discretization error at low sampling budgets and exposure bias in causal generation. This stage uses a distribution matching distillation (DMD) objective, which requires the student to perform a self-rollout to z0 before re-noising to compute the Kullback–Leibler (KL) gradient. The key innovation lies in the flow map backward simulation paradigm, which exploits the composition property of flow maps to decompose a full rollout trajectory into shortcut transitions. For a target sampling budget of N steps, the trajectory from T to 0 is decomposed into segments: T→t, t→r, and r→0. The first and last segments are handled by shortcut transitions of the learned flow map, while t→r is the target transition. This allows for efficient simulation of different inference step budgets with the same computation cost, as the same model naturally supports different sampling budgets at test time.
The overall AnyFlow pipeline, as illustrated in Figure 4, combines these components. The framework begins with forward flow map training on teacher-synthesized data to provide a strong initialization. This is followed by on-policy distillation, where flow map backward simulation generates student rollouts and applies reverse-divergence supervision from a strong teacher, thereby reducing discretization error and exposure bias while preserving any-step capability. The method supports both bidirectional and causal architectures, enabling efficient and flexible inference for high-fidelity video generation. The flow map formulation and the decomposition of trajectories into shortcuts allow for scalable and efficient training, making AnyFlow a practical and robust solution for any-step video diffusion.
Experiment
Evaluated on standardized video generation benchmarks under a unified protocol, the main experiments validate the method's ability to achieve high-fidelity text-to-video and image-to-video synthesis with significantly reduced sampling steps. Qualitative and quantitative assessments demonstrate that the approach consistently outperforms leading counterparts by delivering sharper visual details, smoother motion, and stronger prompt adherence while effectively mitigating test-time errors. Ablation studies further validate that specific design choices, including on-policy distillation with flow map backward simulation, optimized time sampling, and interpolated timestep conditioning, collectively preserve pretrained knowledge, prevent training instability, and maintain practical computational efficiency. Overall, the results establish the framework as a robust and highly efficient solution for fast, high-quality video generation.
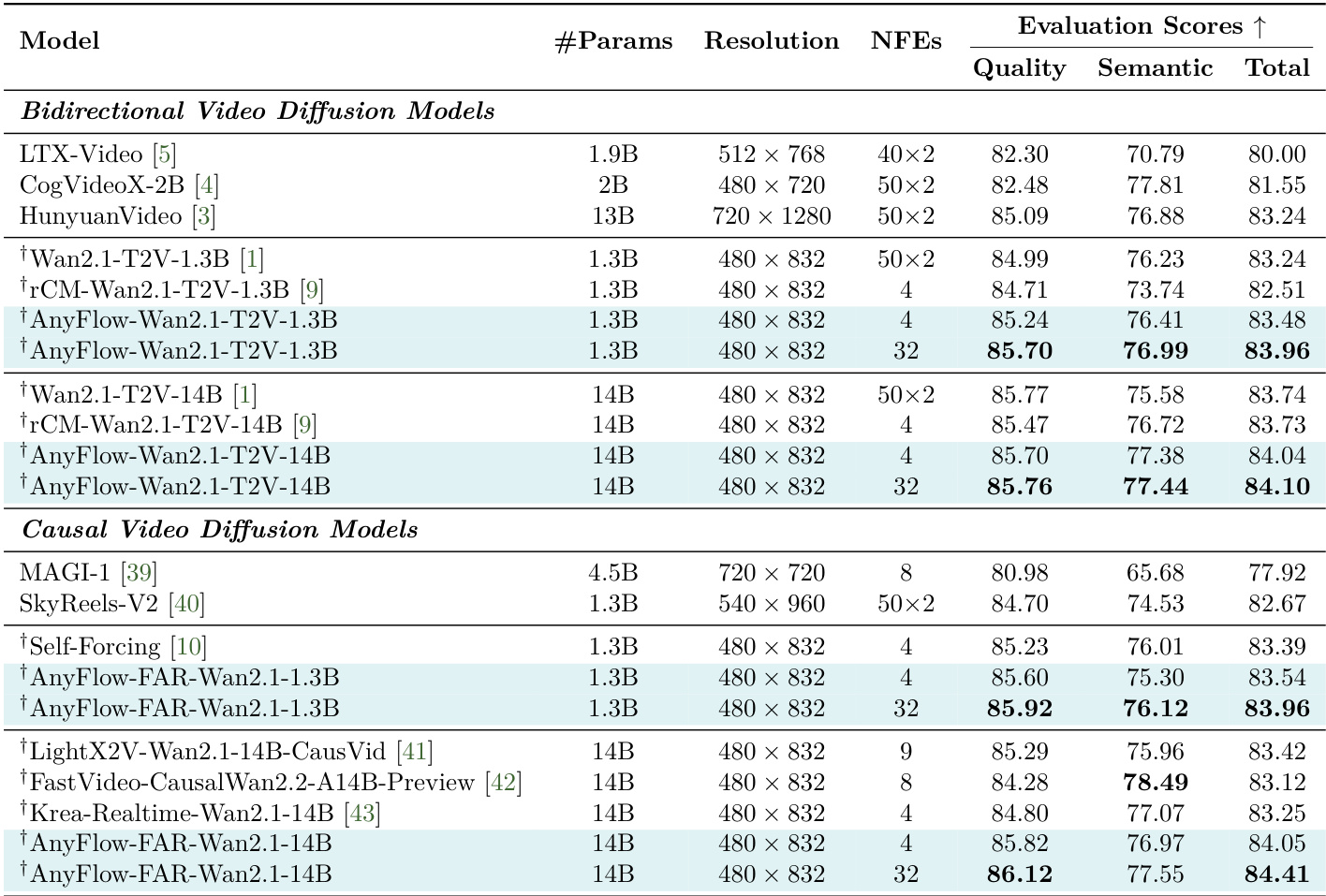
The authors present a comparison of various video generation models, focusing on their performance across different evaluation metrics and sampling efficiency. The results show that the proposed AnyFlow method achieves competitive or superior scores in both quality and image-to-video fidelity while using significantly fewer sampling steps compared to other models. AnyFlow achieves high evaluation scores with a much lower number of sampling steps compared to other models. The method demonstrates strong performance in both quality and image-to-video fidelity, outperforming several established models. AnyFlow maintains efficiency and effectiveness across different model architectures and training protocols.
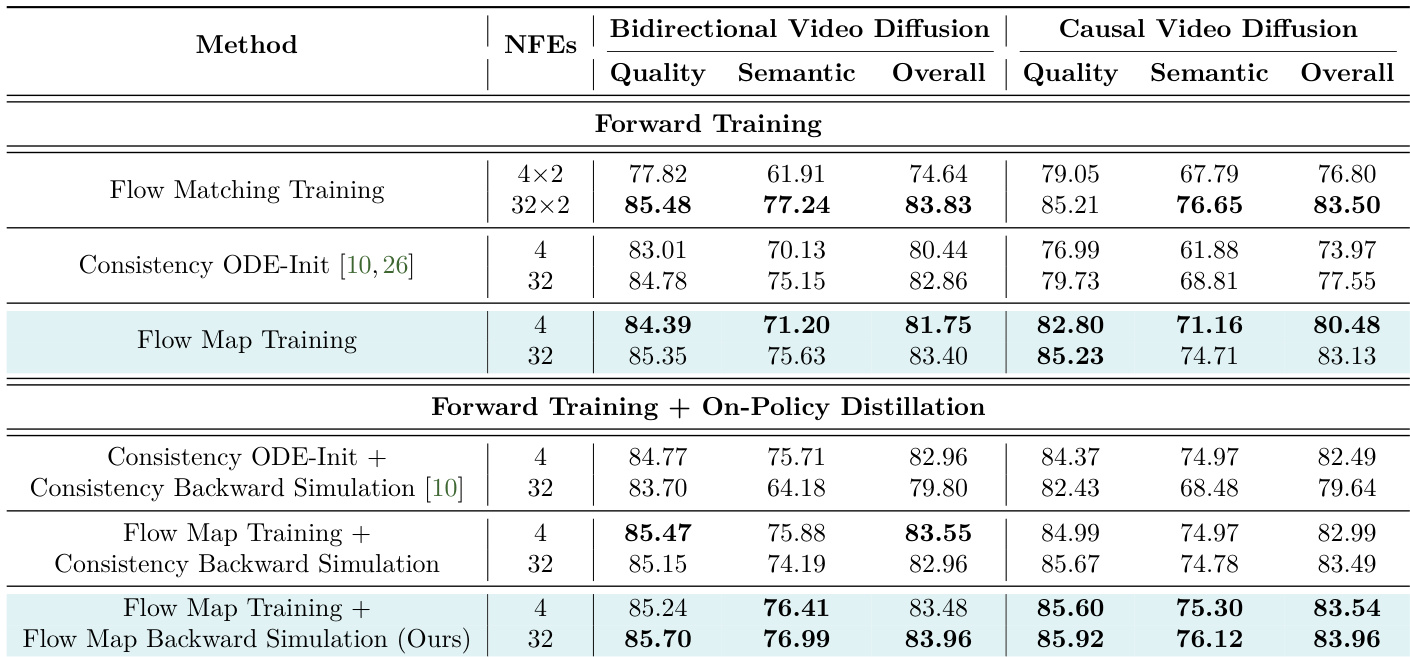
The authors conduct an ablation study to evaluate the impact of different training and distillation strategies on video generation performance. Results show that AnyFlow, which combines flow map training with flow map backward simulation, achieves superior performance across causal, bidirectional, and any-step generation settings compared to other methods. The study highlights that flow map backward simulation enables efficient multi-step generation while maintaining strong sampling efficiency. AnyFlow outperforms other methods in both causal and bidirectional video generation settings. Flow map backward simulation enables any-step video generation and improves efficiency at larger step counts. The combination of flow map training and on-policy distillation reduces test-time errors and enhances sampling performance.

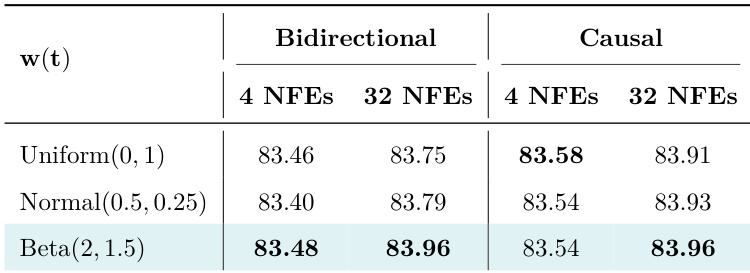
The authors evaluate different time samplers in their method, comparing their performance across few-step and multi-step sampling settings. Results show that the Beta distribution with specific parameters achieves the highest performance in both bidirectional and causal settings, particularly at 32 NFEs, indicating better test-time scalability compared to uniform and normal distributions. The Beta distribution with parameters (2, 1.5) achieves the best performance across both bidirectional and causal settings at 32 NFEs. Uniform and Normal distributions show lower performance compared to Beta, especially in multi-step sampling. The Beta distribution demonstrates superior test-time scalability, outperforming other samplers in the 32 NFEs setting.
The authors evaluate different training and distillation strategies for video diffusion models, focusing on the impact of flow map training and on-policy distillation. Results show that flow map training provides a stronger initialization than consistency-based methods, and combining it with on-policy distillation further improves performance, especially in few-step sampling. The proposed flow map backward simulation achieves better efficiency at larger step counts compared to consistency-based alternatives. Flow map training outperforms consistency ODE-Init in both few-step and multi-step settings, providing a stronger initialization for sampling. On-policy distillation further mitigates test-time errors and enhances performance, particularly when combined with flow map training. The proposed flow map backward simulation is more efficient than consistency-based methods at larger step counts, enabling faster training for multi-step generation.
The authors present a comparison of various video diffusion models, focusing on the performance of AnyFlow under different configurations and backbone architectures. Results show that AnyFlow achieves strong evaluation scores, particularly in few-step sampling settings, with improvements observed as the sampling budget increases. The the the table highlights that AnyFlow variants outperform other models in both bidirectional and causal settings, especially when using higher numbers of NFEs. AnyFlow achieves the highest evaluation scores in both bidirectional and causal video diffusion models, particularly at higher numbers of NFEs. The bidirectional backbone of AnyFlow demonstrates superior performance compared to the causal backbone in few-step sampling settings. AnyFlow variants consistently outperform other models in terms of Quality and Semantic scores, indicating improved visual quality and semantic fidelity.
The experimental evaluation compares AnyFlow against established video generation models across diverse architectures, sampling budgets, and generation settings to validate its overall efficiency and fidelity. Ablation studies further isolate the impact of specific training strategies, distillation techniques, and time sampler distributions. Qualitatively, the results demonstrate that AnyFlow consistently delivers superior visual quality and semantic accuracy while requiring significantly fewer sampling steps. The integration of flow map training with backward simulation and on-policy distillation proves highly effective for both causal and bidirectional generation, enabling robust multi-step sampling and enhanced test-time scalability.