Command Palette
Search for a command to run...
LLMs à flux multiples : débloquer les modèles de langage avec des flux parallèles de pensées, d'entrées et de sorties
LLMs à flux multiples : débloquer les modèles de langage avec des flux parallèles de pensées, d'entrées et de sorties
Guinan Su Yanwu Yang Xueyan Li Jonas Geiping
Résumé
Les améliorations continues des capacités des modèles de langage ont permis leur utilisation généralisée comme moteurs d’agents autonomes, par exemple dans des applications de codage ou d’utilisation d’ordinateurs. Cependant, le cœur de ces systèmes n’a guère évolué depuis les premiers modèles ajustés par instruction tels que ChatGPT. Même les agents d’IA avancés fonctionnent sur des formats d’échange de messages, échangeant successivement des messages avec les utilisateurs, les systèmes, avec eux-mêmes (c’est-à-dire la chaîne de pensée) et les outils, le tout dans un seul flux de calcul. Ce goulot d’étranglement lié à un flux unique dans les modèles de chat entraîne un certain nombre de limitations : l’agent ne peut pas agir (générer une sortie) tout en lisant, et inversement, ne peut pas réagir à de nouvelles informations tout en écrivant. De même, l’agent ne peut pas agir tout en réfléchissant, ni réfléchir tout en lisant ou en agissant sur des informations. Dans ce travail, nous montrons que les modèles peuvent être déblocés en passant d’un ajustement par instruction pour des formats de messages séquentiels à un ajustement par instruction pour plusieurs flux de calcul parallèles, en attribuant chaque rôle à un flux distinct. Chaque passe avant du modèle de langage lit alors simultanément à partir de plusieurs flux d’entrée et génère des tokens dans plusieurs flux de sortie, tous dépendant causalement des pas de temps antérieurs. Nous soutenons que ce changement piloté par les données remédie à un certain nombre de limitations d’utilisabilité mentionnées ci-dessus, améliore l’efficacité du modèle grâce à la parallélisation, renforce la sécurité du modèle par une meilleure séparation des responsabilités, et peut également améliorer la monitorabilité du modèle.
One-sentence Summary
Multi-Stream LLMs replace the sequential processing of instruction-tuned models with parallel computation streams that simultaneously read multiple inputs and generate multiple outputs while maintaining causal dependencies across timesteps, thereby eliminating processing bottlenecks and enabling autonomous agents to think, act, and process information concurrently.
Key Contributions
- This work introduces a multi-stream instruction-tuning framework that replaces sequential message exchange formats with parallel computation channels, enabling simultaneous reading, reasoning, and generation across distinct streams within a single forward pass.
- The architecture assigns distinct roles to independent streams, which structurally enforces instruction hierarchies to mitigate prompt injection and externalizes internal eval-awareness considerations across parallel thinking channels to enhance model monitorability.
- Evaluations on the Stream-27B model demonstrate that this format dispatches multiple tool calls concurrently to reduce latency, supports real-time user interruptions during generation, and isolates untrusted document content to maintain robust performance.
Introduction
Large language models have become foundational components of autonomous agents and real-time intelligent systems, yet they still rely on the sequential message formats inherited from early chat models. This single-stream architecture forces models to read, reason, and generate output one step at a time, creating a computational bottleneck that increases latency, hinders concurrent task execution, and leaves systems vulnerable to prompt injection due to a lack of structural instruction hierarchy. To address these constraints, the authors introduce a multi-stream framework that replaces sequential chat templating with parallel token streams dedicated to distinct roles such as user input, system instructions, internal reasoning, and tool output. By instruction-tuning models to process and generate across these independent channels simultaneously, the approach enables continuous reading-while-writing, reduces time-to-first-token, enforces architectural boundaries against malicious prompts, and provides dedicated audit channels for real-time behavioral monitoring.
Dataset
Dataset Composition and Sources
- The authors construct a synthetic multi-stream training corpus to compensate for the scarcity of naturally occurring simultaneous dialogue data.
- The core mixture integrates six public benchmarks spanning mathematical reasoning, logical inference, biomedical QA, reading comprehension, and general instruction following.
- A dedicated stress-test subset uses purely synthetic conversations generated via Claude Opus 4.5 to 4.7 to validate parallel stream retention.
Key Details for Each Subset
- MetaMathQA: Originally 40k augmented samples from GSM8K and MATH, reduced to approximately 8k after processing.
- LogicNLI: 16k natural language inference examples filtered down to ~8k training samples.
- ProofWriter: ~25k logical reasoning instances extracted from its ~40k collection.
- PubMedQA: ~26k biomedical QA samples retained from its 61k training pool.
- SQuAD: ~15k reading comprehension pairs sampled from over 100k available.
- Alpaca (Cleaned): ~48k instruction-response pairs kept from an initial 52k.
- Synthetic Stress-Test: 3,864 ten-stream conversations averaging 100 rows each.
- The authors pool these filtered subsets for training without specifying exact mixture ratios, relying on the final sample counts to balance the training distribution.
How the Paper Uses the Data
- All selected corpora are converted into a multi-stream format containing system, user, and one or more assistant streams.
- The model trains for three epochs using identical optimizer schedules and step budgets across all subsets.
- For baseline comparisons, the multi-stream sequences are collapsed into standard single-stream causal language modeling inputs, eliminating the need for separate baseline datasets.
- The stress-test subset specifically evaluates whether pretrained models can be instruction-tuned to maintain distinct internal reasoning roles across parallel streams.
Processing, Metadata Construction, and Other Details
- Wait-k Simulation: The pipeline mimics real-time interaction by having the assistant begin responding after observing only k user tokens. The value of k varies across samples to expose the model to different latency-quality trade-offs.
- Causal Verification and Context Reconstruction: Tokenized sequences are de-tokenized into readable segments aligned at meaningful boundaries. An LLM judge verifies that each assistant chunk only depends on temporally available user tokens, discarding or re-generating samples that leak future information.
- Two-Tier Quality Filtering: Per-stream checks ensure fluency, completeness, and absence of malformed tokens. Cross-stream checks verify that each stream fulfills its designated role. Samples scoring below predefined thresholds are removed.
- Tabular Generation Format: Purely synthetic data is generated column-by-column in a markdown table structure to strictly enforce causal boundaries and prevent non-causal cross-stream information leakage.
- Metadata and Evaluation Schema: The pipeline outputs strict JSON objects tracking stream indices, token steps, causal violations, and quality scores. Bridging utterances are injected to mark early-start turns, while internal streams in the stress-test set are assigned explicit functional labels such as analytical thinking or skepticism.
Method
The authors leverage a multi-stream parallel generation framework to enable large language models (LLMs) to generate multiple token sequences simultaneously within a single forward pass, fundamentally altering the standard autoregressive process. This approach contrasts with traditional sequential generation, where each token is produced one at a time, conditioned only on preceding tokens. The core formulation models the joint probability of H parallel streams {y(1),…,y(H)} as a product of conditional probabilities, where each token yt(h) in stream h depends not only on its own prior tokens but also on all tokens from every other stream that occurred before position t. This ensures global causal consistency across all streams, allowing for dense cross-stream dependencies while maintaining intra-stream causality.
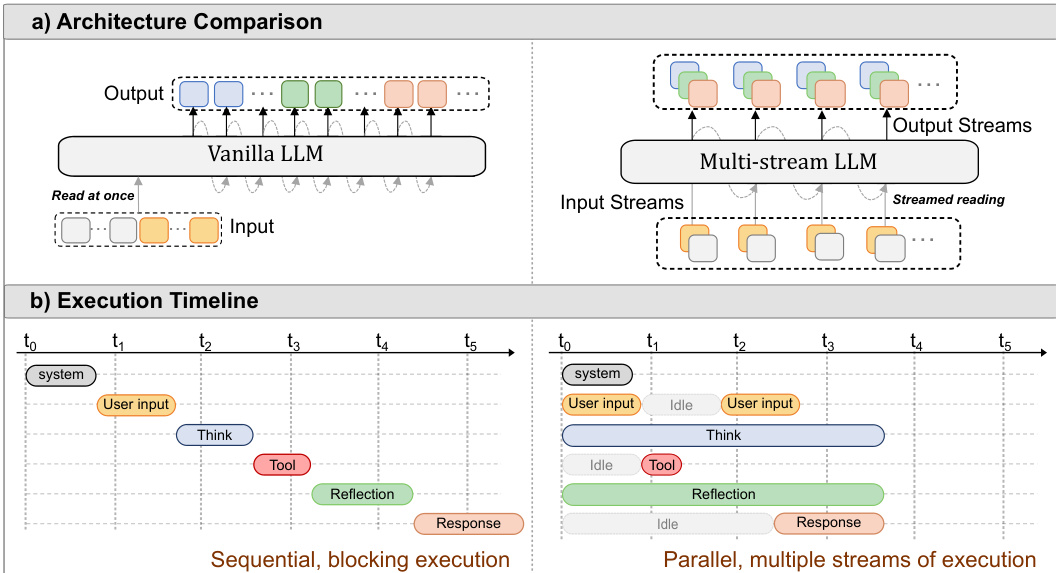
Refer to the framework diagram above, which illustrates the architectural shift from a standard "Vanilla LLM" to a "Multi-stream LLM". The model processes multiple input streams, such as user input, system prompts, and auxiliary data like tool results or memory recall, and generates corresponding output streams for various tasks including user-facing responses, internal reasoning, and tool calls. This parallel processing enables the model to simultaneously read, think, and act, overlapping these stages to reduce latency. The execution timeline in the diagram shows how a multi-stream LLM can generate tokens for different streams in parallel, such as emitting a "Response" while concurrently performing "Think" and "Reflection" actions, unlike the sequential, blocking execution of a vanilla LLM.
The implementation of this architecture in a Transformer-based model requires two key modifications to the standard decoder-only structure. First, stream-aware position encoding is employed to handle the multi-stream input. This involves using a variant of Rotary Positional Encoding (RoPE) with per-stream position indexing, where each stream maintains its own independent counter starting from zero. This prevents positional contention and ensures natural temporal alignment. Additionally, a learnable stream embedding is added to the token embedding to explicitly identify each stream's identity. Second, a cross-stream causal attention mask is implemented to enforce the causal constraints. This binary mask ensures that a query token at position (h,t) can only attend to key tokens from any stream h′ at positions τ<t, thereby preserving the global causal order across all streams.
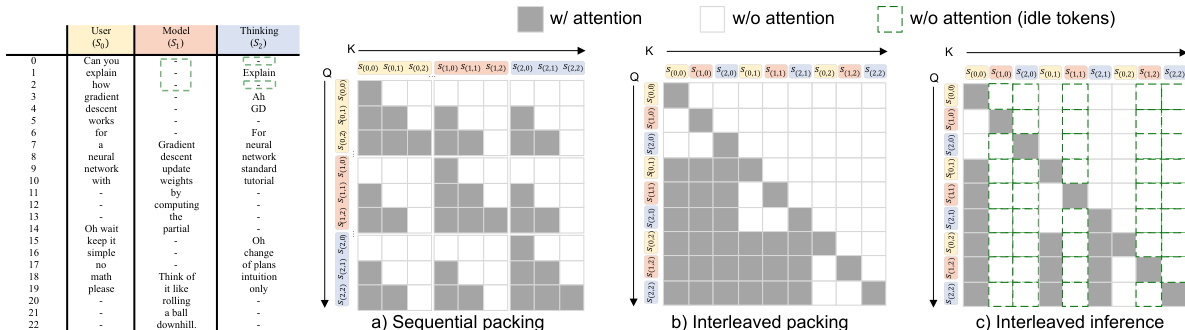
The model is trained using standard cross-entropy loss, with the primary goal of enabling the model to predict the correct next token in each of its streams. To efficiently implement the causal mask and optimize inference, a specific token packing strategy is used. The authors adopt an interleaved packing method, which reorders tokens from different streams in a position-wise manner. This creates a predominantly lower-triangular attention pattern, which is highly efficient for causal attention computation and allows for the reuse of fast-path implementations like FlashAttention. This is in contrast to sequential packing, which creates fragmented attention regions. The model's training objective is defined by the cross-entropy loss over all valid tokens in all streams, with the loss calculated as the average over each stream's tokens.
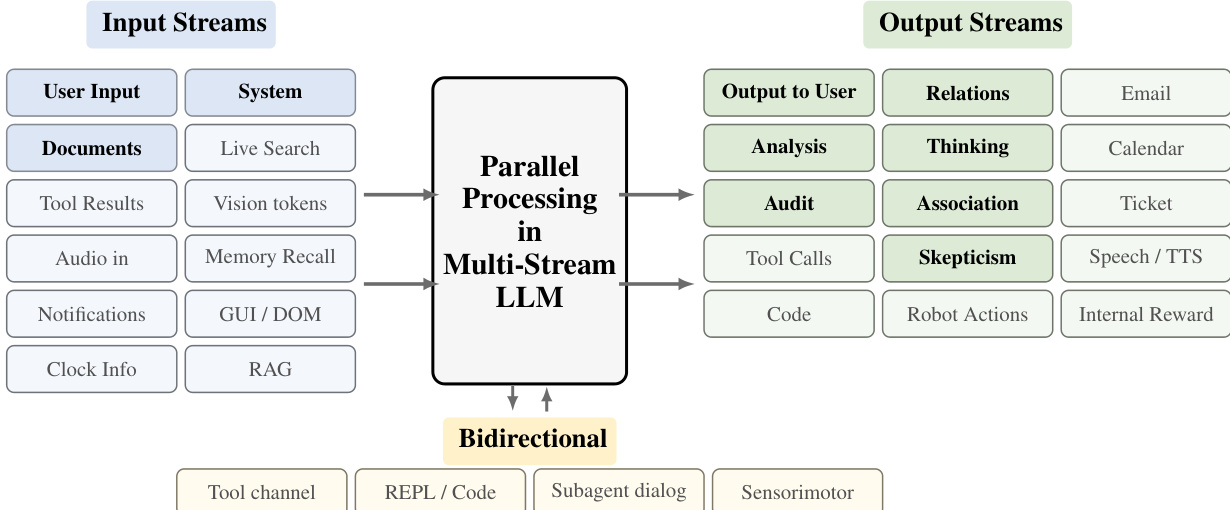
During inference, the model performs synchronous multi-stream decoding. At each step, a single forward pass generates one token for each stream, with the streams being processed in an interleaved fashion. The model's output for each stream is conditioned on the previous tokens from all other streams, ensuring that the parallel streams can interact and influence each other. This synchronous process is illustrated in the diagram below, which shows a multi-stream LLM generating a response while simultaneously performing "Solving" and "Auditing" tasks, with the user input stream and the model's internal thinking streams running in parallel. Empty tokens, which represent inactive streams at a given step, are fully masked and do not consume any memory in the key-value cache, resulting in zero memory overhead. This enables a theoretical H× speedup over sequential decoding, where H is the number of streams. The model's ability to generate multiple streams also enhances monitorability, as internal streams can provide a "sub-vocalization" of the model's considerations, allowing an external observer to access its hidden reasoning processes.
Experiment
The experiments evaluate a multi-stream architecture across reasoning, security, and architectural ablation benchmarks using Qwen base models trained on standard datasets. Efficiency tests demonstrate that overlapping input processing, solution generation, and real-time auditing into parallel streams substantially reduces latency and first-token delay while preserving task accuracy. Security evaluations confirm that architecturally isolating system, user, and assistant streams creates a built-in privilege hierarchy that significantly improves robustness against direct and indirect prompt injections without requiring adversarial training or compromising general instruction-following capabilities. Complementary ablations validate the selected positional encoding strategy for managing cross-stream attention conflicts and confirm that parallel streams effectively support internal reasoning awareness under supervision.
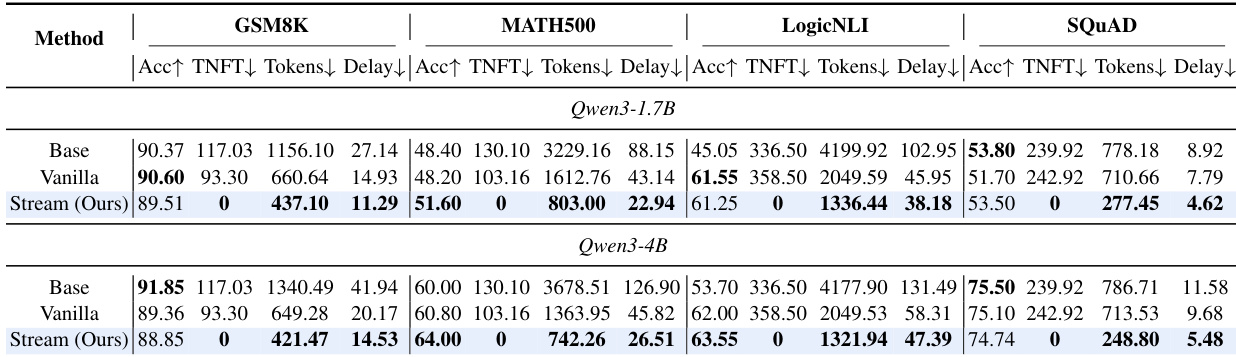
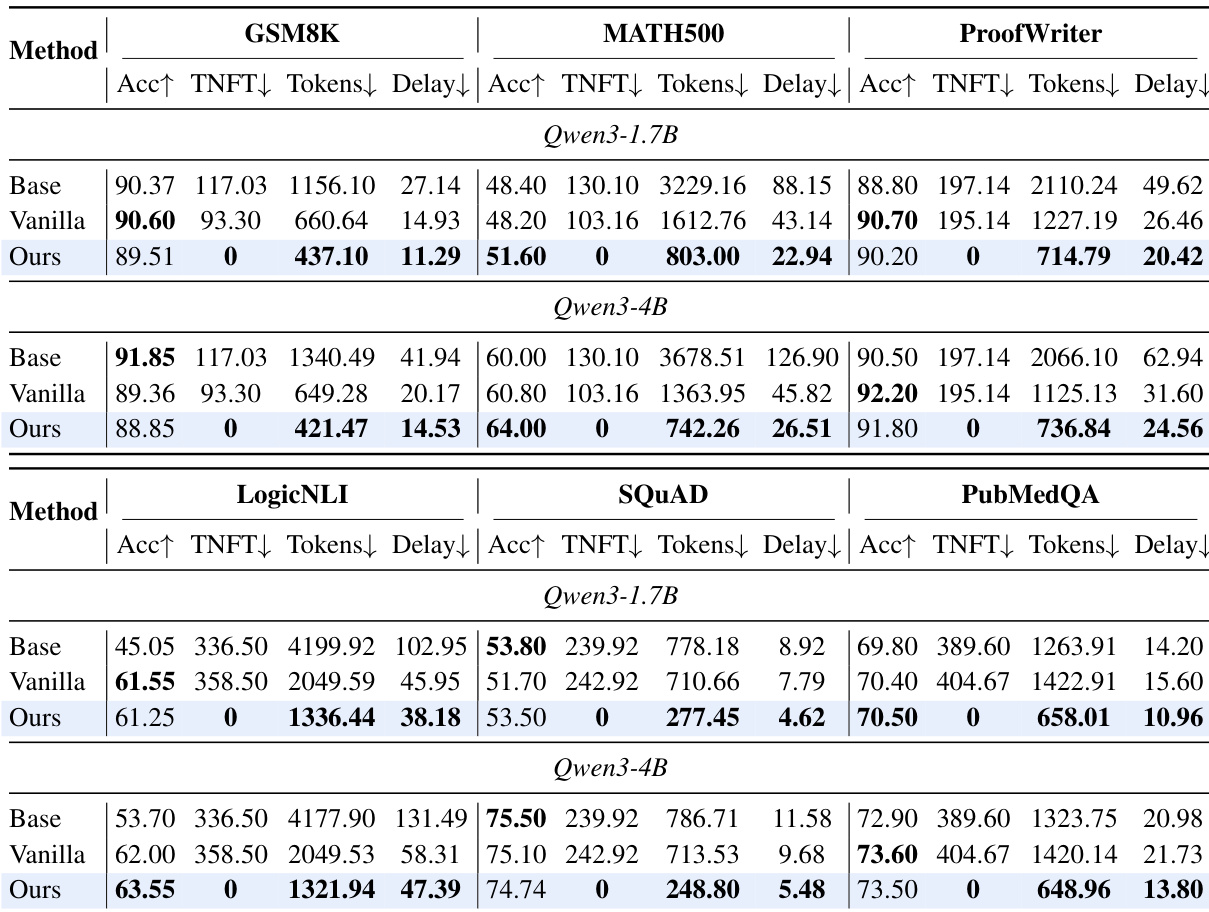
The authors compare a multi-stream model variant against base and vanilla single-stream baselines across multiple benchmarks and model scales, demonstrating that the multi-stream approach reduces latency and first-token delay while maintaining or slightly improving accuracy. The results show consistent efficiency gains in token count and delay metrics, with the most significant improvements observed in the larger model. The multi-stream method achieves zero first-token delay on all benchmarks, indicating concurrent input processing and output generation. The multi-stream model reduces first-token delay to zero across all benchmarks, enabling immediate response generation during input reception. Efficiency metrics such as tokens and delay are significantly lower for the multi-stream variant compared to the vanilla baseline, indicating faster inference. Accuracy remains comparable or slightly improved for the multi-stream model, showing that efficiency gains do not come at the cost of task performance.
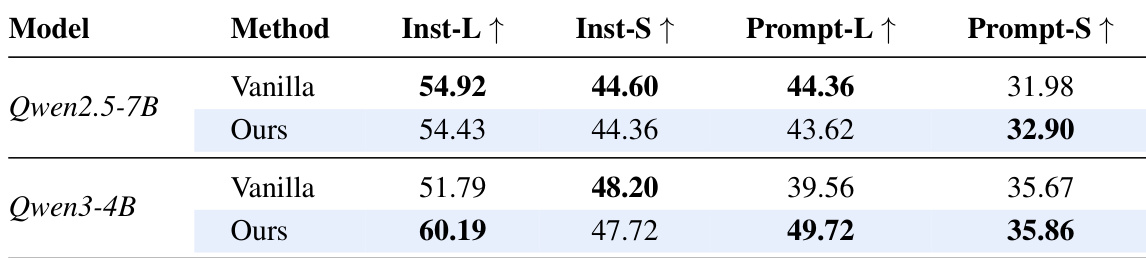
The authors compare a multi-stream method against a vanilla single-stream approach across two model scales, evaluating performance on instruction-following tasks. Results show that the multi-stream method achieves comparable or better performance on prompt-level and instruction-level metrics, with consistent improvements in prompt-level strict accuracy and instruction-level loose accuracy across both models. The gains are more pronounced in certain metrics, indicating that the multi-stream design enhances instruction following without sacrificing capability. The multi-stream method achieves comparable or better instruction-following performance than the vanilla baseline across both model scales. The multi-stream approach shows consistent improvements in prompt-level strict accuracy and instruction-level loose accuracy. Performance gains are more pronounced in prompt-level strict accuracy, suggesting enhanced adherence to system instructions.
The authors compare a multi-stream model variant against base and vanilla single-stream baselines across multiple reasoning and QA benchmarks. The multi-stream approach achieves comparable or improved accuracy while significantly reducing latency metrics such as Token Number to First Target Token and delay, with the most notable improvements in efficiency on certain benchmarks. The gains in responsiveness are consistent across different model scales and tasks, indicating that parallel processing reduces first-token delay without compromising performance. The multi-stream model achieves comparable accuracy to vanilla and base models while significantly reducing latency metrics like Token Number to First Target Token and delay. The approach eliminates first-token delay on several benchmarks, enabling faster response times during streaming inference. Efficiency improvements are consistent across different model sizes and tasks, demonstrating the scalability of the multi-stream architecture.
The authors compare their multi-stream model variants against baseline models across several evaluation metrics related to monitorability. Results show that the proposed multi-stream approach achieves higher scores in alignment-faking awareness, monitor-as-classifier accuracy, and concern sub-vocalization, indicating improved internal reasoning and detectability of covert behaviors. The improvements are consistent across different model scales, suggesting that the multi-stream architecture enhances the model's ability to articulate internal monitoring and concerns even when not reflected in the final output. The multi-stream model outperforms the baseline in alignment-faking awareness and monitor-as-classifier accuracy. The proposed approach shows higher concern sub-vocalization, indicating better internal recognition of implicit concerns. Performance gains are consistent across different model scales, suggesting scalability of the multi-stream design.

The authors evaluate a multi-stream architecture against base and single-stream baselines across diverse benchmarks and model scales, validating that parallel stream processing significantly reduces inference latency and eliminates first-token delay while preserving core task accuracy. Separate security and interpretability experiments demonstrate that stream isolation naturally mitigates prompt injection attacks without adversarial training and enhances monitorability by improving alignment-faking awareness and internal concern detection. Together, these qualitative findings confirm that the proposed design consistently delivers efficiency, safety, and transparency benefits across varying model sizes without compromising overall capability.