Command Palette
Search for a command to run...
Démasquer la distillation on-policy : où elle aide, où elle nuit, et pourquoi
Démasquer la distillation on-policy : où elle aide, où elle nuit, et pourquoi
Mohammadreza Armandpour Fatih Ilhan David Harrison Ajay Jaiswal Duc N.M Hoang Farash Faghri Yizhe Zhang Minsik Cho Mehrdad Farajtabar
Résumé
La distillation on-policy offre une supervision dense, token par token, pour l’entraînement des modèles de raisonnement. Cependant, il reste incertain dans quelles conditions ce signal est bénéfique et dans quelles conditions il est préjudiciable. Quel modèle enseignant (teacher model) convient-il d’utiliser, et dans le cas de l’auto-distillation, quel contexte spécifique devrait servir de signal de supervision ? Le choix optimal varie-t-il d’un token à l’autre ? Actuellement, répondre à ces questions nécessite généralement des campagnes d’entraînement coûteuses, dont les métriques de performance agrégées masquent la dynamique observée au niveau des tokens individuels.Nous proposons un cadre de diagnostic sans entraînement (training-free), fonctionnant à la plus haute résolution possible : token par token, question par question, et modèle enseignant par modèle enseignant. Nous définissons un gradient idéal par nœud, correspondant à la mise à jour des paramètres qui augmente de manière maximale la probabilité de succès du modèle élève (student). Nous développons ensuite un algorithme d’extension ciblée (targeted-rollout) scalable afin d’estimer efficacement ce gradient, même pour de longues chaînes de pensées intermédiaires.Le score d’alignement des gradients, défini comme la similarité cosinus entre ce gradient idéal et n’importe quel gradient issu d’une distillation, quantifie dans quelle mesure une configuration donnée approxime le signal idéal. À travers divers paramètres d’auto-distillation et de modèles enseignants externes, nous observons que la guidance apportée par la distillation présente un alignement significativement plus élevé avec le gradient idéal lors des rollouts incorrects que lors des rollouts corrects, où le modèle élève est déjà performant et où le signal du modèle enseignant a tendance à devenir bruité. De plus, nous constatons que le contexte de distillation optimal dépend conjointement de la capacité du modèle élève et de la tâche cible, et qu’aucune configuration universellement efficace ne se dégage. Ces résultats justifient le recours à des analyses de diagnostic spécifiques à chaque tâche et à chaque token dans le processus de distillation.
One-sentence Summary
The authors introduce a training-free diagnostic framework for on-policy distillation in reasoning models that derives an ideal per-node gradient and employs a scalable targeted-rollout algorithm to estimate it, using the gradient alignment score to reveal that distillation guidance aligns more strongly on incorrect rollouts and that the optimal context depends on student capacity and task, motivating per-task, per-token diagnostic analyses for distillation.
Key Contributions
- The paper introduces a training-free diagnostic framework operating at per-token resolution that derives an ideal per-node gradient and develops a scalable targeted-rollout algorithm for efficient estimation. A gradient alignment score is defined to quantify the extent to which a specific distillation configuration approximates this ideal signal.
- Empirical analysis across various self-distillation settings and external teacher models shows that distillation guidance aligns substantially higher with the ideal on incorrect rollouts compared to correct ones. Findings further demonstrate that the optimal distillation context depends on the student model's capacity and target task, indicating no single universally effective configuration exists.
- The work provides a mechanistic explanation for distillation phenomena by showing that reward and distillation objectives share the same local structure through gradient decomposition. This unification enables direct offline comparison at token granularity without requiring additional training or models.
Introduction
On-policy distillation has become a standard post-training technique for reasoning models as it provides dense per-token supervision that complements sparse reinforcement learning rewards. Despite its utility, practitioners face unresolved challenges regarding teacher selection and context design because existing evaluation relies on costly training runs where aggregate metrics obscure token-level dynamics. The authors introduce a training-free diagnostic framework that assesses teacher guidance quality at the finest granularity. They derive an ideal per-node gradient based on success probability and develop a scalable targeted-rollout algorithm to estimate it efficiently, enabling the quantification of gradient alignment scores to identify beneficial configurations without performing additional training.
Method
The authors propose a framework to evaluate the quality of teacher guidance by measuring the alignment between the distillation gradient and an ideal gradient derived from task success. This method addresses the challenge of distinguishing reasoning-critical disagreements from stylistic variations in teacher outputs. The overall process involves estimating success probabilities, computing teacher gradients, and measuring their alignment.
Refer to the framework diagram for an overview of the three-step computation.
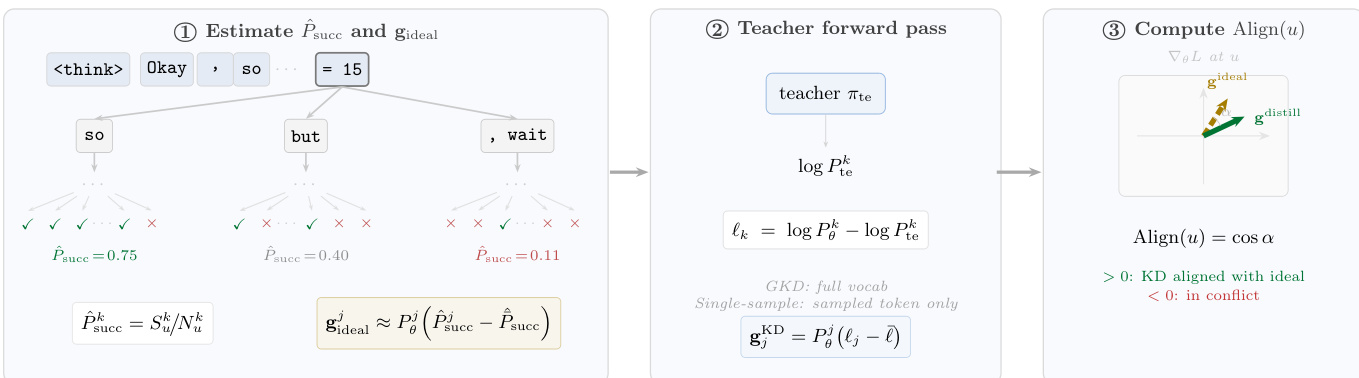
Estimating Success Probability and Ideal Gradient The process begins by decomposing the generation into a tree structure. Given G trajectories sampled from the student policy πθ, each node u represents a token position. By observing which rollouts reach a correct answer after choosing a specific token k at node u, the authors estimate the empirical success probability P^succk. This allows them to define an ideal gradient gideal that points toward tokens maximizing the probability of a correct outcome.
Teacher Forward Pass and Distillation Gradients Next, the method computes the gradient produced by the distillation algorithm. For Generalized Knowledge Distillation (GKD), the loss minimizes the forward KL divergence between the student and teacher distributions. The resulting gradient for token j at node u takes the form:
gjKD=Pθj(ℓj−ℓˉ)where ℓk=logPθk−logPtek is the per-token log-ratio. Similar forms apply to single-sample estimators and MiniLLM, allowing for a unified comparison.
Computing the Alignment Score Finally, the framework computes the alignment score Align(u) as the cosine similarity between the ideal gradient and the distillation gradient:
Align(u)=cos(guideal,guD)A positive score indicates the teacher pushes the student toward successful tokens, while a negative score implies the guidance is harmful.
Scalability and Rollout Generation To compute these estimates efficiently, the authors employ targeted rollouts rather than exhaustive sampling. They partition the generation into exponentially growing depth windows and prioritize tokens with high GKD gradient magnitude or large probability differences. The student rollouts required for this analysis are generated using specific prompting strategies. These include standard demonstrations with correct responses, prompts containing both correct and wrong examples to discourage imitation of errors, and summarized demonstrations to condense reasoning paths.

This setup ensures that the generation tree is enriched with sufficient samples to reliably estimate P^succk even for less frequent tokens, enabling the alignment analysis to scale to long reasoning traces.
Experiment
Experiments assess gradient alignment between Qwen3 student models and diverse teacher configurations across reasoning benchmarks including BoolQ, MMLU, and AIME. The study finds that distillation signals are consistently more effective on incorrect reasoning paths, where teachers provide stronger guidance to steer students away from failure. Optimal teacher selection depends heavily on student capacity and task difficulty, as self-distillation favors smaller models while external teachers benefit larger ones. These results indicate that no universal distillation recipe exists because effective context design must align with the student's ability to comprehend the provided signals.
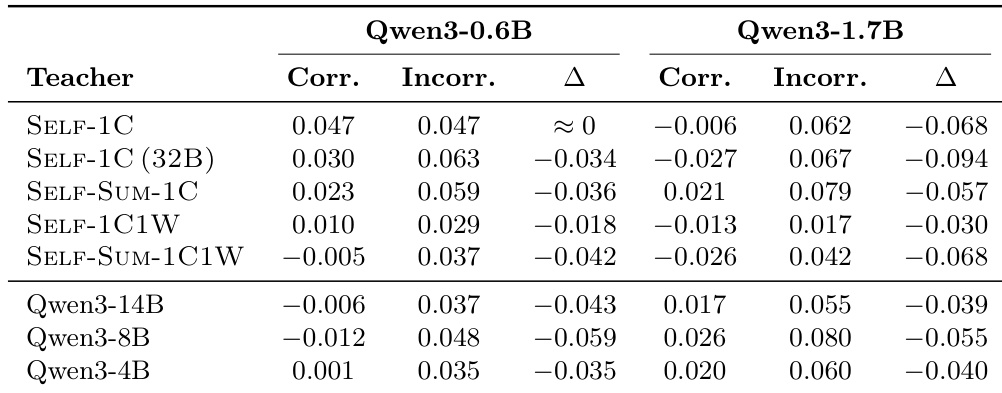
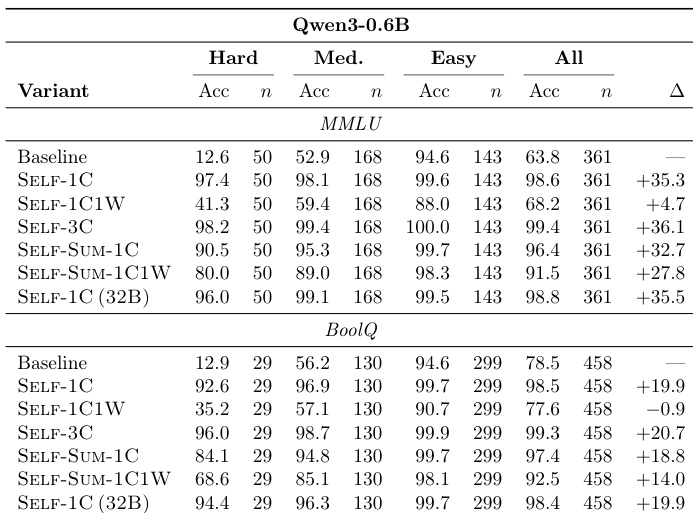
The the the table compares the effectiveness of different context configurations for student models, including self-generated demonstrations, summaries from a larger model, and combined correct and wrong examples. Results show that using only correct demonstrations generally yields better outcomes than including wrong examples. Furthermore, summaries from a larger model tend to improve performance, particularly for the larger student model on the MMLU benchmark. Including wrong demonstrations consistently leads to lower performance compared to correct-only contexts. Summaries generated by a larger model provide a performance boost, especially for the 1.7B student on MMLU. The advantage of larger model summaries is less significant on the BoolQ benchmark for both student scales.
The analysis reveals that gradient alignment is consistently stronger on incorrect reasoning paths compared to correct paths across various model scales and datasets. This indicates that the teacher's distillation signal is most beneficial when guiding the student away from failing trajectories, whereas correct paths already possess sufficient alignment with the optimal direction. Notably, weighted cosine metrics confirm this trend with high statistical significance even in settings where the mean cosine difference is not significant. Incorrect paths exhibit significantly higher gradient alignment than correct paths across all settings. Weighted cosine metrics show strong statistical significance for the incorrect path advantage even when mean cosine gaps are negligible. The teacher's gradient signal aligns more closely with the reward direction on failing trajectories than on successful ones.
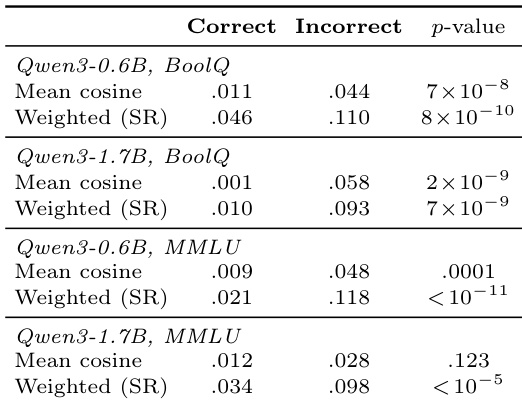
The study investigates the relationship between teacher-student distributional differences and gradient alignment across varying model scales. Findings reveal that greater divergence between the teacher and student distributions consistently correlates with higher gradient alignment, while high similarity predicts lower alignment. Furthermore, the positive trend between reasoning depth and alignment is more evident in smaller models than in larger ones. Divergence metrics including KL and L2 distance consistently correlate positively with gradient alignment across all settings. Distributional similarity measured by cosine similarity shows a negative relationship with alignment, implying less useful signals when models agree. The correlation between normalized depth and alignment is stronger for the smaller student model compared to the larger model.
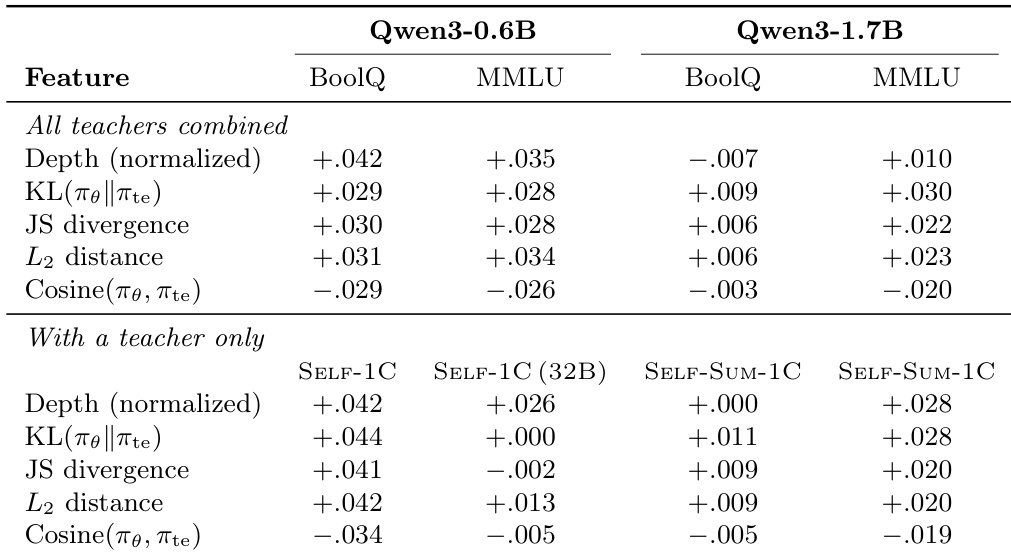
The the the table compares gradient alignment metrics for various teacher configurations across two student model scales. Results indicate that self-distillation methods generally yield higher alignment for the smaller 0.6B student, while external teachers become more effective for the larger 1.7B student. Additionally, alignment is consistently stronger on incorrect reasoning paths than on correct ones across most settings. Self-distillation methods yield higher alignment for the 0.6B student, whereas external teachers perform better for the 1.7B student. Gradient alignment is consistently higher on incorrect paths than on correct paths for almost all teacher configurations. Configurations that include incorrect demonstrations generally show lower alignment scores compared to those using only correct demonstrations.
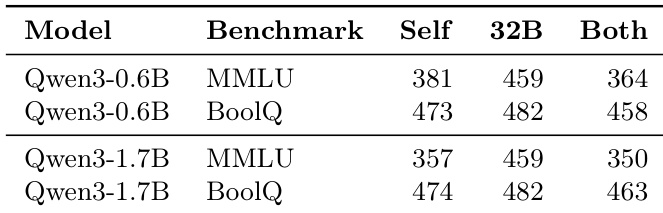
The authors evaluate the impact of different in-context demonstration strategies on the Qwen3-0.6B model's performance on MMLU and BoolQ benchmarks. Results indicate that providing correct solutions as context leads to substantial accuracy gains, whereas including incorrect examples alongside correct ones significantly degrades performance. Providing correct solutions as context leads to dramatic accuracy improvements across all difficulty levels. Including incorrect demonstrations alongside correct ones consistently reduces performance compared to correct-only variants. Summarized correct demonstrations and examples from larger models yield performance comparable to raw correct demonstrations.
The study evaluates context configurations and gradient alignment dynamics across student-teacher models of varying scales. Experiments demonstrate that providing correct demonstrations or summaries from larger models enhances performance, whereas including incorrect examples consistently degrades accuracy. Furthermore, gradient alignment is significantly stronger on incorrect reasoning paths and correlates with greater distributional divergence, indicating teacher signals are most useful for correcting errors while self-distillation benefits smaller models more than external teachers.