Command Palette
Search for a command to run...
TMAS : Mise à l'échelle du calcul pendant le test grâce à la synergie entre agents
TMAS : Mise à l'échelle du calcul pendant le test grâce à la synergie entre agents
George Wu Nan Jing Qing Yi Chuan Hao Ming Yang Feng Chang Yuan Wei Jian Yang Ran Tao Bryan Dai
Résumé
Le test-time scaling (mise à l’échelle lors de l’inférence) s’est imposé comme un paradigme efficace pour améliorer la capacité de raisonnement des grands modèles de langage (LMM/LLM) en allouant des ressources de calcul supplémentaires lors de la phase d’inférence. Les approches structurées récentes ont进一步 avancé ce paradigme en organisant l’inférence autour de multiples trajectoires, de cycles d’affinement et de rétroactions basées sur la vérification. Toutefois, les méthodes existantes de test-time scaling structuré coordonnent faiblement les trajectoires de raisonnement parallèles ou s’appuient sur des informations historiques bruitées sans décider explicitement de ce qui doit être conservé et réutilisé, ce qui limite leur capacité à équilibrer exploration et exploitation.Dans cet article, nous proposons TMAS, un cadre de mise à l’échelle du calcul lors de l’inférence fondé sur la synergie multi-agents. TMAS organise l’inférence comme un processus collaboratif impliquant des agents spécialisés, permettant un flux d’information structuré au sein des agents, des trajectoires et des itérations d’affinement. Pour soutenir une collaboration inter-trajectoires efficace, TMAS introduit des mémoires hiérarchiques : la « banque d’expérience » réutilise les conclusions intermédiaires fiables de bas niveau ainsi que les rétroactions locales, tandis que la « banque de directives » enregistre les stratégies de haut niveau précédemment explorées afin d’orienter les exécutions ultérieures vers des patterns de raisonnement moins redondants.Par ailleurs, nous concevons un schéma d’apprentissage par renforcement à récompense hybride, spécifiquement adapté à TMAS, qui préserve conjointement les capacités de raisonnement fondamentales, améliore l’utilisation des expériences acquises et encourage l’exploration de stratégies de solution nouvelles, au-delà de celles déjà tentées. De nombreuses expériences menées sur des benchmarks de raisonnement difficiles montrent que TMAS réalise une mise à l’échelle itérative plus performante que les références existantes en test-time scaling, tandis que l’entraînement avec une récompense hybride améliore davantage l’efficacité et la stabilité de cette mise à l’échelle au fil des itérations. Le code et les données sont disponibles à l’adresse suivante : https://github.com/george-QF/TMAS-code.
One-sentence Summary
The authors propose TMAS, a multi-agent synergy framework that scales test-time compute for large language model reasoning by coordinating specialized agents across inference trajectories, employing hierarchical experience and guideline banks to explicitly retain reliable intermediate conclusions and high-level strategies that balance exploration and exploitation during iterative refinement.
Key Contributions
- This work proposes TMAS, a framework for scaling test-time compute via multi-agent synergy that explicitly organizes information flow across agents, trajectories, and iterations. The framework introduces hierarchical memories, utilizing an experience bank to reuse reliable low-level signals and a guideline bank to record high-level strategies for balancing exploitation and exploration.
- A tailored hybrid reward reinforcement learning scheme optimizes three complementary objectives: preserving basic reasoning competence, enhancing experience utilization, and encouraging exploration beyond previously attempted strategies. This training design enables the model to effectively exploit the collaborative memory structure while maintaining sufficient exploration during iterative refinement.
- Extensive experiments on challenging reasoning benchmarks demonstrate that TMAS achieves stronger iterative scaling performance compared to existing test-time scaling baselines. The results further indicate that the hybrid reward scheme improves scaling effectiveness and stability across refinement rounds.
Introduction
Test-time scaling improves large language model reasoning by allocating additional computation during inference, a capability that has become essential for tackling complex analytical tasks. Despite recent advances, existing structured methods either weakly coordinate parallel reasoning trajectories or rely on unfiltered historical data, which fails to effectively balance exploration with exploitation and often propagates noisy signals. The authors leverage a multi-agent synergy framework called TMAS to restructure inference as a coordinated iterative process. They introduce hierarchical memory banks to separately preserve reliable intermediate conclusions and high-level exploration strategies, while a custom hybrid reward reinforcement learning scheme trains the model to efficiently reuse shared experience and pursue diverse solution paths.
Dataset
- Dataset Composition & Sources: The authors construct a cold-start training pool by combining open-source RL datasets (DAPO and Skywork-OR1) with two mathematical reasoning benchmarks (IMO-AnswerBench and HLE-Math-100).
- Subset Details & Filtering: The training data is organized into three task-specific subsets: 1.6K instances for Experience Utilization, 0.6K for Novel Strategy Exploration, and 2.2K for Standard Correctness Reward. For evaluation, they filter the original 400-problem IMO-AnswerBench using Qwen3-4B-Thinking-2507, retaining only the 50 problems solved correctly fewer than two times across eight independent inference runs. The HLE-Math-100 dataset is adopted directly from the RSE release without modification.
- Training Usage & Context Processing: To align with hybrid RL objectives, the team uses DeepSeek-V3.2 as a teacher model to simulate iterative inference on each problem. They generate multi-round rollout histories and distill these trajectories into historical context, experience banks, and guideline banks. This distillation process creates contextualized training examples that initialize the model before RL fine-tuning.
- Evaluation & Metadata Setup: During assessment, DeepSeek-V3.2 serves as an LLM-as-Judge to verify mathematical equivalence between generated solutions and reference answers. The authors run four independent judgment passes per solution, apply strict equivalence rules that ignore formatting variations and focus solely on final results, and compute a final Pass@1 accuracy by averaging the success rates across all judge runs.
Method
The TMAS framework orchestrates multi-agent collaboration to scale test-time compute through iterative reasoning, integrating parallel exploration with sequential exploitation. The overall system operates in an iterative pipeline where multiple solution trajectories are generated in parallel at each iteration, verified, summarized, and used to update two complementary memory banks. This process enables coordinated refinement and non-redundant exploration across iterations.
At each iteration, the system begins with a problem Q and leverages two memory banks: the experience bank Et−1, which stores low-level, trajectory-specific reasoning signals such as verified intermediate conclusions and error-avoidance heuristics, and the guideline bank Gt−1, which holds high-level solution strategies and structural insights from prior exploration. These memory banks condition the solution generation process, balancing exploitation of proven knowledge with exploration of novel paths.
The core of the inference process is driven by five specialized agents. The solution agent Asol generates N candidate solution trajectories {ct,i}i=1N in parallel. This generation follows an ϵ-greedy strategy: with probability 1−ϵ, it exploits previous rollouts and experience by sampling from Asol(Q,Rt−1,Et−1); with probability ϵ, it explores new directions by sampling from Asol(Q,Gt−1), guided by the high-level strategies in the guideline bank. This mechanism directly coordinates exploration and exploitation.
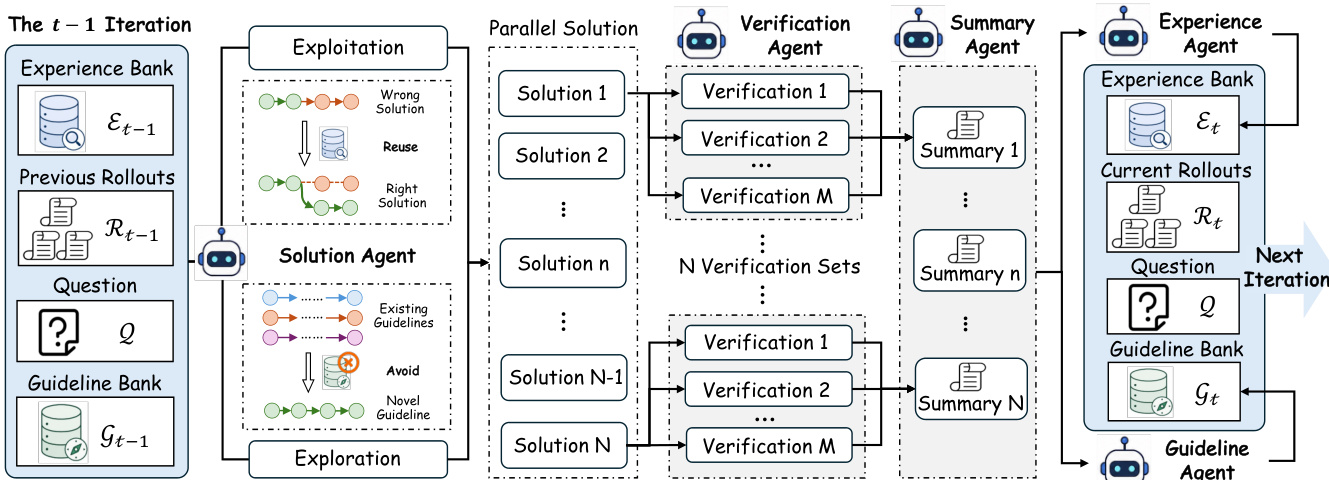
As shown in the figure below, each candidate solution ct,i is then independently verified by M verification agents, producing a verification set Vt,i. The verification outputs provide analytical feedback and a grading score for each step. A summary agent aggregates these results into a concise rollout-level summary st,i, which highlights validated reasoning and identifies logical flaws. The collection of all rollouts, Rt={(ct,i,st,i)}i=1N, serves as the input for the memory update phase.

Two parallel memory update agents operate on Rt. The experience agent Aexp extracts reusable low-level patterns, such as shared intermediate steps and common error pitfalls, to update the experience bank Et. The guideline agent Aguide abstracts the high-level solution approaches attempted across the rollouts to update the guideline bank Gt. This hierarchical memory structure serves as the communication substrate, allowing specialized agents to share local evidence and propagate global strategies, thereby converting independent parallel trajectories into a coordinated iterative reasoning process. The updated memory banks are carried forward to the next iteration, conditioning the solution agent's future actions.
Experiment
Evaluated on challenging mathematical reasoning benchmarks against established test-time scaling baselines, the primary experiments validate TMAS's superior capacity to sustain iterative performance gains without the plateauing observed in competing methods. Component ablations and sensitivity analyses further validate the complementary roles of strategic guidelines and historical experience, while confirming that moderate exploration and verification budgets optimally balance discovery with exploitation. Additional studies demonstrate that hybrid reward reinforcement learning stabilizes early progress and mitigates late-stage degradation, though they also reveal that a shared capability boundary between generation and verification ultimately constrains scaling on the most difficult problems.
The authors evaluate TMAS on two reasoning benchmarks, demonstrating that it achieves stronger iterative scaling compared to baseline methods. Results show that TMAS continues to improve with additional refinement rounds, outperforming other methods at later iterations. The proposed hybrid reward RL significantly enhances performance, particularly in later stages, and reduces the performance gap between smaller and larger base models. TMAS demonstrates superior iterative scaling, consistently improving with more refinement rounds and achieving the best late-stage performance. Hybrid reward RL training significantly enhances TMAS's scaling ability, leading to sustained improvements and reduced performance gaps between different model sizes. The synergy of experience and guideline modules is critical, as removing either degrades performance, with guidelines aiding early progress and experience supporting late-stage refinement.

The authors evaluate TMAS on two reasoning benchmarks, comparing its performance against several baselines and analyzing its iterative scaling behavior. Results show that TMAS consistently improves with additional refinement rounds and achieves the best late-stage performance, particularly when using a hybrid reward RL training approach. The ablation study reveals that both the guideline and experience modules contribute uniquely to iterative gains, with the full system outperforming variants missing either component. TMAS demonstrates stronger iterative scaling ability compared to baselines, continuing to improve as refinement rounds increase. Hybrid reward RL significantly enhances iterative scaling, leading to superior performance and reduced performance gaps between smaller and larger models. The guideline and experience modules in TMAS provide complementary benefits, with each contributing uniquely to performance gains across different stages of refinement.

The authors evaluate TMAS on two reasoning benchmarks, demonstrating its superior iterative scaling ability compared to baseline methods. Results show that TMAS continues to improve with additional refinement rounds, achieving the best late-stage performance. The proposed hybrid reward RL significantly enhances iterative scaling, particularly by improving the performance of smaller models and mitigating performance degradation in later iterations. TMAS demonstrates stronger iterative scaling than baselines, continuing to improve with additional refinement rounds and achieving the best late-stage performance. Hybrid reward RL significantly amplifies iterative scaling, improving performance across all stages and mitigating degradation in later iterations. The integration of hybrid RL reduces the performance gap between smaller and larger models, enabling smaller models to approach the performance of larger ones through more effective iterative test-time computation.

The authors evaluate TMAS on two reasoning benchmarks, demonstrating that it achieves superior iterative scaling compared to baseline methods. Results show that TMAS continues to improve with additional refinement rounds, outperforming other methods in late-stage iterations. The integration of hybrid reward RL significantly enhances performance, particularly in later iterations, and reduces the performance gap between smaller and larger base models. TMAS shows stronger iterative scaling, continuing to improve with more refinement rounds while other methods plateau. Hybrid reward RL enhances TMAS performance, especially in later iterations, and reduces the gap between smaller and larger models. The model maintains consistent gains across iterations, indicating effective use of test-time computation.

The authors evaluate TMAS on two reasoning benchmarks, demonstrating that it achieves superior performance compared to baseline methods, particularly in later iterations. Results show that TMAS maintains strong iterative scaling, with performance continuing to improve as refinement rounds increase, unlike other methods that plateau or degrade. The integration of hybrid reward RL significantly enhances the model's ability to sustain improvements over multiple iterations. The authors also conduct ablation studies, revealing that both the experience and guideline modules contribute uniquely to the system's effectiveness, with their combined use yielding the best results. TMAS demonstrates stronger iterative scaling ability compared to baselines, consistently improving performance across refinement rounds. Hybrid reward RL significantly enhances iterative scaling, leading to sustained performance gains and mitigating degradation in later iterations. The experience and guideline modules in TMAS contribute complementary benefits, with their combined use resulting in the best overall performance.
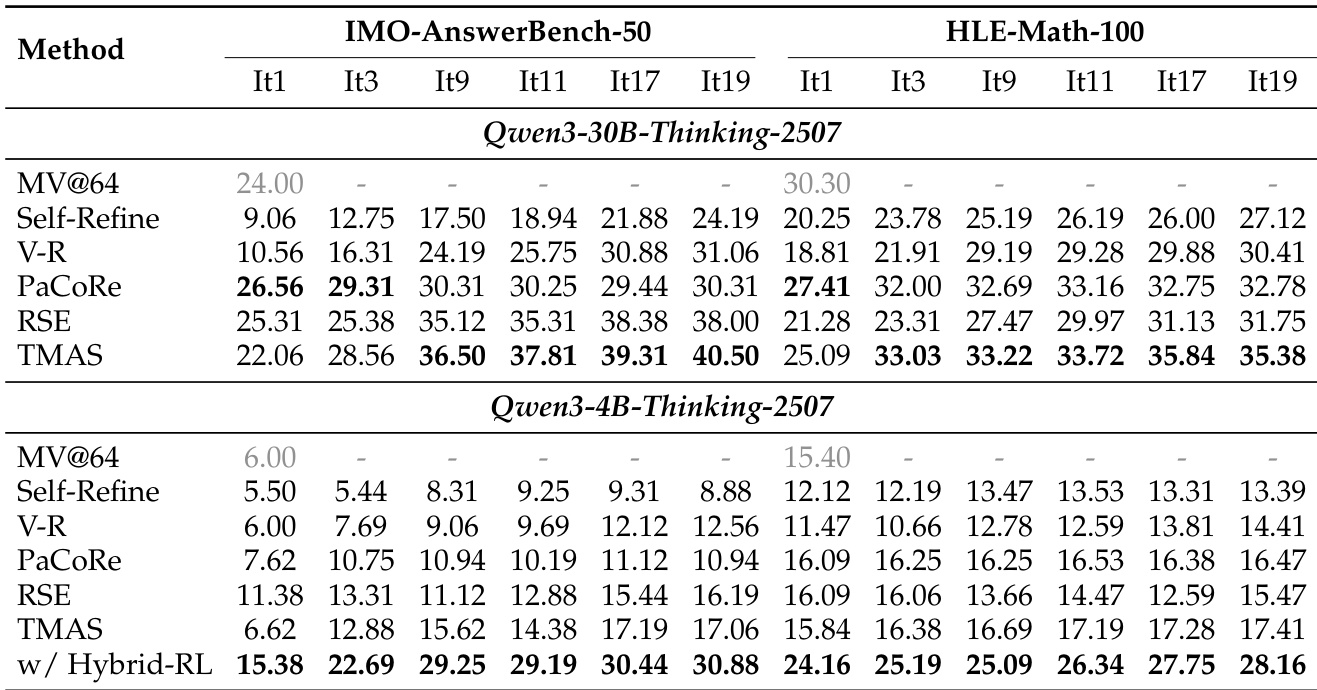
Evaluated on two reasoning benchmarks, the experiments validate TMAS's superior iterative scaling against baseline methods, demonstrating consistent performance gains across multiple refinement rounds without the plateauing observed in competing approaches. The integration of hybrid reward reinforcement learning significantly amplifies these sustained improvements while effectively narrowing the performance gap between smaller and larger base models. Ablation studies further confirm the essential synergy between the guideline and experience modules, showing that their complementary contributions drive optimal early-stage guidance and late-stage refinement. Collectively, these findings establish TMAS as a robust framework that efficiently leverages test-time computation to achieve scalable and sustained reasoning improvements.