Command Palette
Search for a command to run...
Soohak : un benchmark conçu par des mathématiciens pour évaluer les capacités mathématiques de niveau recherche des LLMs
Soohak : un benchmark conçu par des mathématiciens pour évaluer les capacités mathématiques de niveau recherche des LLMs
Résumé
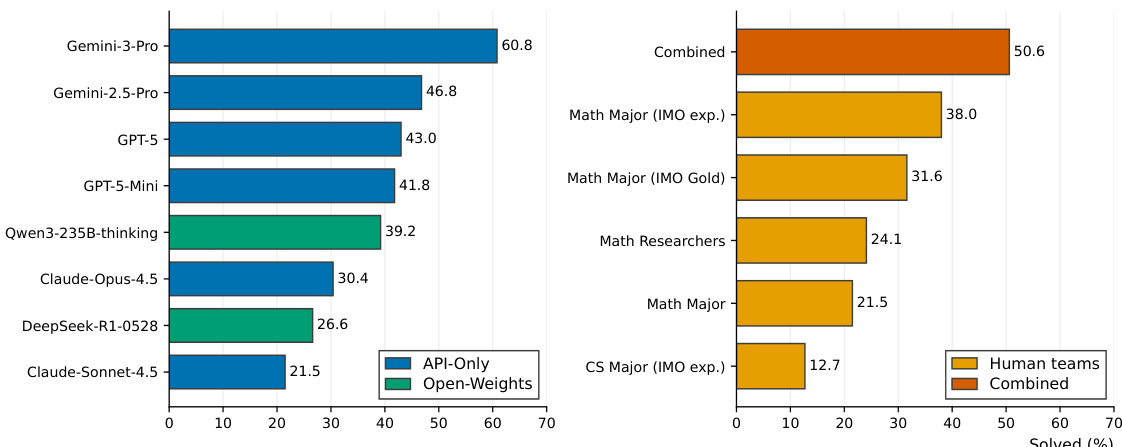
À la suite des performances de niveau médaille d’or obtenues par les grands modèles de langage (LLM) de pointe lors de l’Olimpiade Internationale de Mathématiques (IMO), la communauté scientifique cherche la prochaine cible significative et exigeante pour évaluer le raisonnement des LLM. Si les problèmes de type olympiade mesurent uniquement le raisonnement étape par étape, les problèmes de niveau recherche utilisent ce même raisonnement pour faire progresser les frontières de la connaissance mathématique elle-même, se révélant ainsi une alternative convaincante. Pourtant, les références d’évaluation en mathématiques de niveau recherche restent rares, car ce type de problèmes est difficile à collecter (par exemple, Riemann Bench et FrontierMath-Tier 4 en comptent respectivement 25 et 50). Afin de soutenir l’évaluation fiable des modèles de pointe de nouvelle génération, nous présentons Soohak, un benchmark composé de 439 problèmes nouvellement rédigés ex nihilo par 64 mathématiciens. Soohak comprend deux sous-ensembles. Sur le sous-ensemble Challenge, les modèles de pointe tels que Gemini-3-Pro, GPT-5 et Claude-Opus-4.5 atteignent respectivement 30,4 %, 26,4 % et 10,4 %, laissant une marge de progression substantielle, tandis que les modèles à poids ouverts de pointe, tels que Qwen3-235B, GPT-OSS-120B et Kimi-2.5, restent en dessous de 15 %. Il est à noter que, au-delà de la résolution standard de problèmes, Soohak introduit un sous-ensemble d’évaluation des refus, qui sonde une capacité intrinsèque à la recherche en mathématiques : reconnaître les problèmes mal posés et opter pour un refus plutôt que de produire des réponses confiantes mais non justifiées. Sur ce sous-ensemble, aucun modèle ne dépasse les 50 %, identifiant le refus comme une nouvelle cible d’optimisation que les modèles actuels ne traitent pas directement. Pour prévenir toute contamination des données, le jeu de données sera publié publiquement à la fin de l’année 2026, des évaluations de modèles étant disponibles sur demande dans l’intervalle.
One-sentence Summary
Authored from scratch by sixty-four mathematicians, SOOHAK is a 439-problem benchmark for evaluating research-level mathematical reasoning in large language models, featuring a Challenge subset that assesses advanced problem-solving on frontier architectures like Gemini-3-Pro, GPT-5, and Claude-Opus-4.5, and a Refusal subset that measures whether systems recognize ill-posed questions, thereby identifying refusal as a new optimization target that current models do not directly address.
Key Contributions
- The paper introduces SOOHAK, a benchmark of 439 research-level mathematics problems authored by 64 mathematicians to evaluate frontier language models on reasoning that advances mathematical knowledge.
- The benchmark incorporates a dedicated refusal subset that measures a model’s capacity to identify ill-posed problems and abstain from generating confident but unjustified answers, establishing a new dimension for assessing mathematical reliability.
- Evaluations on the challenge subset demonstrate that leading frontier models achieve 10.4% to 30.4% accuracy while open-weight systems score below 15%, and no model exceeds 50% on the refusal subset, providing concrete baselines and identifying refusal behavior as a new optimization target.
Introduction
Please provide the source text. Once shared, I will draft a concise background summary covering the technical context, prior limitations, and the authors’ main contribution from an explainer perspective.
Dataset
-
Dataset Composition and Sources
- The authors introduce SOOHAK, a contamination-resistant benchmark comprising 439 expert-authored mathematical problems, alongside a 702-item companion subset named SOOHAK-Mini.
- Data originates from 105 contributors across two channels: a primary submission system (86 contributors recruited via direct outreach and public applications) and a bulk purchase from the ScienceBench collection (19 contributors).
- Contributors span faculty, graduate students, postdocs, and undergraduates, with submissions covering algebra, number theory, combinatorics, analysis, geometry, topology, probability, and differential equations.
-
Key Details for Each Subset
- SOOHAK Challenge (340 items): Targets graduate-level and research-adjacent mathematics. Sourced from invited experts and supplemented with 112 bulk-purchased problems. Items must fail all large open models in the evaluation panel (e.g., gpt-oss-120B, Qwen3-235B, DeepSeek-R1).
- SOOHAK Refusal (99 items): Comprises ill-posed problems rejected during quality control due to contradictions, missing assumptions, or non-unique answers. Designed to test whether models recognize unanswerable prompts rather than generating confident but incorrect solutions.
- SOOHAK-Mini (702 items): A companion subset covering high-school olympiad through early graduate material. Items are filtered by requiring failure of both small open models (Qwen3-7B, OpenThinker3-7B) and mid-size open models (gpt-oss-20B, Qwen3-32B).
- All submissions undergo a five-stage pipeline including automated screening, dual human review, contributor opt-in, and strict originality verification. The authors explicitly banned contributors who attempted to submit AI-generated questions.
-
Data Usage and Processing
- The authors use the dataset exclusively for model evaluation and human baseline studies, with no training splits or mixture ratios applied. The full collection is temporarily embargoed until late 2026 to prevent contamination, with evaluation results provided upon request in the interim.
- Human baselines were established using five expert teams with varying backgrounds, including IMO medalists and published researchers, evaluated on a 79-problem subset to calibrate difficulty expectations.
- Quality control includes automated consistency checks, manual auditing of model-generated solutions against reference answers, and an external evaluation that flagged approximately 5% of items for potential ambiguity or errors.
-
Metadata Construction and Formatting Details
- Each problem is annotated with contributor-provided keywords and an LLM-assigned Mathematics Subject Classification (MSC) category generated by a GPT-5-mini classifier to standardize coverage statistics.
- Approximately 92% of items were originally written in English. The authors construct a parallel bilingual benchmark by translating all problems into Korean using a machine-translation workflow that preserves LaTeX formatting, followed by professional post-editing, terminology normalization, and independent quality assurance.
- Submissions are restricted to text-only LaTeX with explicit final answers and complete solutions. The final dataset is serialized in structured JSON format, with rigorous automated checks for formula equivalence and renderability.
Method
The authors leverage a structured, multi-phase pipeline to ensure the integrity and quality of the SOOHAK benchmark, beginning with individual submissions from contributors who provide original mathematical problems. Each submission undergoes a preliminary review to confirm compliance with key criteria, including the absence of ChatGPT usage, original production, and adherence to a copyright transfer agreement. This initial phase ensures that the source material is both authentic and legally permissible for use.
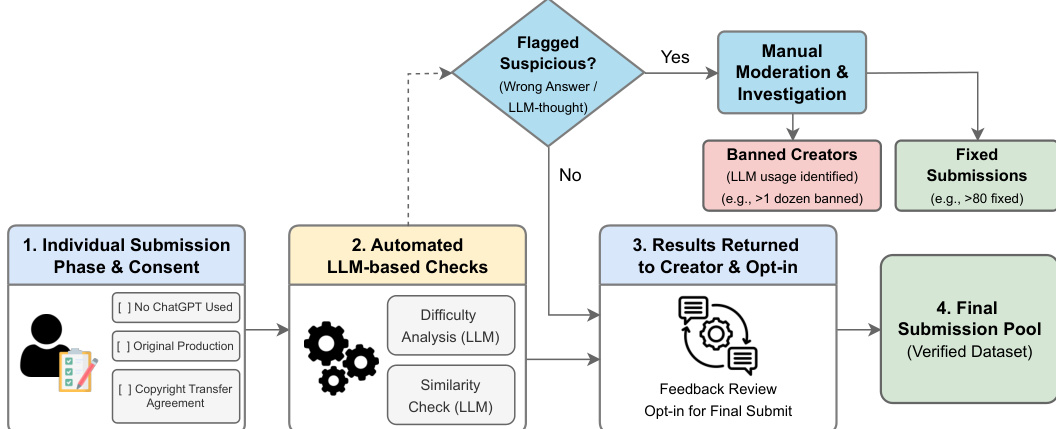
As shown in the figure below: the second phase employs automated, LLM-based checks to evaluate submissions. These checks include a difficulty analysis and a similarity check, both conducted using large language models. The difficulty analysis assesses the complexity of the problem, while the similarity check identifies potential overlaps with existing problems in public datasets, helping to minimize redundancy and contamination. These automated evaluations serve as a filter to streamline the dataset and enhance its novelty.
Submissions that pass the automated checks proceed to the third phase, where results are returned to the creators for review and optional feedback. This feedback mechanism allows contributors to refine their problems based on model responses and ensures that the final content aligns with intended difficulty and correctness. During this phase, a decision point determines whether the submission is flagged as suspicious—indicating a wrong answer or flawed reasoning. If flagged, the submission enters a manual moderation and investigation process, where human reviewers assess the issue. Submissions that are deemed to involve banned usage, such as repeated attempts by the same model or excessive reliance on LLMs, are categorized as banned creators and excluded. Otherwise, verified submissions are marked as fixed and integrated into the final submission pool.
The final phase consolidates all validated contributions into a verified dataset, which is then used for model evaluation. This rigorous workflow ensures that the benchmark maintains high standards of originality, difficulty, and reliability, supporting fair and meaningful comparisons across different models.
Experiment
The evaluation compares eleven closed and open-weight language models alongside human participants across three benchmark splits that validate baseline reasoning capability, frontier mathematical problem-solving, and carefulness on ill-posed prompts. Results indicate that while closed systems generally maintain an edge on complex problems, performance on difficult reasoning tasks scales predictably with both model size and extended test-time compute, whereas refusal behavior follows a separate pattern. Human evaluations reveal that contest-style training and time-optimized collaboration strategies drive performance more effectively than deep research expertise, highlighting a task-format mismatch for academic mathematicians. Ultimately, the study demonstrates that frontier mathematical competence depends on a combination of scaling compute, careful prompt handling, and specialized reasoning training rather than raw parameter count alone.
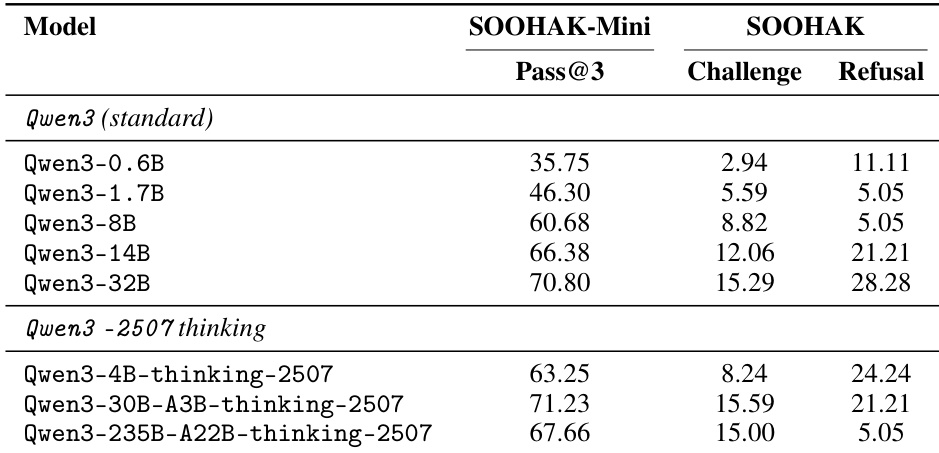
The the the table presents Pass@3 performance for the Qwen3 model family across different parameter sizes and configurations, comparing standard and thinking-tuned variants on the SOOHAK-Mini, Challenge, and Refusal benchmarks. Results show that larger models generally achieve higher scores, with the thinking-tuned versions exhibiting improved performance on SOOHAK-Mini and Challenge, though the largest model shows a regression in the standard variant. The Refusal scores remain low across all models, indicating limited ability to correctly refuse inappropriate queries. Larger Qwen3 models consistently achieve higher Pass@3 scores on SOOHAK-Mini and Challenge, with performance increasing as parameter size grows. The thinking-tuned variants of Qwen3 show improved performance on SOOHAK-Mini and Challenge compared to their standard counterparts, but the largest model exhibits a regression in the standard version. All models perform poorly on the Refusal benchmark, with scores remaining low and showing little improvement across different configurations.
The authors evaluate a range of language models and human participants on a mathematical reasoning benchmark, comparing performance across different model types and human teams. Results show that closed models generally outperform open-weight models on reasoning tasks, while open-weight models like GLM-5 excel on refusal tasks. Human teams, particularly those with olympiad experience, achieve strong performance, with combined coverage surpassing individual models, though some models exceed the best human team coverage. Closed models achieve higher reasoning performance than open-weight models on challenging mathematical problems. Open-weight models show strong performance on refusal tasks, with GLM-5 leading among all evaluated models. Human teams with olympiad experience perform strongly, and their combined coverage exceeds that of any single model or team.
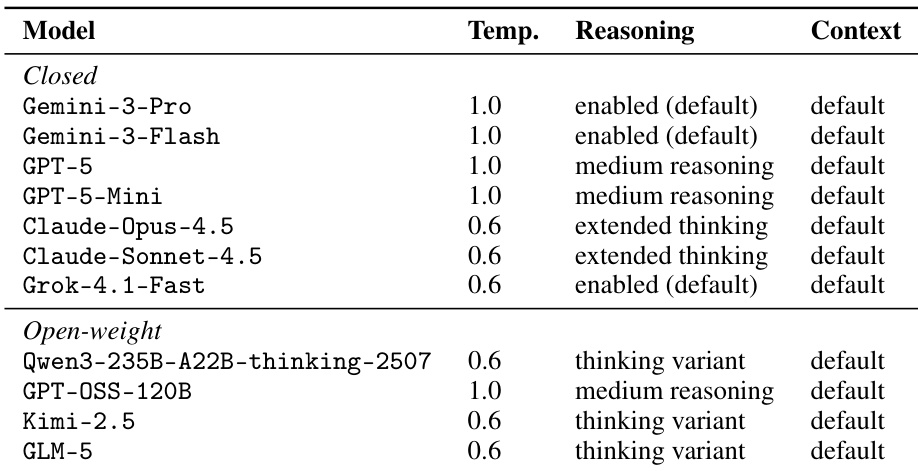
The authors evaluate a set of closed and open-weight language models on a benchmark that includes reasoning and refusal tasks, using metrics such as avg@3 and pass@3 to assess performance. The models are evaluated under standardized decoding settings, with variations in reasoning effort and context length explored for some systems. Results show that closed models generally outperform open-weight models on reasoning tasks, while open-weight models exhibit stronger refusal behavior, indicating different strengths across task types. The evaluation reveals that performance varies significantly by mathematical subfield, with top models differing by domain, and that increasing model size and test-time compute improves reasoning performance, though not uniformly across all tasks. Closed models achieve higher reasoning performance than open-weight models, but open-weight models show stronger refusal behavior. Performance improves with larger model size and extended context, particularly on reasoning tasks, but not uniformly across all models. Top-performing models vary by mathematical subfield, with no single model dominating all areas, indicating diverse strengths across domains.
The authors evaluate a range of language models on the SOOHAK benchmark, which includes two main components: SOOHAK-Mini and SOOHAK, with the latter further divided into Challenge and Refusal subtasks. Results show that closed-frontier models generally outperform open-weight models on SOOHAK-Mini and Challenge, while open-weight models, particularly GLM-5, achieve the highest scores on the Refusal subtask. The evaluation reveals distinct performance patterns across model families and subfields, with some models excelling in specific mathematical domains while others show broader but less specialized capabilities. Closed-frontier models achieve higher performance on SOOHAK-Mini and Challenge compared to open-weight models, with GPT-5 leading in both categories. Open-weight models, especially GLM-5, outperform all others on the Refusal subtask, indicating stronger refusal capabilities. Performance varies significantly across mathematical subfields, with different models leading in different areas, suggesting specialized strengths rather than uniform superiority.
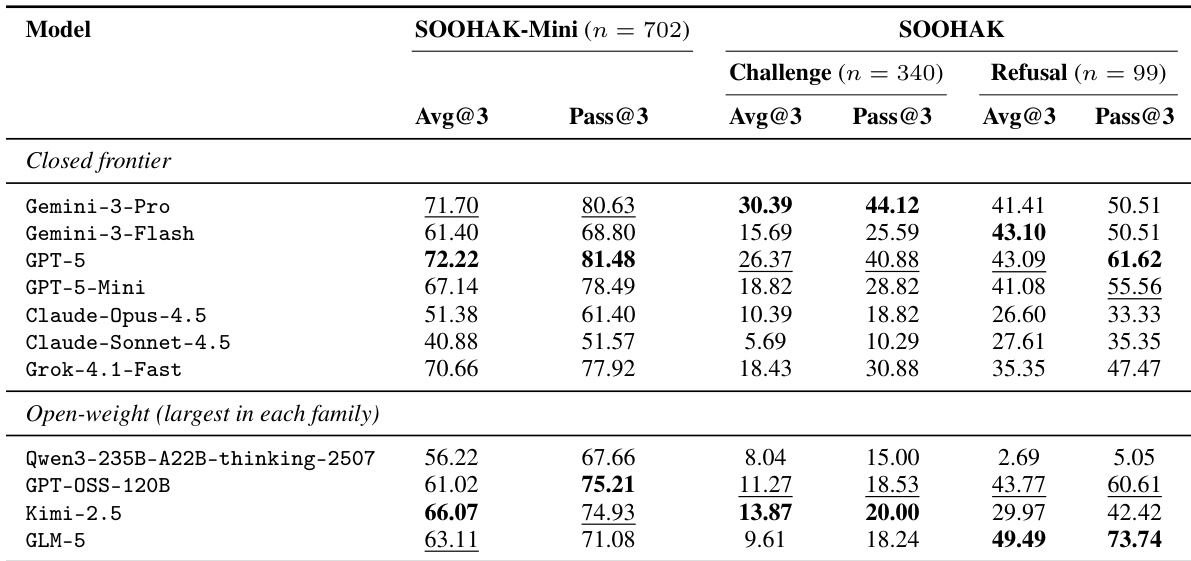
The authors evaluate a range of language models on the SOOHAK benchmark, focusing on reasoning and refusal capabilities across different model families and configurations. Results show that closed models generally outperform open-weight models on the Challenge split, while open-weight models like GLM-5 achieve higher performance on the Refusal split. Performance scales with model size and test-time compute, particularly on the Challenge split, but Refusal performance does not follow the same scaling patterns. The evaluation also reveals that model strengths vary significantly by mathematical subfield, with different models leading in different areas. Closed models achieve higher performance than open-weight models on the Challenge split, but open-weight models like GLM-5 lead on the Refusal split. Performance on the Challenge split scales with model size and test-time compute, while Refusal performance does not show consistent scaling. Model strengths vary across mathematical subfields, with different models leading in different areas based on the problem type.
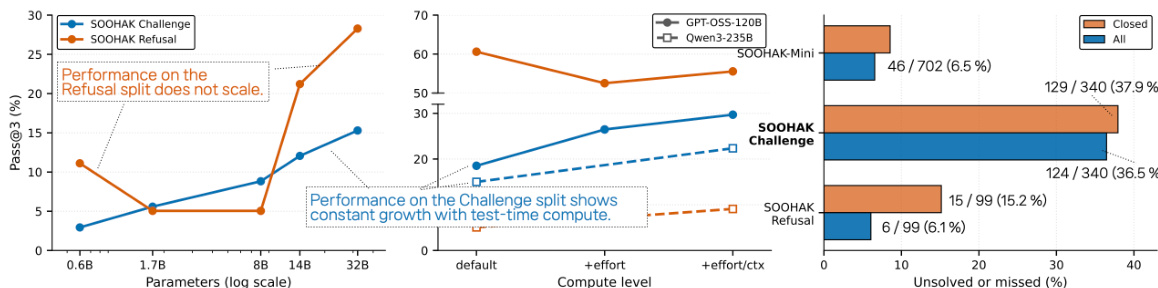
The evaluation compares closed and open-weight language models, along with specialized human teams, across mathematical reasoning and refusal benchmarks using standardized decoding and varied computational settings. The results indicate that frontier closed models consistently outperform open-weight systems on complex reasoning tasks, whereas open-weight architectures demonstrate notably stronger refusal capabilities. Reasoning performance scales reliably with increased model size and test-time compute, but refusal behavior follows different patterns that do not consistently improve with scale. Additionally, model strengths are highly domain-specific across mathematical subfields, revealing that specialized capabilities outweigh uniform superiority, while experienced human teams frequently match or exceed individual model coverage.