Command Palette
Search for a command to run...
Relit-LiVE : Relumière la vidéo en apprenant conjointement la vidéo d'environnement
Relit-LiVE : Relumière la vidéo en apprenant conjointement la vidéo d'environnement
Weiqing Xiao Hong Li Xiuyu Yang Houyuan Chen Wenyi Li Tianqi Liu Shaocong Xu Chongjie Ye Hao Zhao Beibei Wang
Résumé
Titre : Relit-LiVE : Un cadre de re-éclairage vidéo basé sur la diffusion neuronaleRésumé : Les avancées récentes ont montré que les modèles de diffusion vidéo à grande échelle peuvent être réutilisés comme des rendus neuronaux en décomposant d'abord les vidéos en représentations intrinsèques de la scène, puis en effectuant un rendu direct sous un éclairage nouveau. Bien que prometteuse, cette approche repose fondamentalement sur une décomposition intrinsèque précise, qui reste peu fiable pour les vidéos du monde réel et conduit souvent à des apparences déformées, des matériaux altérés et des artefacts temporels accumulés lors du re-éclairage. Dans ce travail, nous présentons Relit-LiVE, un nouveau cadre de re-éclairage vidéo qui produit des résultats physiquement cohérents et stables dans le temps, sans nécessiter de connaissance préalable de la pose de la caméra. Notre idée clé consiste à introduire explicitement des images de référence brutes dans le processus de rendu, permettant au modèle de récupérer des indices de scène critiques qui sont inévitablement perdus ou corrompus dans les représentations intrinsèques. De plus, nous proposons une nouvelle formulation de prédiction de vidéos d'environnement qui génère simultanément des vidéos re-éclairées et des cartes d'environnement par image, alignées avec chaque point de vue de la caméra, au sein d'un seul processus de diffusion. Cette prédiction conjointe impose une forte alignement géométrie-éclairage et prend naturellement en charge l'éclairage dynamique et le mouvement de la caméra, améliorant significativement la cohérence physique du re-éclairage vidéo tout en assouplissant l'exigence d'une pose de caméra connue par image. Des expériences extensives démontrent que Relit-LiVE surpasse constamment les méthodes de pointe en matière de re-éclairage vidéo et de rendu neuronal sur des benchmarks synthétiques et du monde réel. Au-delà du re-éclairage, notre cadre prend naturellement en charge une large gamme d'applications en aval, notamment le rendu au niveau de la scène, l'édition des matériaux, l'insertion d'objets et le re-éclairage vidéo en streaming. Le projet est disponible à l'adresse https://github.com/zhuxing0/Relit-LiVE.
One-sentence Summary
RELIT-LIVE is a diffusion-based video relighting framework that jointly generates relit videos and per-frame environment maps in a single process while leveraging raw reference images to bypass unreliable intrinsic decomposition and eliminate the need for known camera poses, thereby producing physically consistent and temporally stable results that support dynamic lighting and camera motion, with extensive experiments demonstrating consistent superiority over state-of-the-art video relighting and neural rendering methods across synthetic and real-world benchmarks.
Key Contributions
- This work introduces RELiT-LiVE, a video relighting framework that produces physically consistent and temporally stable results without requiring prior camera pose estimation.
- The framework explicitly incorporates raw reference images into the diffusion rendering pipeline to recover scene cues lost during intrinsic decomposition. A novel environment video prediction formulation simultaneously generates relit videos and per-frame environment maps aligned with camera viewpoints in a single diffusion process, enforcing strong geometric-illumination alignment.
- Complementary training strategies utilizing latent-space interpolation and cycle-consistent self-supervised illumination learning enhance generalization and temporal lighting coherence. Extensive experiments on synthetic and real-world benchmarks demonstrate that the framework consistently outperforms state-of-the-art methods while supporting downstream applications such as material editing and streaming video relighting.
Introduction
Video relighting enables creators and vision systems to modify illumination while preserving scene geometry and materials, but achieving physically accurate and temporally stable results remains a persistent challenge. Prior approaches either rely on direct diffusion generation, which struggles with precise lighting control and retains original illumination artifacts, or depend on intrinsic decomposition pipelines that frequently fail on real-world footage, producing distorted materials, temporal errors, and a strict requirement for camera pose data. The authors address these limitations with RELIT-LIVE, a framework that eliminates camera pose dependencies by jointly generating relit videos and per-frame environment maps within a single diffusion process. They further leverage an RGB-intrinsic fusion renderer that uses raw reference frames to inject real-world lighting cues alongside physical constraints, ensuring tight geometry-illumination alignment. Paired with novel latent-space interpolation and self-supervised temporal coherence training, the method delivers physically plausible relighting across diverse scenes while supporting downstream tasks like material editing and neural rendering.
Method
The authors leverage a novel framework for video relighting that combines a RGB-Intrinsic fusion renderer with joint generation of the relit video and environment video, enabling physically consistent and temporally stable results without requiring explicit camera pose estimation. The overall architecture is designed to bypass the limitations of traditional intrinsic decomposition by directly utilizing observable RGB information while maintaining physical plausibility through intrinsic constraints.
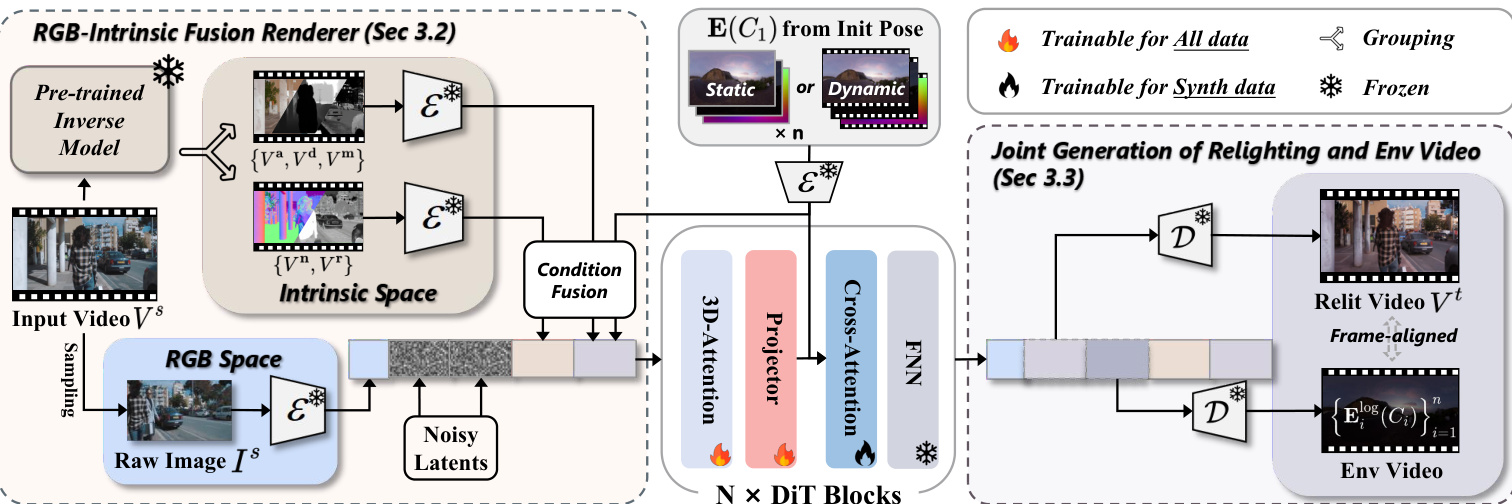
The framework begins by decomposing the input video Vs into intrinsic properties using a pre-trained inverse rendering model. This produces a set of G-buffers including base color Va, surface normal Vn, relative depth Vd, roughness Vr, and metallic Vm. These G-buffers are then encoded into latent space using a pre-trained VAE encoder E, resulting in corresponding latents {za,zn,zd,zr,zm}. To improve efficiency and convergence, the authors propose a partial grouping fusion strategy, summing latents for correlated intrinsic properties: z{a,d,m}=za+zd+zm and z{n,r}=zn+zr. This creates two intrinsic condition latents.
As shown in the figure below, the framework also incorporates a raw image from the input video, randomly sampled and encoded into a latent zI. This latent is concatenated with the intrinsic condition latents along the frame dimension to guide the generation process, effectively suppressing the propagation of source lighting. The random sampling strategy breaks fixed correspondences and is applied at each denoising step to preserve detail.
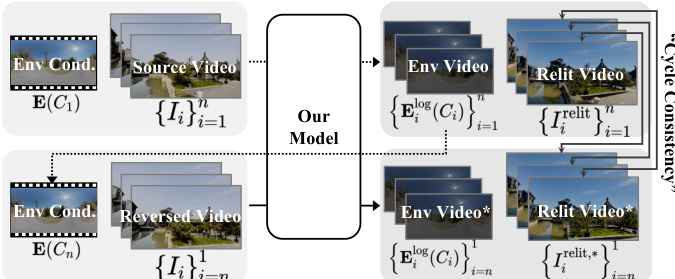
Lighting conditions are represented by HDR environment maps E(C1) under an initial viewpoint C1. These maps are transformed into three complementary representations: LDR images via Reinhard tonemapping, normalized log-intensity images, and directional encoding images. Each representation is encoded into latent space and concatenated to form hE, which is processed by a convolutional layer to obtain cE. This is concatenated with the other condition latents and fed into the DiT video model. The model simultaneously generates the relit video Vt and the corresponding environment video, specifically the normalized log intensity maps {Eilog(Ci)}i=1n, which can be inverse-transformed to HDR and LDR.

During training, the model learns a denoising function fθ that maps the concatenated noise-added latents (relit video, environment video, reference latent, intrinsic latents, and lighting conditions) to the denoised outputs. This joint generation approach allows the model to implicitly infer lighting transformations, eliminating the need for explicit camera pose estimation and enhancing spatio-temporal lighting accuracy. The training process is divided into three stages, with the final stage employing self-supervised learning based on illumination consistency to improve generalization across diverse scenes and lighting conditions.
Experiment
The evaluation compares RELiT-LiVE against state-of-the-art video relighting techniques across diverse synthetic and real-world domains, validating its capacity to maintain material consistency, temporal stability, and physically accurate lighting interactions. Qualitative assessments demonstrate that the model successfully decouples original illumination and handles complex materials without the distortions observed in competing methods, while environment map generation experiments confirm its ability to produce temporally stable lighting across changing camera viewpoints. Additional tests verify the method's versatility in downstream tasks like scene editing and specular highlight removal, and ablation studies highlight how raw reference images, joint environment-video generation, and specialized training strategies collectively drive robust, physically plausible relighting.
The authors compare their method with existing video relighting approaches across synthetic and video datasets, evaluating performance using metrics such as PSNR, SSIM, and LPIPS. Results show that their approach achieves superior performance in both image and video relighting tasks, particularly in handling complex materials and maintaining temporal consistency. The method demonstrates significant improvements over baselines in visual fidelity and material consistency, with notable gains in both synthetic and real-world scenarios. The proposed method outperforms existing approaches in visual fidelity and material consistency across synthetic and video datasets. The method achieves superior results in handling complex materials and maintaining temporal consistency compared to baselines. Quantitative improvements are observed in metrics such as PSNR, SSIM, and LPIPS, indicating enhanced relighting quality and physical accuracy.

The authors compare their method with several advanced video relighting approaches across different datasets, evaluating performance on metrics related to temporal consistency, material consistency, and user study results. The proposed method achieves superior performance in all evaluated aspects, particularly in material consistency and user preference, while demonstrating robustness across various lighting conditions and video types. The proposed method outperforms existing approaches in material consistency and user study metrics across different lighting conditions. The method demonstrates strong temporal consistency, especially in handling dynamic lighting and long video sequences. It achieves superior results compared to text-based and environment map-based methods in maintaining physically accurate material properties and lighting effects.

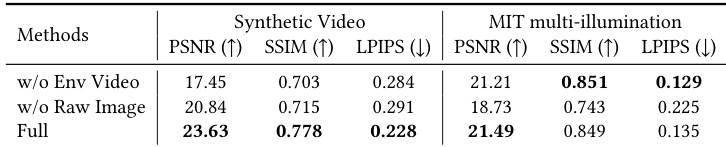
The authors compare their method with variants that omit key components, evaluating performance on synthetic and MIT multi-illumination datasets. Results show that including both environment video generation and raw reference images significantly improves relighting quality across all metrics. The full model consistently outperforms ablated versions, particularly in visual fidelity and material consistency. Including raw reference images significantly improves relighting quality, especially on complex materials. Joint generation of environment video and relighting leads to better performance, particularly under dynamic lighting and camera motion. The full model outperforms ablated versions across all metrics on both synthetic and MIT multi-illumination datasets.
The authors compare their method with a baseline approach across multiple video relighting tasks, evaluating performance on synthetic and real-world datasets. Results show that their method achieves better visual quality and material consistency, with improvements in both training and inference efficiency compared to the baseline. The proposed method outperforms the baseline in visual quality and material consistency across synthetic and real-world datasets. The method achieves significant improvements in training and inference efficiency, reducing GPU memory usage. The baseline approach shows lower performance in handling complex materials and maintaining temporal consistency.

The authors compare their method with existing video relighting approaches across multiple datasets, including synthetic and real-world scenarios. Results show that their method outperforms baselines in terms of visual and material fidelity, particularly in handling complex materials and maintaining temporal consistency. The approach also demonstrates superior performance in generating accurate environment maps for dynamic lighting conditions. the method achieves superior performance across all metrics compared to existing approaches on both synthetic and real-world datasets. The method demonstrates strong material consistency and accurate handling of complex lighting effects such as reflections and refractions. It effectively generates temporally consistent environment maps, enabling accurate lighting estimation across video frames.

The proposed method is evaluated against existing baselines and ablated variants across synthetic and real-world video datasets, using standard fidelity measures, consistency assessments, and user studies to validate overall relighting performance and component contributions. Main comparisons confirm that the approach consistently delivers superior visual and material fidelity, effectively preserving temporal consistency under dynamic lighting and camera motion while accurately rendering complex surfaces. Ablation experiments validate the necessity of jointly generating environment videos alongside raw reference inputs for high-quality material handling, while efficiency tests verify reduced computational overhead and stronger user preference, establishing the method as a robust solution for physically accurate video relighting.