Command Palette
Search for a command to run...
Stream-T1 : Mise à l'échelle au moment du test pour la génération de vidéos en streaming
Stream-T1 : Mise à l'échelle au moment du test pour la génération de vidéos en streaming
Yijing Tu Shaojin Wu Mengqi Huang Wenchuan Wang Yuxin Wang Chunxiao Liu Zhendong Mao
Résumé
Bien que le Test-Time Scaling (TTS) offre une voie prometteuse pour améliorer la génération vidéo sans les coûts croissants associés à l’entraînement, les méthodes actuelles de génération vidéo au moment de l’inférence, fondées sur des modèles de diffusion, souffrent de coûts exorbitants d’exploration de candidats et d’un manque de guidage temporel. Pour surmonter ces goulots d’étranglement structurels, nous proposons de recentrer l’approche sur la génération vidéo en streaming (streaming). Nous identifions que sa synthèse par blocs (chunk-level synthesis) et ses quelques étapes de débruitage sont intrinsèquement adaptées au TTS, réduisant significativement la surcharge computationnelle tout en permettant un contrôle temporel fin.Guidés par cette intuition, nous avons introduit Stream-T1, un cadre TTS complet et novateur spécialement conçu pour la génération vidéo en streaming. Plus précisément, Stream-T1 se compose de trois unités : (1) Stream-Scaled Noise Propagation, qui affine activement le bruit latent initial du bloc en cours de génération en s’appuyant sur des bruits de blocs précédents, historiquement validés et de haute qualité, établissant ainsi efficacement une dépendance temporelle et exploitant l’a priori gaussien historique pour guider la génération actuelle ; (2) Stream-Scaled Reward Pruning, qui évalue de manière intégrée les candidats générés afin d’atteindre un équilibre optimal entre l’esthétique spatiale locale et la cohérence temporelle globale, en combinant des évaluations immédiates à court terme avec des évaluations à long terme basées sur une fenêtre glissante ; (3) Stream-Scaled Memory Sinking, qui dirige dynamiquement le contexte expulsé du KV-cache vers des voies de mise à jour distinctes, guidées par le feedback de récompense, garantissant ainsi que les informations visuelles générées précédemment ancrent et guident efficacement le flux vidéo subséquent.Évalué sur des benchmarks vidéo complets de 5 secondes et 30 secondes, Stream-T1 démontre une supériorité marquée, améliorant significativement la cohérence temporelle, la fluidité du mouvement et la qualité visuelle au niveau des images.
One-sentence Summary
the paper introduce Stream-T1, a test-time scaling framework for streaming video generation that addresses the exorbitant candidate exploration costs and lack of temporal guidance in current diffusion-based methods by leveraging chunk-level synthesis with few denoising steps to significantly lower computational overhead while enabling fine-grained temporal control.
Key Contributions
- Stream-T1 is introduced as the first comprehensive framework that adapts Test-Time Scaling to streaming video generation by replacing global candidate exploration with a computationally efficient chunk-level synthesis process. This architectural shift reduces inference costs while enabling precise temporal control during autoregressive video creation.
- The framework optimizes generation trajectories through three integrated mechanisms: Stream-Scaled Noise Propagation refines initial latent noise using historically successful trajectories, Stream-Scaled Reward Pruning balances local spatial aesthetics with global temporal coherence, and Stream-Scaled Memory Sinking dynamically routes context memory to preserve long-term semantic consistency.
- Comprehensive evaluations on 5-second and 30-second video generation benchmarks demonstrate that Stream-T1 establishes new state-of-the-art performance with measurable improvements in temporal consistency, motion smoothness, and extended visual fidelity compared to existing baselines.
Introduction
Streaming video generation merges autoregressive sequential modeling with diffusion-based fidelity to synthesize exceptionally long, high-quality video sequences, positioning it as a vital advancement for scalable content creation and simulation. While test-time scaling has emerged as a cost-effective strategy to boost generation quality by dynamically allocating inference compute, prior video-specific methods face significant hurdles. Existing approaches typically denoise entire sequences simultaneously, which forces computationally expensive global searches and prevents fine-grained temporal guidance. This global processing model means any localized artifact forces a complete sequence rejection, making dynamic temporal correction impossible and severely limiting long-term coherence. To overcome these bottlenecks, the authors introduce Stream-T1, a test-time scaling framework explicitly designed for chunk-by-chunk streaming generation. The authors leverage three coordinated mechanisms to optimize the generation trajectory: a noise propagation strategy that anchors new chunks to historically successful trajectories, a reward pruning module that balances local visual quality with global temporal consistency, and a memory sinking system that dynamically routes context updates to preserve long-range semantic continuity. This architecture significantly outperforms existing baselines by delivering smoother motion, stronger temporal alignment, and superior visual fidelity across extended video horizons.
Method
The Stream-T1 framework operates through a three-phase pipeline designed for streaming video generation, leveraging test-time scaling to enhance temporal coherence and visual quality while minimizing computational overhead. The overall architecture is structured around chunk-level synthesis, where each video segment is generated sequentially and refined through iterative processes. As shown in the framework diagram, the pipeline begins with the initialization of the first chunk's latent noise using a distribution-preserving gate, followed by a beam search mechanism that expands candidate trajectories. At each generation step, the system proceeds through three distinct modules: Stream-Scaled Noise Propagation, Stream-Scaled Reward Pruning, and Stream-Scaled Memory Sinking, which collectively govern the generation, evaluation, and memory management of the video stream.
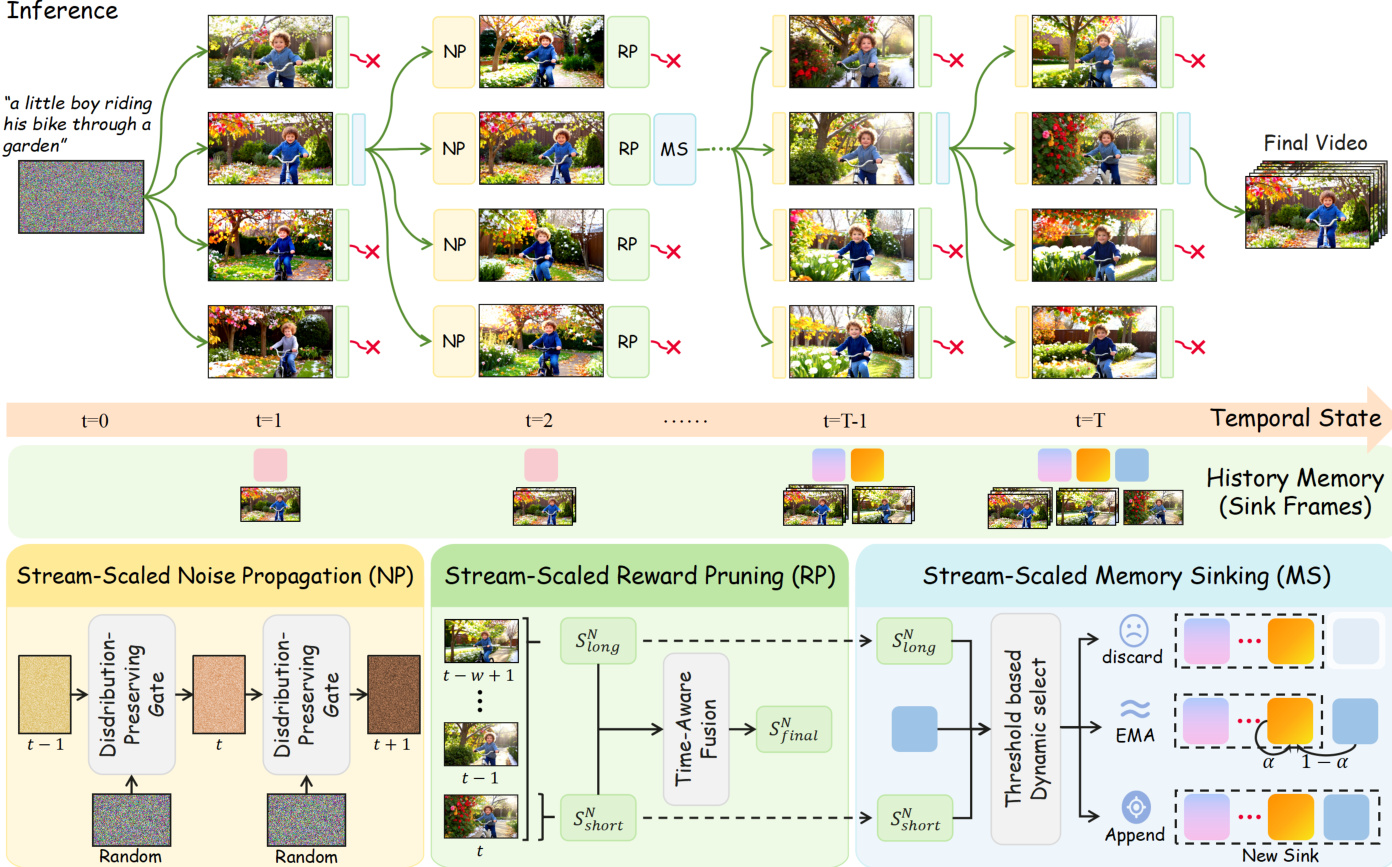
The first phase, Stream-Scaled Noise Propagation, refines the initial noise latent for the current chunk by leveraging the optimal noise trajectory from the preceding chunk. Rather than sampling noise from a standard Gaussian distribution, the framework initializes the noise of the n-th chunk via spherical interpolation between the noise of the (n−1)-th chunk and a random Gaussian variable. This interpolation preserves the marginal distribution of the noise while establishing a strong temporal dependency, effectively guiding the current generation using historical Gaussian priors. The interpolation is defined as xTn=βxTn−1+1−β2ϵ, where β∈(−1,1) controls the degree of temporal correlation, and ϵ∼N(0,I). This mechanism ensures that the initialization of each chunk is informed by previously validated high-quality noise, reducing the risk of divergence and improving overall generation quality.
Following noise initialization, the system enters the Stream-Scaled Reward Pruning phase, where generated chunk candidates are evaluated and pruned to maintain an optimal balance between local spatial aesthetics and global temporal coherence. The evaluation is decomposed into two components: a short score, computed by applying an image reward model to each frame within the chunk, and a long score, derived from a video reward model that assesses temporal coherence over a sliding window. The short score captures frame-level visual fidelity, while the long score evaluates motion smoothness and alignment with the text prompt across multiple frames. To dynamically balance these objectives, a threshold-constrained weighted fusion strategy is employed, where the weight assigned to the short score increases linearly with the chunk index until reaching a predefined threshold τ. The final score for the n-th chunk is formulated as:
Sfinaln={Nn⋅Sshortn+(1−Nn)⋅Slongn,τ⋅Sshortn+(1−τ)⋅Slongn,Nn≤τ,Nn>τ,where N is the total number of chunks. This mechanism prevents frame repetition and stagnation by enforcing a stable trade-off between local detail refinement and global motion alignment.
The final phase, Stream-Scaled Memory Sinking, dynamically manages the key-value cache to preserve long-term semantics while maintaining short-term continuity. The system detects semantic boundaries using two conditions: a quality gate, which ensures only high-quality chunks are retained, and a transition detector, which identifies abrupt changes in temporal coherence. Based on these conditions, the evicted key-value pairs are routed into one of three pathways: discard, EMA-Sink, or Append-Sink. If the chunk fails the quality gate, it is permanently discarded to prevent context pollution. If the chunk is of high quality but shows no significant transition, its key-value pairs are integrated into the existing sink via exponential moving average (EMA) to compress redundant information. When a high-quality chunk coincides with a detected transition, it is appended as a discrete anchor to the global sink, preserving distinct semantic features. This adaptive routing mechanism decouples short-term continuity from long-term memory preservation, enabling consistent generation over extended video sequences. The updated memory states are then used to condition subsequent generations, ensuring that previously synthesized visual information effectively anchors and guides the ongoing stream.
Experiment
The evaluation setup tests the framework on both short and extended video generation to validate its performance against established baselines and standard test-time scaling techniques. Qualitative analysis demonstrates that while existing methods degrade significantly in long sequences, the proposed approach maintains robust spatiotemporal coherence and high visual fidelity. Ablation studies further validate that each core component, including dynamic memory management, noise propagation, and reward pruning, is essential for preserving structural integrity and semantic alignment. Ultimately, the active optimization strategy consistently surpasses passive sampling methods, delivering superior long-term stability and aesthetic quality across diverse generation tasks.
{"summary": "The authors compare their method against baseline models and test-time scaling approaches on long video generation tasks, using both quantitative metrics and qualitative assessments. Results show that their approach achieves superior performance in temporal consistency and visual fidelity, particularly in longer sequences, and that each component of their framework contributes significantly to overall quality.", "highlights": ["Stream-T1 outperforms baseline models across multiple metrics for long video generation, achieving the best results in subject consistency, background consistency, motion smoothness, imaging quality, and aesthetic quality.", "The method demonstrates significant improvements in temporal coherence and visual fidelity compared to existing approaches, especially in extended sequences.", "Ablation studies confirm that each component of the framework is essential, with the removal of any single module leading to notable degradation in specific quality aspects."]

The authors compare their proposed method, Stream-T1, against several baseline models on short video generation tasks using a benchmark that evaluates various aspects of video quality. Results show that Stream-T1 achieves the best performance across most metrics, particularly in temporal consistency and visual fidelity, and outperforms baselines in both short and long video generation scenarios. Stream-T1 achieves the best results on most quality metrics compared to baseline models for short video generation. Stream-T1 demonstrates superior performance in temporal consistency and visual fidelity for short video generation. Stream-T1 outperforms other models in key metrics such as subject consistency, motion smoothness, and aesthetic quality on short video generation tasks.

The authors evaluate their method, Stream-T1, on short and long video generation tasks, comparing it against baseline models. Results show that Stream-T1 achieves the best performance across multiple quality metrics for both short and long videos, with particularly strong improvements in temporal consistency and visual fidelity. The method outperforms existing approaches in both quantitative evaluations and qualitative assessments, demonstrating robust long-term stability. Stream-T1 achieves the best results on most metrics for both short and long video generation compared to baseline models. Stream-T1 significantly improves temporal consistency and frame-level visual fidelity in long videos. The ablation studies confirm that each component of Stream-T1 is essential for maintaining high-quality video generation.

The authors conduct an ablation study to evaluate the impact of individual components in their video generation framework. Results show that each component contributes to different aspects of video quality, with the full model achieving the best overall performance. Removing any component leads to significant degradation in specific metrics, highlighting the importance of the integrated design. Removing Stream-Scaled Memory Sinking degrades background stability and consistency metrics. Omitting Stream-Scaled Noise Propagation results in local structural artifacts and a uniform drop in performance. Eliminating Stream-Scaled Reward Pruning causes semantic misalignment and a decline in aesthetic and temporal quality.

The evaluation compares the proposed Stream-T1 framework against baseline models across both short and long video generation tasks, utilizing comprehensive qualitative and quantitative assessments. Experimental results demonstrate that Stream-T1 consistently achieves superior temporal coherence and visual fidelity, particularly excelling in maintaining subject and background consistency throughout extended sequences. Ablation studies further validate the necessity of each architectural component, revealing that the removal of any single module leads to distinct quality degradations such as structural artifacts or semantic misalignment. Ultimately, the findings confirm that the integrated design of Stream-T1 is essential for robust, high-fidelity video generation across varying durations.