Command Palette
Search for a command to run...
OpenSeeker-v2 : repousser les limites des agents de recherche avec des trajectoires informatives et de haute difficulté
OpenSeeker-v2 : repousser les limites des agents de recherche avec des trajectoires informatives et de haute difficulté
Yuwen Du Rui Ye Shuo Tang Keduan Huang Xinyu Zhu Yuzhu Cai Siheng Chen
Résumé
Les capacités de recherche approfondie sont devenues une compétence indispensable pour les agents des grands modèles de langage (LLM) de pointe, mais leur développement reste dominé par les géants de l’industrie. La recette industrielle typique repose sur un pipeline très intensif en ressources, englobant l’apprentissage préliminaire, l’apprentissage préliminaire continu (CPT), le réglage fin supervisé (SFT) et l’apprentissage par renforcement (RL). Dans ce rapport, nous montrons que, lorsqu’il est nourri de trajectoires informatives et de haute difficulté, une approche SFT simple peut s’avérer étonnamment puissante pour former des agents de recherche de pointe. En introduisant trois modifications simples de synthèse des données — l’augmentation de la taille du graphe de connaissances pour une exploration plus riche, l’élargissement du jeu d’outils pour une fonctionnalité plus étendue, et un filtrage strict en nombre limité d’étapes — nous établissons une référence plus robuste. Entraîné sur seulement 10 600 points de données, notre modèle OpenSeeker-v2 atteint des performances de pointe sur quatre benchmarks (agents de taille 30 milliards de paramètres utilisant le paradigme ReAct) : 46,0 % sur BrowseComp, 58,1 % sur BrowseComp-ZH, 34,6 % sur Humanity's Last Exam et 78,0 % sur xbench, surpassant même Tongyi DeepResearch, entraîné avec un pipeline lourd CPT+SFT+RL, qui obtient respectivement 43,4 %, 46,7 %, 32,9 % et 75,0 %. Il est à noter qu’OpenSeeker-v2 représente le premier agent de recherche de pointe, dans sa classe de taille et son paradigme, à avoir été développé par une équipe purement académique en utilisant uniquement le SFT. Nous sommes enthousiasmés à l’idée de publier en open source les poids du modèle OpenSeeker-v2 et de partager nos résultats simples mais efficaces afin de rendre la recherche sur les agents de recherche de pointe plus accessible à la communauté.
One-sentence Summary
Trained on just 10.6k informative, high-difficulty trajectories synthesized by scaling knowledge graphs, expanding toolsets, and applying strict low-step filtering, OpenSeeker-v2 achieves state-of-the-art performance on BrowseComp, BrowseComp-ZH, Humanity's Last Exam, and xbench for 30B-parameter ReAct agents using only supervised fine-tuning, marking the first academic-developed search agent to surpass resource-intensive industry pipelines.
Key Contributions
- OpenSeeker-v2 is a 30B-parameter search agent trained exclusively through supervised fine-tuning, demonstrating that a streamlined pipeline can rival resource-intensive industry approaches. This capability is achieved through three data synthesis modifications: scaling knowledge graph size, expanding the tool set, and enforcing strict low-step filtering to guarantee high-difficulty trajectories.
- The methodology curates a condensed dataset of 10.6k carefully filtered trajectories, demonstrating that targeted data synthesis can effectively replace extensive continual pre-training and reinforcement learning stages.
- The model achieves state-of-the-art performance across four agentic benchmarks, including BrowseComp, BrowseComp-ZH, Humanity's Last Exam, and xbench, while operating under the ReAct paradigm. This establishes the first academically developed state-of-the-art search agent at this scale, with all weights and code publicly released.
Introduction
Deep search has emerged as a vital competency for frontier Large Language Model agents, but progress is currently restricted to well-funded industrial players utilizing resource-heavy pipelines that stack continual pre-training, supervised fine-tuning, and reinforcement learning. This complexity imposes steep compute and data barriers that effectively exclude academic and open-source communities from advancing search agent capabilities. The authors leverage a data-centric strategy to democratize this technology, introducing OpenSeeker-v2, a search agent that achieves state-of-the-art results using only a single supervised fine-tuning stage. They curate a compact dataset of 10.6k trajectories by scaling knowledge graph sizes, expanding available tools, and applying strict low-step filtering to ensure high difficulty, which forces the model to master sustained multi-hop reasoning. Consequently, their 30B parameter model outperforms industrial solutions like Tongyi DeepResearch across multiple benchmarks, marking the first time an academic team has achieved top-tier search agent performance using a purely SFT workflow.
Method
The authors introduce OpenSeeker-v2, an enhanced search-agent training framework grounded in supervised fine-tuning (SFT). The core hypothesis is that sufficiently challenging and information-rich training data can enable a simple SFT objective to elicit strong long-horizon search and reasoning capabilities. The framework builds upon the original OpenSeeker architecture by refining the data generation pipeline to produce higher-quality training instances that better support complex reasoning.
At the heart of the methodology is a scaled graph expansion process designed to enrich the context available for task synthesis. Let G=(V,E) denote the source graph used for generating training tasks. For each seed node vseed∈V, the original pipeline constructs a local subgraph Gsub centered around vseed. In OpenSeeker-v2, the expansion budget is increased from k to K, where K>k, resulting in a larger evidence subgraph:
Gsub(K)=Expand(G,vseed,K).This expanded subgraph captures a more diverse set of topologically related nodes, thereby increasing the number and variety of feasible reasoning paths. A synthetic query is then generated conditioned on this enriched context:
q∼Pgen(q∣Gsub(K)).By increasing K, the generated questions are more likely to require evidence aggregation across multiple nodes rather than relying on direct or sparse connections.
To further enhance the agent's functional repertoire, the authors expand the set of available tools A beyond those used in OpenSeeker-v1. This expanded tool set is drawn from recent advancements in agent design and enables the agent to execute more complex multi-step reasoning trajectories. Given a generated question q, the search agent produces a ReAct-style trajectory:
τ=(r1,a1,o1,r2,a2,o2,…,rT,aT,oT,rT+1,y),where each action at∈A corresponds to a tool call from the expanded set, and ot denotes the observation returned by the invoked tool. The reasoning trace rt precedes each action, capturing the agent’s internal thought process. The trajectory consists of T tool-call steps, followed by a final reasoning step rT+1 and the answer y. The expanded tool set encourages the agent to explore diverse interaction patterns and leverage complementary tools, leading to more flexible and functionally rich problem-solving behaviors.
To ensure that training data reflects meaningful reasoning complexity, OpenSeeker-v2 applies a strict low-step filtering mechanism. This removes instances that can be solved with minimal or shallow reasoning. The filtered dataset is defined as:
Dv2={(q,τ)∈Draw∣T(τ)≥Tmin}.Here, Tmin is a predefined threshold on the number of tool calls. Trajectories with T(τ)<Tmin are discarded, as they typically represent overly simple cases solvable via direct lookup or keyword matching.

Experiment
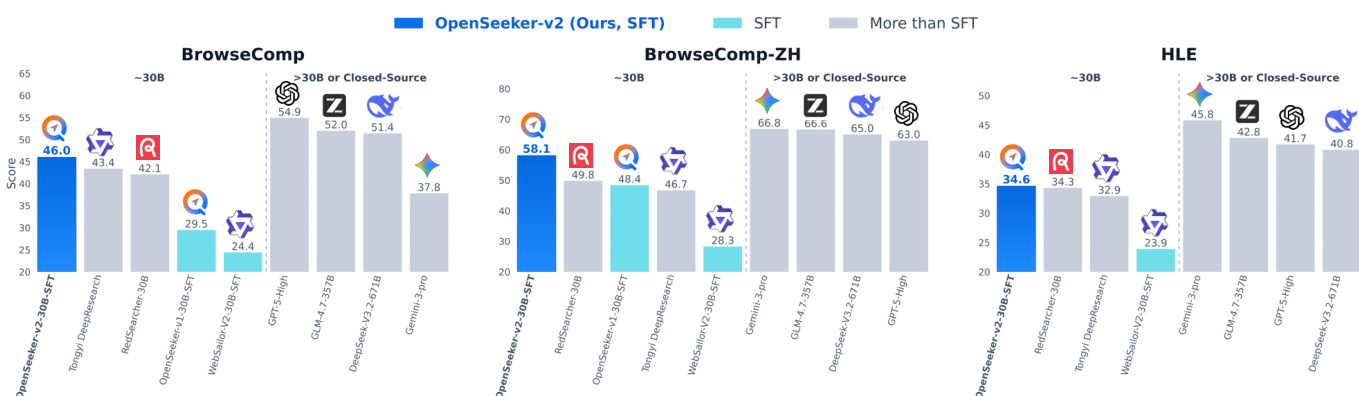
The evaluation setup assesses the model across multiple challenging deep-research benchmarks against comparable-scale agents trained with complex multi-stage pipelines and larger proprietary systems. These experiments validate that a straightforward supervised fine-tuning approach, when driven by high-quality and computationally demanding synthetic trajectories, consistently surpasses more resource-intensive training recipes. The findings highlight the framework's substantial scaling potential and establish carefully curated data quality as the primary driver for advancing long-horizon agentic search capabilities.
The authors evaluate OpenSeeker-v2, a search agent trained with simple supervised fine-tuning, on multiple benchmarks and compare it to other agents, including those trained with more complex pipelines. Results show that OpenSeeker-v2 achieves strong performance, outperforming several comparable-scale models and even larger models, demonstrating that high-quality data can enable effective training without extensive resources. The model also improves significantly over its predecessor, indicating that better data quality and complexity lead to enhanced capabilities. OpenSeeker-v2 outperforms comparable-scale agents trained with more complex pipelines on multiple benchmarks. OpenSeeker-v2 achieves higher performance than larger models, indicating strong capability despite simpler training. The model shows substantial improvement over its predecessor, suggesting that higher-quality data enhances search agent performance.
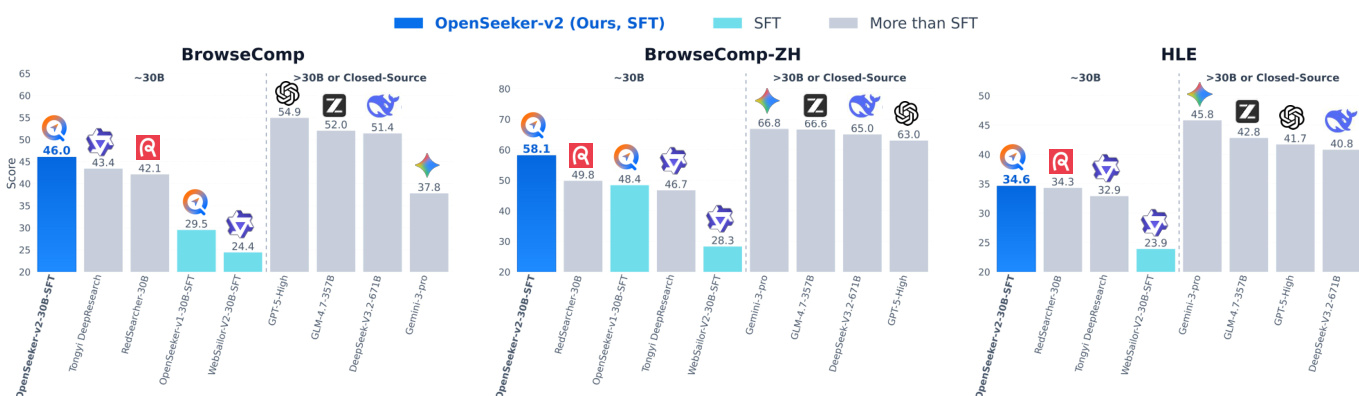
The authors evaluate OpenSeeker-v2, a 30B-scale search agent trained with supervised fine-tuning only, against various benchmarks and compare it to other models. Results show that OpenSeeker-v2 achieves strong performance across multiple tasks, outperforming several comparable-scale models trained with more complex pipelines, including those using continual pre-training and reinforcement learning. The model also surpasses larger models and demonstrates significant improvements over its predecessor, indicating that high-quality data and long-horizon reasoning tasks contribute to its superior performance. OpenSeeker-v2 outperforms comparable-scale models trained with more complex pipelines, including those using CPT and RL. OpenSeeker-v2 achieves higher performance than its predecessor under the same training approach, suggesting scalability through improved data quality. OpenSeeker-v2 surpasses larger models and demonstrates strong results on challenging benchmarks despite using only SFT for training.
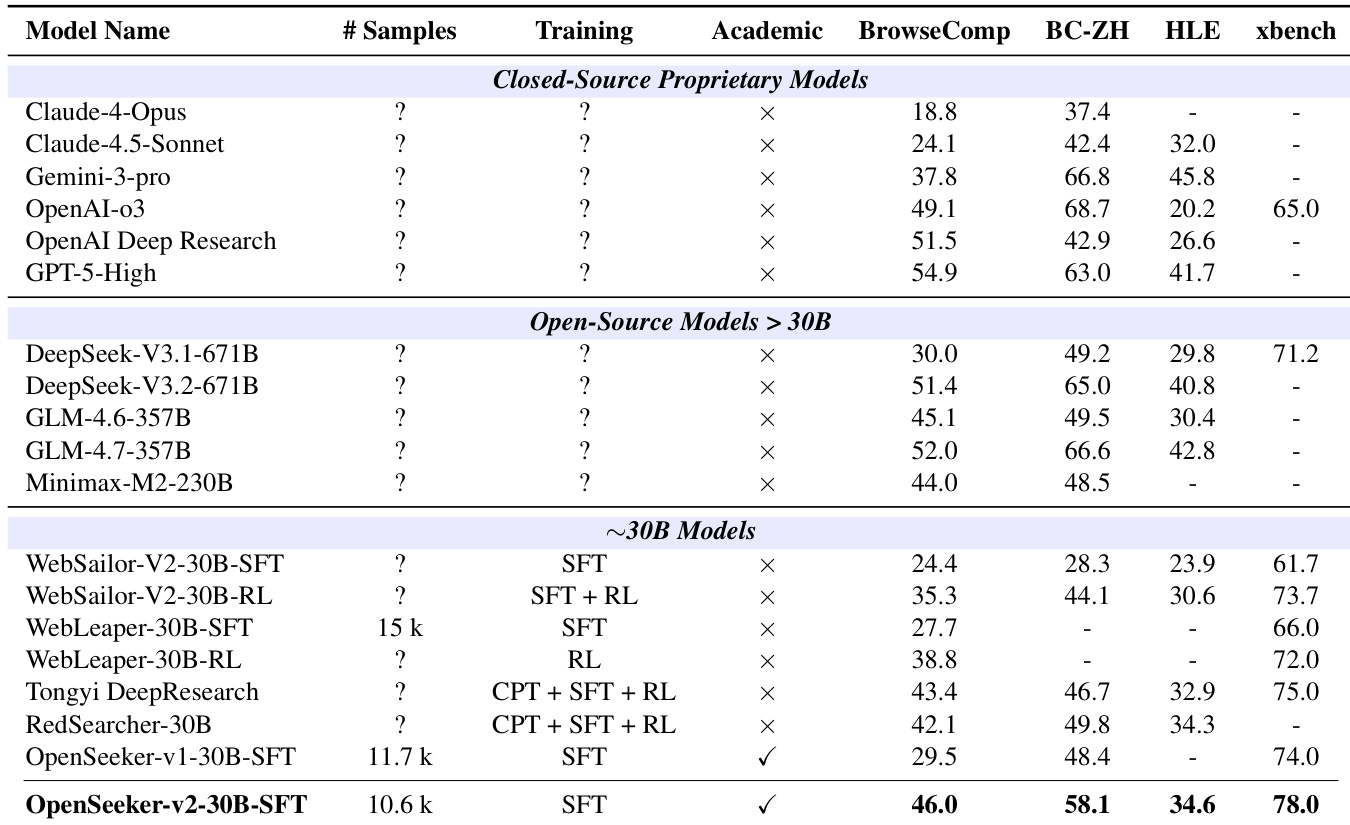
The authors evaluate OpenSeeker-v2, a 30B-scale search agent trained exclusively through supervised fine-tuning, across multiple benchmarks against comparable models utilizing complex pipelines, larger architectures, and its own predecessor. Comparisons against similarly sized and larger systems validate that high-quality training data and long-horizon reasoning tasks drive superior capabilities without requiring advanced training methodologies. The model consistently outperforms its competitors and demonstrates substantial improvements over its predecessor, highlighting the direct impact of dataset refinement on agent performance. Ultimately, these findings conclude that data quality outweighs training complexity in developing highly effective search agents.