Command Palette
Search for a command to run...
Stream-R1 : Distillation de Récompense Aware Perplexité-Fiabilité pour la Génération de Vidéos en Flux
Stream-R1 : Distillation de Récompense Aware Perplexité-Fiabilité pour la Génération de Vidéos en Flux
Bin Wu Mengqi Huang Shaojin Wu Weinan Jia Yuxin Wang Zhendong Mao Yongdong Zhang
Résumé
L’accélération par distillation est devenue un pilier fondamental pour rendre les modèles de diffusion vidéo en streaming autoregressifs pratiques, la distillation par appariement de distributions (DMD) s’étant imposée comme le choix de référence. Toutefois, les méthodes existantes entraînent le modèle étudiant afin qu’il reproduise la sortie du modèle enseignant de manière indiscriminée, considérant chaque séquence de génération (rollout), chaque image et chaque pixel comme une supervision également fiable. Nous soutenons que cette approche plafonne la qualité des modèles distillés, car elle néglige deux axes complémentaires de variance dans la supervision DMD : l’Inter-Fiabilité, qui concerne les séquences de génération de l’étudiant dont la fiabilité de la supervision varie, et l’Intra-Perplexité, qui porte sur les régions spatiales et les images temporelles qui contribuent de manière inégale aux zones où la qualité peut encore être améliorée. L’objectif de distillation confond ainsi deux questions sous un poids uniforme : savoir quels éléments de chaque séquence il convient d’utiliser pour l’apprentissage, et où concentrer l’optimisation au sein de chaque séquence.Pour répondre à cette limite, nous proposons Stream-R1, un cadre de distillation des récompenses sensible à la Fiabilité et à la Perplexité (Reliability-Perplexity Aware Reward Distillation). Ce cadre pondère adaptativement l’objectif de distillation, tant au niveau des séquences de génération qu’au niveau des éléments spatio-temporels, grâce à un mécanisme unique guidé par la récompense. Au niveau de l’Inter-Fiabilité, Stream-R1 redimensionne la perte de chaque séquence de génération par exponentiation d’un score de récompense vidéo pré-entraîné, de manière à ce que les séquences bénéficiant d’une supervision fiable dominent l’optimisation. Au niveau de l’Intra-Perplexité, il rétropropage le même modèle de récompense afin d’extraire la saillience des gradients par pixel, laquelle est intégrée dans des poids spatiaux et temporels. Ces derniers concentrent la pression d’optimisation sur les régions et les images où l’affinement promet le gain d’espérance le plus élevé. Un mécanisme d’équilibrage adaptatif empêche l’un des axes de qualité de dominer les autres en termes de qualité visuelle, de qualité du mouvement et d’alignement avec le texte.Stream-R1 obtient des améliorations cohérentes sur ces trois dimensions par rapport aux méthodes de base de distillation sur les benchmarks standards de génération vidéo en streaming, sans modification architecturale ni surcoût d’inférence supplémentaire.
One-sentence Summary
the paper propose Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework that accelerates autoregressive streaming video generation by adaptively reweighting distribution matching objectives across rollouts and spatiotemporal regions via a shared reward-guided mechanism, thereby overcoming indiscriminate supervision and maximizing distilled output quality.
Key Contributions
- Stream-R1 introduces a Reliability-Perplexity Aware Reward Distillation framework that replaces uniform supervision in distribution matching distillation with an adaptive, reward-guided reweighting mechanism.
- The method dynamically scales rollout losses using a pretrained video reward score to prioritize reliable supervision, while back-propagating the same reward model to extract per-pixel gradient saliency that concentrates optimization on spatial regions and temporal frames requiring refinement.
- Evaluations on standard streaming video generation benchmarks demonstrate consistent improvements in visual quality, motion quality, and text alignment over distillation baselines, achieved without architectural modifications to the student model or additional inference overhead.
Introduction
Autoregressive streaming video models enable frame-by-frame synthesis for arbitrary durations, but their multi-step denoising process remains computationally expensive. Distribution matching distillation has emerged as the standard acceleration technique to compress teacher inference into efficient few-step student generation. However, current methods apply uniform optimization pressure across all rollouts, frames, and pixels, which ignores critical variance in gradient reliability and regional refinement potential. This indiscriminative approach fundamentally caps the quality ceiling of distilled videos. To resolve this, the authors introduce Stream-R1, a reward-guided distillation framework that dynamically reweights supervision at both the rollout and spatiotemporal levels. By scaling losses with pretrained video reward scores and extracting per-pixel gradient saliency, the method concentrates optimization on high-value regions while filtering out unreliable gradients. An adaptive balancing mechanism further ensures equitable progress across visual fidelity, motion coherence, and text alignment, delivering consistent quality gains without architectural modifications or additional inference overhead.
Dataset
- Dataset composition and sources: The provided excerpt does not outline a specific curated dataset. The authors instead rely on standard streaming video generation benchmarks and leverage teacher-student video diffusion architectures to synthesize the training material.
- Key details for each subset: No explicit dataset subsets, sizes, or filtering criteria are detailed. The workflow centers on generating autoregressive rollouts dynamically rather than partitioning a static collection.
- How the paper uses the data: The authors employ the synthesized rollouts to distill a multi-step teacher into a few-step student via Distribution Matching Distillation. They dynamically reweight the distillation objective based on rollout reliability and spatiotemporal perplexity, ensuring the student inherits high-quality generation modes without uniform supervision.
- Processing and metadata construction: Rather than applying cropping or traditional metadata tagging, the authors derive processing weights algorithmically. They back-propagate a pretrained video reward model to generate a per-pixel gradient saliency volume, which is factorized into spatial and temporal components to form adaptive loss masks that concentrate optimization where refinement yields the greatest improvement.
Method
The authors present Stream-R1, a framework for reinforcement learning–guided video distillation that enhances the alignment of a student generator with a pretrained teacher model by dynamically modulating the distillation loss using reward signals. The overall approach builds upon distribution matching distillation (DMD), where a student generator Gϕ learns to produce high-quality videos in fewer steps by minimizing a KL-divergence-based objective against a pretrained teacher diffusion model ϵθ. In this setup, the student generates a clean latent x0=Gϕ(c) from a text prompt c, and a noisy version xt is constructed by adding noise at a random timestep t. The distillation gradient g is computed as the difference between two critic networks: ffake, which estimates the score of the student's output distribution, and freal, which estimates the score of the teacher's output distribution. The base DMD loss is defined as LDMD=21∥x0−sg(x0−g^)∥2, where g^ is the normalized gradient and sg(⋅) is the stop-gradient operator.

The framework is designed to address two key limitations in existing DMD methods: the variability in the reliability of the gradient signal across different rollouts and the lack of fine-grained, spatiotemporal guidance for optimization. To tackle the first issue, Stream-R1 introduces an inter-reliability weighting mechanism. The authors recognize that the gradient g=ffake−freal is not equally reliable for all generated samples. When a student rollout is close to the teacher's high-quality mode, g provides a reliable signal for closing the gap. However, when a rollout is far from this mode, g reflects a refinement within a low-quality region rather than a path to high quality. To mitigate this, the framework queries a pretrained video reward model on the student-generated video V and computes a balanced overall reward rfinal. This scalar reward serves as a proxy for the reliability of the DMD supervision. The reward is then converted into a per-sample loss multiplier using an exponential reweighting: Winter=exp(β⋅rfinal), where β>0 is a temperature parameter. This ensures that rollouts with high reward, and thus more reliable gradients, contribute more strongly to the loss, while low-reward rollouts are attenuated.
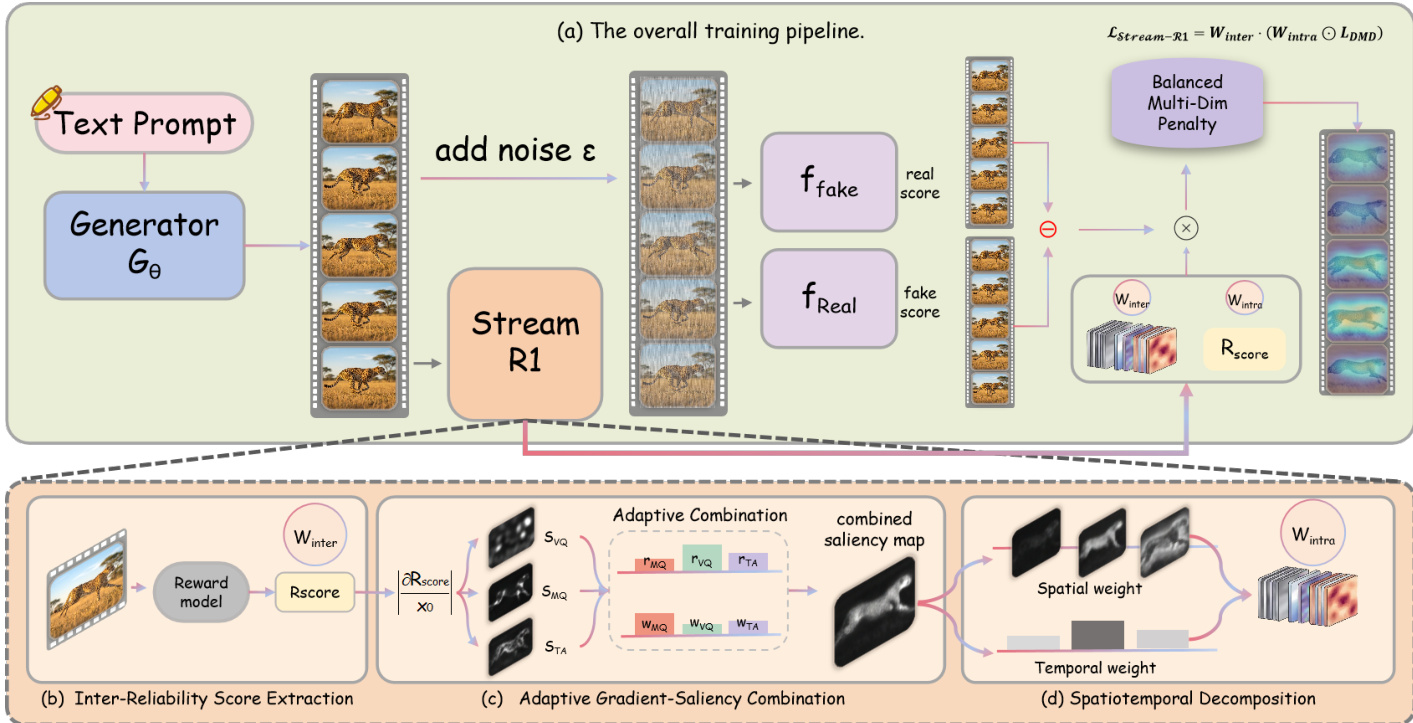
To address the second limitation, Stream-R1 incorporates an intra-perplexity weighting mechanism that provides per-element, spatiotemporal guidance for optimization. This is achieved through a factored decomposition of the saliency map derived from the reward model's gradient. The process begins with adaptive gradient-saliency combination, where the gradients of the reward with respect to the video latent x0 across multiple quality dimensions (e.g., visual quality, motion quality, temporal alignment) are combined into a single saliency volume Scombined∈RF×H×W. This volume jointly encodes both spatial and temporal sensitivity. To disentangle these factors, a spatiotemporal decomposition is performed. Temporal weights are extracted by averaging the saliency over spatial dimensions for each frame, followed by min-max scaling and clamping to a minimum value τmin to prevent any frame from being suppressed. These temporal weights are then mean-normalized to preserve the overall loss magnitude. Spatial weights are extracted by independently normalizing the saliency within each frame using min-max scaling and clamping to a minimum value σmin, and then mean-normalizing each frame's weights to 1. The final per-element weight map Wintra is obtained by multiplying the temporal and spatial components and applying a global mean-normalization.
A key component of the framework is the balanced multi-dimensional reward, which prevents the optimizer from over-focusing on any single quality dimension. The system maintains a sliding window of recent reward history and computes the improvement for each dimension as the difference between its recent and baseline average rewards. The balance penalty is defined as the standard deviation of these improvements across all dimensions, which is subtracted from the base reward to discourage divergent improvement trajectories. This penalty is activated after a warmup period to allow initial reward estimates to stabilize.
The overall Stream-R1 loss combines these components into a single objective: LStream-R1=21Winter⋅mean(Wintra⊙∥x0−sg(x0−g^)∥2). This formulation ensures that the optimization is not only guided by the reliability of the overall sample but also by the fine-grained, spatiotemporal distribution of reward sensitivity, concentrating computational effort on regions and frames where further refinement yields the largest expected gain.
Experiment
The evaluation benchmarks short and long video generation using automated quality metrics, VLM scoring, and human preference studies to assess overall performance and temporal stability. Ablation and controlled degradation experiments validate that the adaptive gradient-saliency mechanism effectively concentrates optimization on spatially and temporally deficient regions rather than applying uniform supervision. Qualitative comparisons and visualizations confirm that this targeted weighting mitigates cumulative quality drift in extended sequences and naturally highlights areas requiring refinement. Ultimately, the approach demonstrates that reward-guided spatiotemporal localization enables a distilled model to surpass its teacher in generation quality while maintaining inference efficiency.
The authors conduct a comprehensive evaluation of their proposed Stream-R1 model against multiple state-of-the-art video generation methods, focusing on both short and long video generation. The results demonstrate that Stream-R1 achieves superior performance across various quality metrics, particularly in visual quality, motion dynamics, and text alignment, while also showing improved temporal consistency and reduced quality degradation in longer videos. The model's effectiveness is further validated through ablation studies and visualizations that confirm the spatiotemporal weights effectively target regions with the most significant quality improvement potential. Stream-R1 outperforms existing methods on all evaluated metrics, including visual quality, motion dynamics, and text alignment, with the highest scores across all dimensions. The model shows consistent improvements over long durations, with a widening performance gap compared to baselines, indicating better mitigation of quality drift. Ablation studies confirm that each component of the spatiotemporal weighting mechanism contributes to overall performance, with the temporal decomposition providing the most significant improvement.
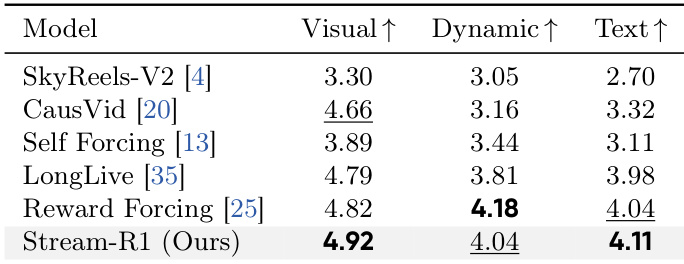
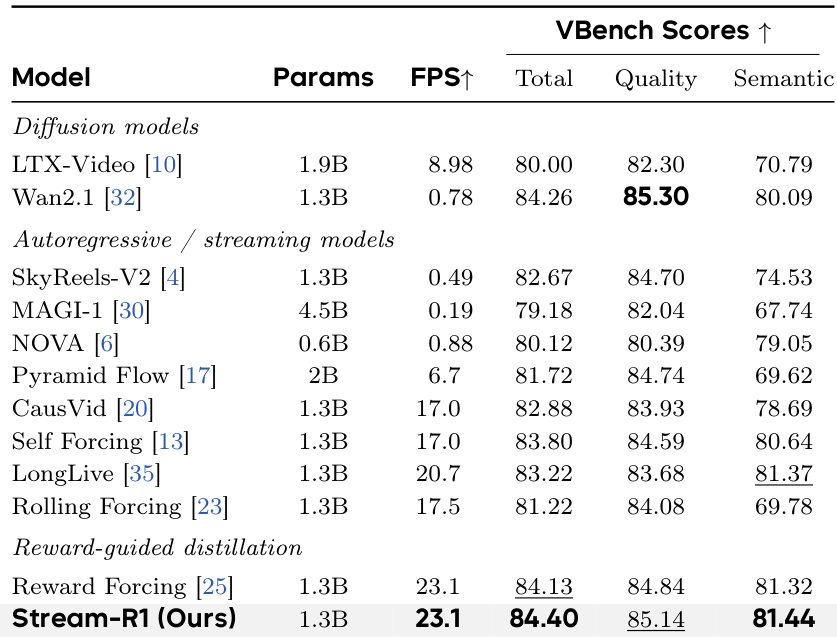
The authors compare their method, Stream-R1, against various state-of-the-art video generation models, including diffusion-based and autoregressive/streaming models, as well as reward-guided distillation baselines. Results show that Stream-R1 achieves the highest scores across multiple metrics, particularly in Quality and Semantic performance, while maintaining high inference speed. The ablation study demonstrates that each proposed component contributes to the overall improvement, with temporal saliency decomposition providing the most significant gain. Stream-R1 achieves the highest total and semantic scores among all compared methods, outperforming both diffusion and autoregressive models. The method surpasses its own multi-step diffusion teacher in quality while running at significantly higher inference speed. Temporal saliency decomposition contributes the largest improvement in the ablation study, enhancing both quality and reducing drift over long video generations.
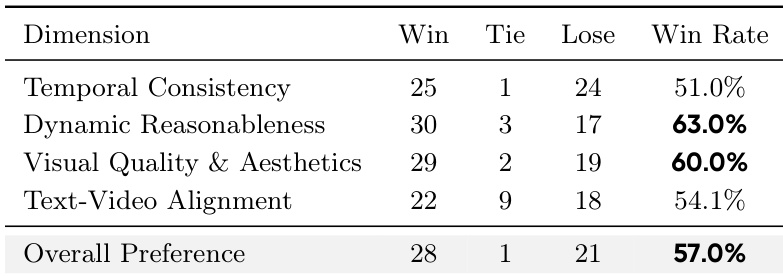
The authors conduct a human preference evaluation comparing their method against a baseline, assessing five dimensions across 50 long videos. Results show that their method is preferred on all dimensions, with the largest margins observed in dynamic reasonableness and visual quality, indicating improved perceptual quality and motion coherence. Human evaluators prefer the proposed method over the baseline on all five assessed dimensions. The largest win margins are observed in dynamic reasonableness and visual quality, indicating superior motion and aesthetic performance. The overall preference win rate is 57.0%, demonstrating consistent human preference for the proposed method.
The authors conduct an ablation study to evaluate the impact of different components on video generation quality, focusing on spatial and temporal reward weighting. Results show that combining spatial saliency with balanced multi-dimensional reward and temporal decomposition leads to the highest performance across both short and long video benchmarks, with significant improvements in quality and reduced drift. Adding spatial saliency improves quality metrics compared to the baseline. Incorporating temporal decomposition results in the largest single improvement in total score and reduces drift. The model achieves optimal performance when all components are combined, outperforming variants with adjusted hyperparameters.
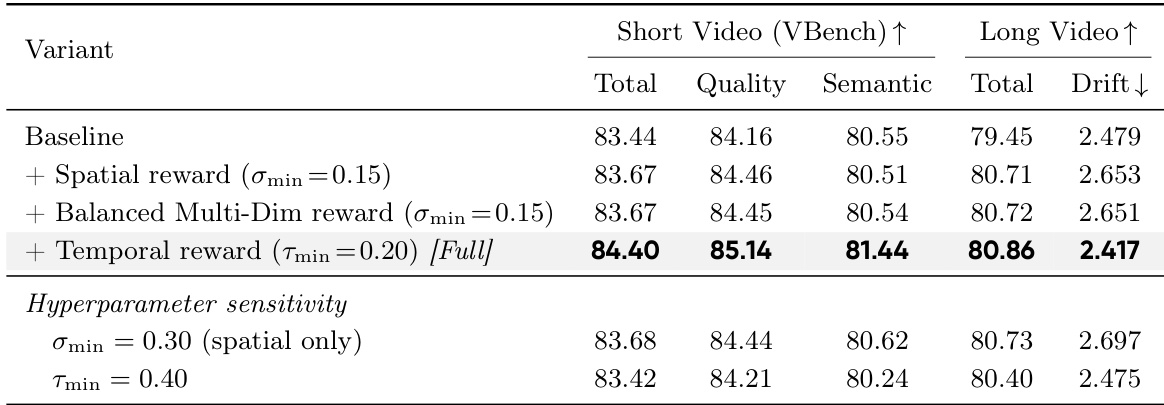
The evaluation compares Stream-R1 against state-of-the-art diffusion, autoregressive, and reward-guided baselines across both short and long video generation tasks. Comprehensive benchmarks demonstrate that the model consistently delivers superior visual fidelity, coherent motion dynamics, and precise text alignment while effectively preserving temporal consistency over extended sequences. Ablation studies validate the individual contributions of the proposed spatial and temporal weighting mechanisms, confirming that temporal decomposition drives the most substantial performance gains. Human preference evaluations further corroborate these results, highlighting a clear advantage in perceptual quality and motion reasonableness compared to existing approaches.