Command Palette
Search for a command to run...
AGENTIC-IMODELS : Évolution des outils d'interprétabilité agents via l'auto-recherche
AGENTIC-IMODELS : Évolution des outils d'interprétabilité agents via l'auto-recherche
Chandan Singh Yan Shuo Tan Weijia Xu Zelalem Gero Weiwei Yang Michel Galley Jianfeng Gao
Résumé
Les systèmes d’automatisation de la science des données (ADS, pour Automated Data Science) améliorent rapidement leur capacité à analyser, ajuster et interpréter les données de manière autonome, ce qui laisse entrevoir un avenir où les agents effectueront la grande majorité du travail en science des données. Toutefois, les systèmes ADS actuels s’appuient sur des outils statistiques conçus pour être interprétables par des humains, et non par des agents. Pour répondre à ce défi, nous présentons AGENTIC-IMODELS, une boucle de recherche auto-agente qui fait évoluer des outils de science des données conçus pour être interprétables par des agents.Plus précisément, cette approche développe une bibliothèque de régresseurs compatibles avec scikit-learn pour les données tabulaires, optimisés à la fois pour la performance prédictive et pour une nouvelle métrique d’interprétabilité basée sur des LLM. Cette métrique évalue une série de tests notés par des LLM, visant à déterminer si la représentation textuelle d’un modèle ajusté est « simulable » par un LLM, c’est-à-dire si le LLM peut répondre à des questions sur le comportement du modèle en se basant uniquement sur sa sortie textuelle.Nous constatons que les modèles ainsi fait évoluer améliorent conjointement la performance prédictive et l’interprétabilité orientée agents, avec une généralisation à de nouveaux ensembles de données et à de nouveaux tests d’interprétabilité. De plus, ces modèles améliorés optimisent les pipelines ADS bout-en-bout en aval, augmentant les performances de Copilot CLI, Claude Code et Codex sur le benchmark BLADE jusqu’à 73 %.
One-sentence Summary
The authors introduce AGENTIC-IMODELS, an agentic autoresearch loop evolving scikit-learn-compatible regressors for tabular data optimized for both predictive performance and a novel LLM-based interpretability metric measuring agent simulatability, improving downstream performance for Copilot CLI, Claude Code, and Codex on the BLADE benchmark by up to 73%.
Key Contributions
- This work introduces AGENTIC-IMODELS, an agentic autoresearch loop designed to evolve data-science tools that are interpretable by AI agents instead of humans. The system develops a library of scikit-learn-compatible regressors for tabular data that are optimized for both predictive performance and agent-facing interpretability.
- The method optimizes models using a novel LLM-based interpretability metric that probes whether a fitted model's string representation is simulatable by an LLM. This metric evaluates if an agent can answer questions about the model's behavior by reading its string output alone.
- Experiments show that the evolved models jointly improve predictive performance and agent-facing interpretability while generalizing to new datasets and interpretability tests. These models also improve downstream end-to-end ADS, increasing performance for Copilot CLI, Claude Code, and Codex on the BLADE benchmark by up to 73%.
Introduction
As agentic data science systems increasingly automate analytical workflows, they currently rely on interpretability tools designed for human consumption rather than agent interpretation. This mismatch limits system reliability because existing outputs such as visualizations are difficult for agents to parse accurately. To address this, the authors introduce AGENTIC-IMODELS, an autoresearch loop that evolves scikit-learn-compatible regressors optimized for both predictive accuracy and agent-facing interpretability. The framework uses a novel LLM-based metric to measure simulatability and achieves up to 73% performance gains on downstream agentic data science benchmarks.
Dataset
- Composition and Sources: The main experiment uses 65 datasets sourced from OpenML and PMLB, comprising 7 from OpenML and 58 from PMLB.
- Generalization Data: The authors reserve 16 held-out OpenML datasets for the generalization experiment.
- Processing and Subsampling: Each dataset is subsampled to at most 1,000 samples and 50 features during evaluation.
- Metadata and Counts: Original sample and feature counts are documented before subsampling occurs.
- Model Usage: The optimization loop incorporates 43 interpretability tests grouped by cognitive operation.
- Evaluation Strategy: Generalization is assessed using 157 new interpretability tests with pass rates pooled across 9 AGENTIC-IMODELS runs.
Method
The authors leverage an agentic autoresearch loop to automatically discover model classes that are both accurate and interpretable to LLMs. The goal of AGENTIC-IMODELS is to simultaneously optimize predictive performance and a novel interpretability metric. This is achieved using a coding agent that iteratively proposes and refines model implementations, specifically scikit-learn-compatible Python classes with fit, predict, and __str__ methods. The agent evaluates candidates on a suite of tabular regression datasets for performance and utilizes LLM-graded tests for interpretability.
Refer to the framework diagram for the high-level architecture of this loop, where the agent interacts with the Agentic-imodels library and iterates based on feedback from performance and interpretability tests.
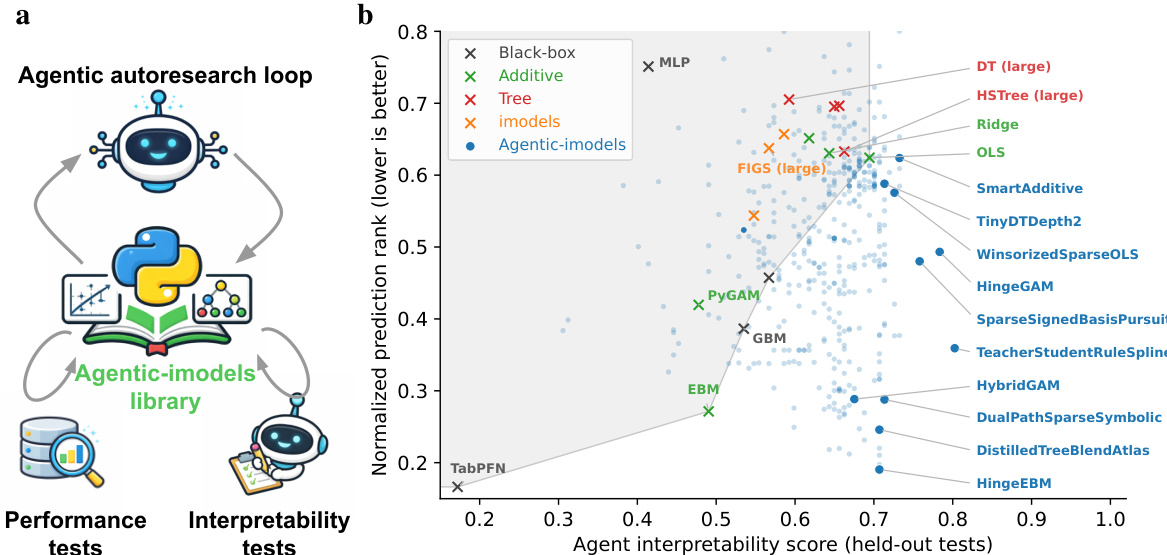
To evaluate interpretability, the system defines the Agent interpretability score as the pass rate of LLM-based tests. These tests probe whether an LLM can answer quantitative questions about the fitted model by reading only its __str__ output. The protocol involves generating synthetic data from a known ground-truth function, fitting the model, and presenting the LLM with the string representation and a query. The response is graded against the ground truth. The test suite covers six categories: feature attribution, point simulation, sensitivity analysis, counterfactual reasoning, structural understanding, and complex function simulation.
The framework facilitates the discovery of architectures that employ display-predict decoupling, where the internal prediction logic is more complex than the displayed representation. For example, the HingeEBM_5bag model fits a two-stage model involving piecewise-linear basis expansions and an EBM on residuals, but its __str__ method displays only a collapsed linear equation. In stage 1, for each feature j, it constructs positive hinge terms max(0,xj−t) and negative hinge terms max(0,t−xj) at K=2 quantile knots. Lasso selects a sparse subset to produce the stage-1 prediction:
In stage 2, if residuals explain more than 10% of remaining variance, an EBM is fitted, but the final prediction combines both stages while the display logic collapses hinge contributions into an effective linear slope.
Similarly, the SmoothAdditiveGAM model fits a greedy additive boosted-stump model. In each of 200 rounds, it selects the feature j and threshold τ that most reduces residual SSE via a depth-1 tree, updates the per-feature shape function fj, and subtracts the fitted step. After boosting, 3 passes of Laplacian smoothing are applied. The prediction is:
y^=μ+j∑fj(xj),where each fi is a piecewise-constant function. For display, a linear approximation is computed for each feature, and if R2>0.90, it is rendered as a coefficient. This smoothing step is critical as it flattens irregular shape functions, increasing the fraction of features that appear as simple linear terms. Another variant, RidgeRFResid, combines a Ridge regression model for display with a Random Forest fitted on residuals for prediction, achieving high interpretability scores while maintaining competitive performance.
Experiment
This research employs an autonomous coding agent to evolve interpretable regression models across 65 datasets, benchmarking them against 16 standard baselines to assess predictive and interpretability performance. The evolved models achieve Pareto improvements on the interpretability-performance frontier with results that remain robust across different LLM evaluators and held-out datasets. Furthermore, integrating these models into downstream AI data science agents significantly enhances their analytical performance on the BLADE benchmark compared to standard tooling due to architectural strategies that bound display complexity.
The the the table details the granular performance of evolved models across a comprehensive suite of 157 interpretability tests, categorized by task types such as feature attribution, sensitivity analysis, and function simulation. The data reveals a wide variance in success rates, indicating that the models are highly effective at certain structural and sensitivity tasks but struggle significantly with others, particularly those involving complex interactions or identifying null effects. Models achieve very high success rates on simple sensitivity tasks and specific nonlinear function simulations, such as quadratic and absolute value simulations. Performance is notably weaker for tasks requiring the identification of irrelevant features or complex multi-feature changes, where pass rates drop significantly. The evaluation suite spans a broad range of complexities, from linear predictions to counterfactual reasoning, exposing specific strengths in structural understanding alongside limitations in handling sparse or high-dimensional feature interactions.
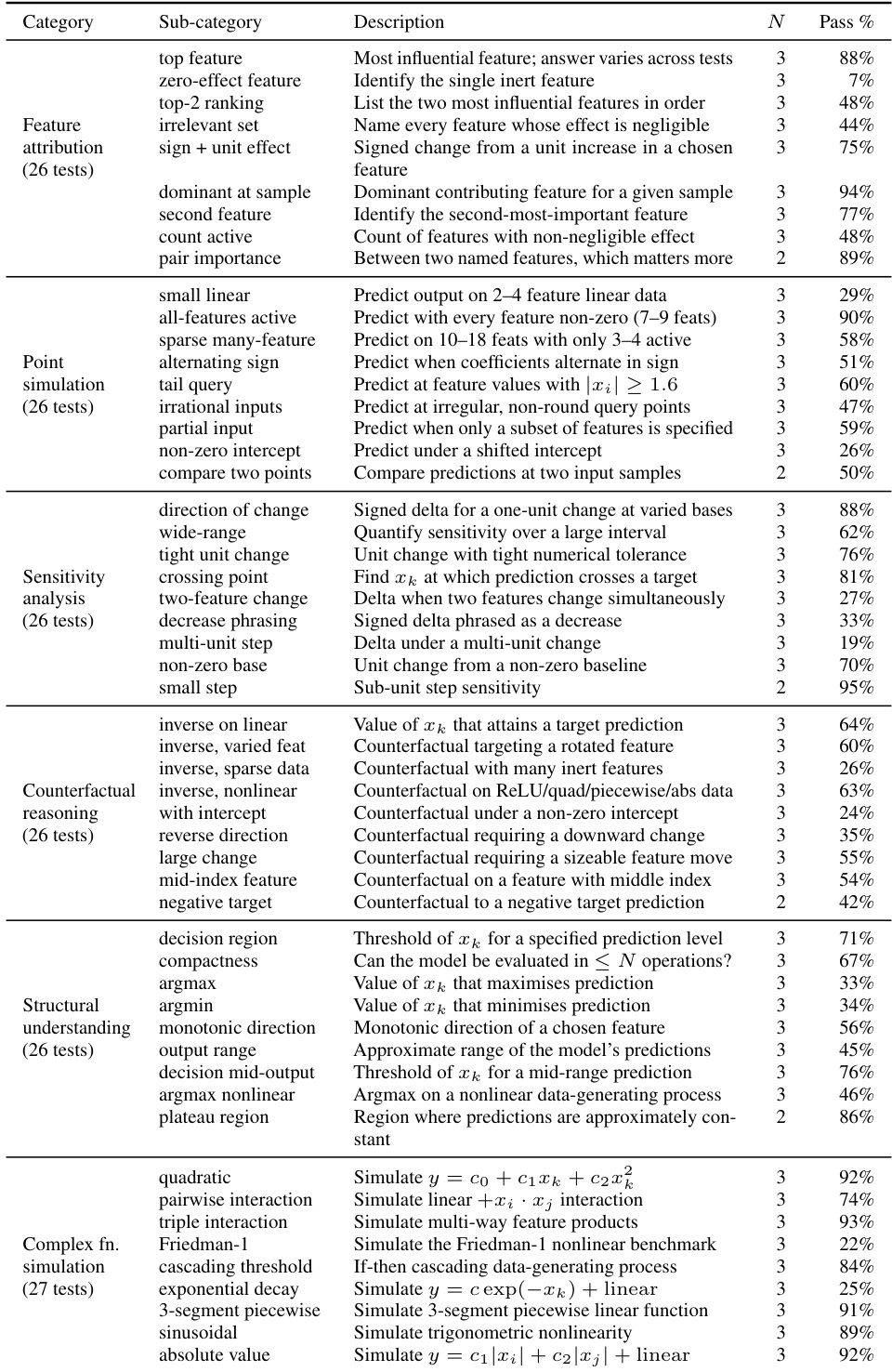
The the the table details token consumption for the AGENTIC-IMODELS autoresearch loop across different coding agents and reasoning effort levels. It distinguishes between fresh tokens, which represent new processing, and cache reads, which dominate the total volume but are billed at a lower rate. The results show significant variability in token distribution depending on the specific agent and configuration used. Cache reads constitute the overwhelming majority of the total token volume across all experimental runs. Fresh token consumption is notably higher for Codex high-effort runs compared to most Claude configurations listed. Total token usage is heavily influenced by cache read volume, which fluctuates considerably across different model configurations and reasoning efforts.
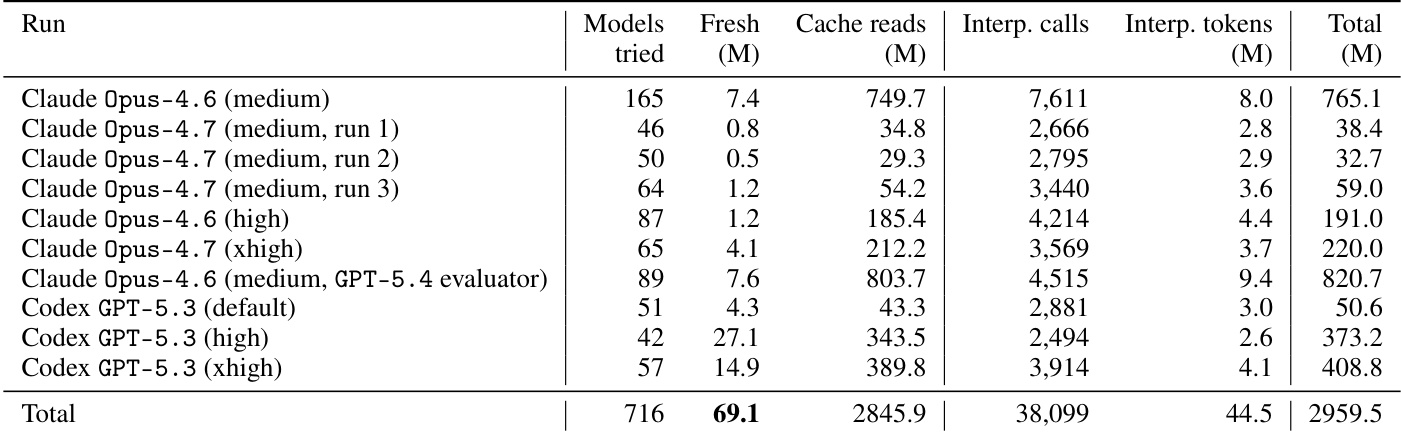
The the the table outlines a comprehensive suite of interpretability tests used to evaluate evolved regression models, categorizing tasks into areas such as feature attribution, simulation, and sensitivity analysis. These tests form the basis of the agent interpretability score, which is benchmarked against predictive performance to assess the trade-offs of the AGENTIC-IMODELS framework. The results indicate that models excel at fundamental attribution and structural tasks but face varying degrees of difficulty with complex simulations and counterfactual reasoning. Feature attribution and structural understanding tests consistently demonstrate high success rates across the evaluated models. Point simulation tasks exhibit significant variability in difficulty, with simple predictions succeeding while complex multi-feature interactions often struggle. Sensitivity analysis yields robust performance, whereas counterfactual reasoning tasks present the most substantial challenges for the system.

The experiment evaluates four AI coding agents on the BLADE benchmark, comparing their performance when using standard tools against a condition where they utilize evolved AGENTIC-IMODELS. The data shows a consistent upward trend in scores for all agents when the specialized models are included. Notably, the agents that started with lower baseline performance experienced the most significant improvements. All four coding agents achieved higher average scores when equipped with the AGENTIC-IMODELS package compared to standard tools. Agents with weaker base models demonstrated the largest relative gains in performance metrics. The performance boost was consistent across individual datasets, with AGENTIC-IMODELS outperforming standard tools in almost every case.
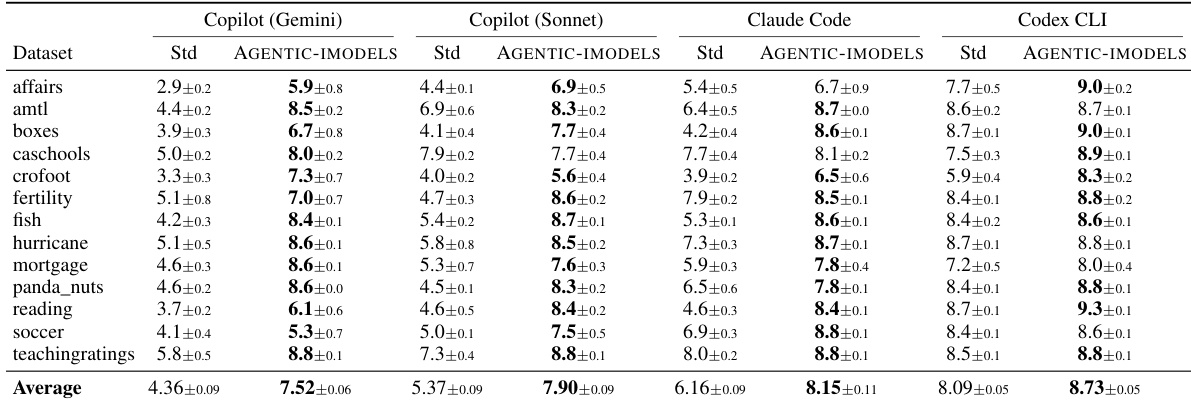
The experiments evaluate the AGENTIC-IMODELS framework across interpretability testing, token consumption analysis, and coding agent performance on the BLADE benchmark. Interpretability results reveal that evolved models excel at structural understanding and sensitivity analysis but struggle with complex feature interactions and counterfactual reasoning. While token usage is primarily driven by cache reads, integrating the specialized models consistently improves coding agent scores, offering the most significant performance gains for agents with weaker baseline capabilities.