Command Palette
Search for a command to run...
Uni-OPD : Unification de la distillation On-Policy avec une recette à double perspective
Uni-OPD : Unification de la distillation On-Policy avec une recette à double perspective
Résumé
La distillation on-policy (OPD) est récemment apparue comme un paradigme efficace de post-entraînement visant à consolider les capacités de modèles experts spécialisés au sein d’un modèle unique, dit modèle élève (student). Malgré son succès empirique, les conditions dans lesquelles l’OPD produit des améliorations fiables restent mal comprises. Dans ce travail, nous identifions deux goulets d’étranglement fondamentaux qui limitent l’efficacité de l’OPD : une exploration insuffisante des états informatifs et une supervision enseignant (teacher) peu fiable pour les déroulements (rollouts) du modèle élève. Forts de cette compréhension, nous proposons Uni-OPD, un cadre OPD unifié qui généralise aussi bien aux LLMs qu’aux MLLMs, et qui repose sur une stratégie d’optimisation à double perspective. Plus précisément, du point de vue de l’élève, nous adoptons deux stratégies d’équilibrage des données afin de favoriser l’exploration des états générés par l’élève durant l’entraînement. Du point de vue de l’enseignant, nous montrons qu’une supervision fiable dépend du fait que le guidage agrégé au niveau des tokens reste cohérent dans l’ordre avec la récompense obtenue à l’issue de la trajectoire (outcome reward). À cette fin, nous développons un mécanisme de calibration par marge guidée par l’issue (outcome-guided margin calibration) afin de restaurer la cohérence de l’ordre entre les trajectoires correctes et incorrectes. Nous réalisons des expériences approfondies dans 5 domaines et sur 16 benchmarks couvrant divers contextes, notamment la distillation à un seul enseignant et multi-enseignants entre LLMs et MLLMs, la distillation fort-vers-faible (strong-to-weak), ainsi que la distillation inter-modale (cross-modal).
One-sentence Summary
Uni-OPD unifies on-policy distillation for LLMs and MLLMs through a dual-perspective strategy that addresses exploration and supervision bottlenecks by employing two data balancing strategies to promote informative student-generated states and an outcome-guided margin calibration mechanism to restore order consistency between correct and incorrect trajectories, evaluated across five domains and sixteen benchmarks.
Key Contributions
- The paper introduces Uni-OPD, a unified on-policy distillation framework that generalizes across large language models and multimodal large language models. This framework centers on a dual-perspective optimization strategy to improve data suitability and training stability.
- Technical contributions include two data balancing strategies to promote student exploration and an outcome-guided margin calibration mechanism to restore order consistency in teacher supervision. These components ensure reliable guidance remains consistent with outcome rewards during student rollouts.
- Extensive experiments validate the method across 5 domains and 16 benchmarks covering settings such as single-teacher and multi-teacher distillation. The evaluation includes strong-to-weak and cross-modal distillation scenarios involving both LLMs and MLLMs.
Introduction
Post-training large language models requires balancing supervised fine-tuning and reinforcement learning to inject reasoning capabilities without suffering from exposure bias or unstable credit assignment. While on-policy distillation (OPD) offers a promising solution by combining on-policy sampling with token-level supervision, its reliability remains poorly understood and prior work is largely confined to text-only models. The authors identify two critical bottlenecks in existing OPD methods: insufficient exploration of informative states and unreliable teacher supervision that lacks order consistency with outcome rewards. To address these challenges, they propose Uni-OPD, a unified framework employing a dual-perspective optimization strategy. The authors leverage data balancing techniques to encourage diverse student exploration and introduce an outcome-guided margin calibration mechanism to ensure reliable teacher guidance. This unified approach effectively generalizes across both LLMs and MLLMs across diverse distillation settings.
Dataset
The authors curate a specialized training corpus and validate performance using a suite of established benchmarks.
Training Data Composition and Processing
- Textual Math Reasoning: 57.0K samples from the DeepMath dataset filtered for difficulty levels of 6 or higher to train mathematical reasoning ability.
- Textual Code Generation: 25.3K samples sourced from the Code subset of the Eurus-2-RL-Data dataset for code generation ability.
- Multimodal Math Reasoning: 14.8K samples drawn from the OpenMMReasoner-RL dataset covering MMK12, WeMath-Standard, and WeMath-Pro subsets.
- Multimodal Logic Reasoning: 14.8K samples collected from the OpenMMReasoner-RL-74K dataset spanning AlgoPuzzle, PuzzleVQA, and ThinkLite-VL-Hard subsets.
- Multimodal Document Understanding: 14.6K samples obtained via 15% sampling from the TQA subset of OpenMMReasoner combined with ChartQA and InfographicsVQA training sets.
Evaluation Benchmarks
- Textual Math: AIME (2024/2025) and HMMT25 for competition-level reasoning challenges.
- Textual Code: HumanEval+, MBPP+, and LiveCodeBench (v6) for functional correctness and execution assessment.
- Multimodal Math: MathVision, DynaMath, and WeMath for visual problem solving across disciplines and knowledge concepts.
- Multimodal Logic: LogicVista and VisuLogic for visual reasoning tasks that are difficult to express textually.
- Document Understanding: AI2D, ChartQA, DocVQA, and InfoVQA for diagram and layout reasoning capabilities.
Method
The authors propose Uni-OPD, a unified framework designed to advance On-policy Distillation (OPD) across both Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). The architecture addresses two fundamental bottlenecks in standard OPD: insufficient exploration of informative student-generated states and unreliable teacher supervision for student rollouts. The framework operates through a dual-perspective recipe that enhances student exploration via data balancing and calibrates teacher supervision to align with outcome rewards.
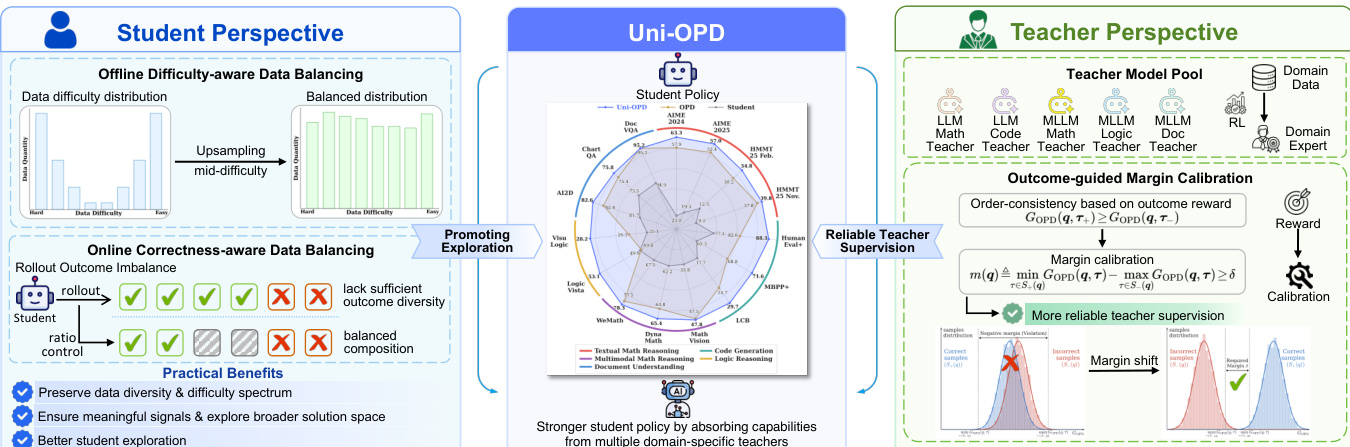
Student Perspective: Joint Data Balancing for Exploration
From the student's perspective, the framework employs a two-stage data balancing strategy to ensure sufficient diversity and appropriate difficulty levels in generated trajectories.
Offline Difficulty-aware Data Balancing Standard reinforcement learning practices often filter out overly easy or hard samples. However, empirical studies indicate that training data for small-scale models frequently exhibits skewed distributions, such as mirrored J-shaped or U-shaped patterns. Aggressively filtering these samples reduces data diversity and limits the exploration of informative states. To mitigate this, Uni-OPD adopts a difficulty-aware balancing strategy that selectively upsamples mid-difficulty samples. This approach reshapes the data distribution into a more uniform form while preserving both diversity and the difficulty spectrum, enabling the student to explore a broader solution space.
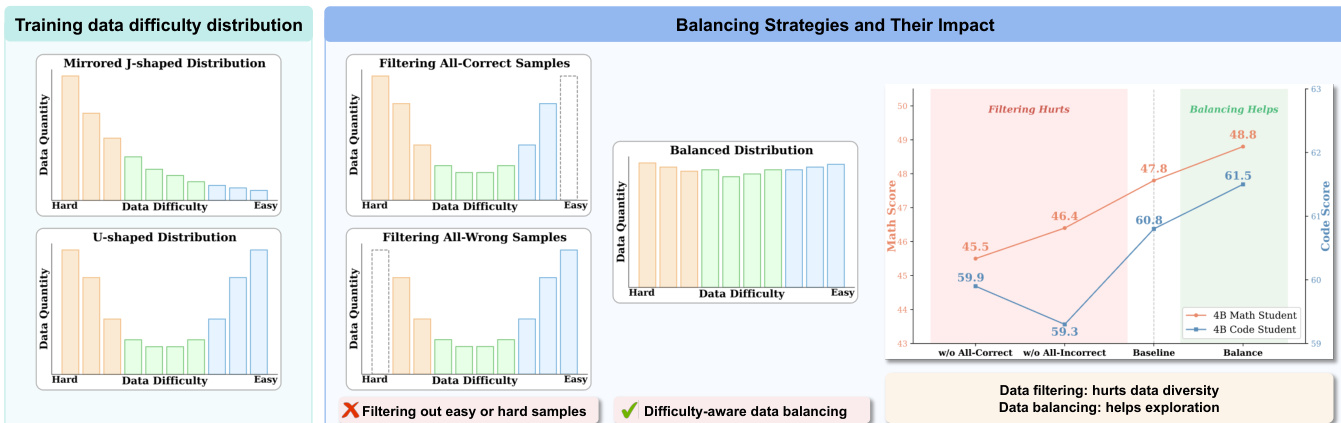
Online Correctness-aware Data Balancing Even with offline balancing, insufficient exploration during training can cause the model to collapse into local optima, particularly when rollout groups lack outcome diversity (e.g., containing only incorrect trajectories). To prevent this, Uni-OPD explicitly enforces a balanced composition of correct and incorrect trajectories within each rollout group. This ensures that the student consistently receives meaningful contrastive signals for stable on-policy learning, avoiding degenerate cases where all samples share the same outcome.
Teacher Perspective: Outcome-guided Margin Calibration
From the teacher's perspective, the framework introduces a mechanism to correct unreliable token-level supervision by enforcing consistency with outcome rewards.
Unreliable Teacher Supervision In standard OPD, the teacher provides fine-grained supervision based on the log-probability gap between the teacher and student policies. Ideally, this distillation signal should align with overall trajectory correctness. However, in practice, this alignment often fails due to Out-of-Distribution (OOD) degradation, overestimation of incorrect trajectories, or underestimation of correct trajectories. These issues lead to a violation of order consistency, where incorrect trajectories receive higher distillation returns than correct ones.
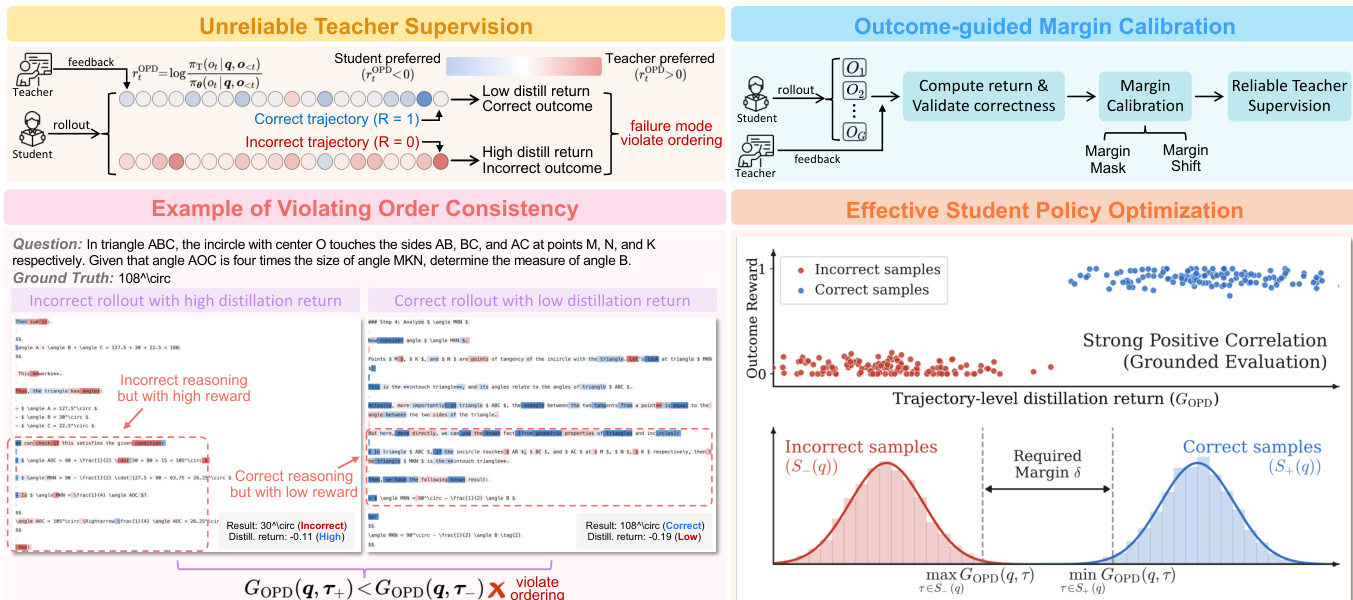
Outcome-guided Margin Calibration To restore reliability, Uni-OPD defines a trajectory-level distillation return GOPD(q,τ) as the average log-probability gap between the teacher and the student over a trajectory τ. The method enforces order consistency by requiring that the distillation return for correct trajectories (S+(q)) be higher than that for incorrect trajectories (S−(q)). Specifically, it defines a prompt-level margin m(q) as the difference between the minimum return of correct trajectories and the maximum return of incorrect trajectories.
m(q)≜τ∈S+(q)minGOPD(q,τ)−τ∈S−(q)maxGOPD(q,τ)The framework requires this margin to satisfy m(q)≥δ, where δ>0 is a safety margin. Two calibration strategies are employed to enforce this constraint:
- Margin Mask: This strategy discards prompt groups that fail to satisfy the margin condition, ensuring training proceeds only with reliable supervision.
- Margin Shift: This strategy repairs unreliable groups by applying a minimal additive correction. For groups where m(q)<δ, a shift λ(q)=δ−m(q) is applied to the trajectory returns (e.g., lifting correct trajectories or suppressing incorrect ones) to guarantee the target margin is met without discarding data.
By integrating these student exploration and teacher calibration modules, Uni-OPD stabilizes optimization and improves the reliability of the distillation process across diverse domains.
Experiment
Comprehensive experiments across textual and multimodal domains evaluate Uni-OPD using Qwen3 models on benchmarks spanning math reasoning, code generation, and document understanding. The method consistently outperforms standard baselines in single and multi-teacher distillation, strong-to-weak distillation, and cross-modal settings by effectively merging specialized capabilities into a unified student policy. Ablation studies validate that core strategies such as margin calibration and data balancing enhance training stability and alignment between token-level feedback and outcome rewards. Qualitative case studies further confirm that Uni-OPD generates more concise and accurate reasoning traces compared to standard distillation approaches.
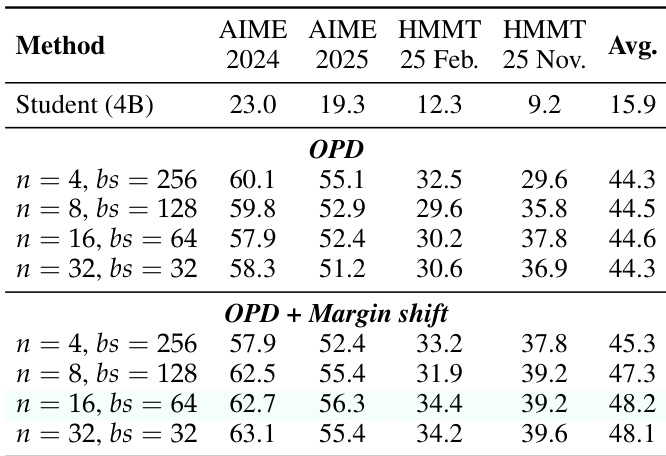
The authors evaluate a 4B student model on math reasoning benchmarks using On-Policy Distillation and a variant incorporating margin shift. Results indicate that adding margin shift consistently outperforms the standard method across various batch and rollout settings. Additionally, the performance varies with hyperparameters, with a specific configuration yielding the highest average score. The baseline student model performs significantly worse than the distillation methods. The margin shift technique consistently boosts performance over standard OPD. An intermediate rollout setting combined with a specific batch size achieves the best results.
The authors evaluate Uni-OPD on math reasoning and code generation tasks using Qwen3 models. Results indicate that Uni-OPD consistently outperforms the standard OPD baseline across both single-teacher and multi-teacher distillation settings. The method achieves the highest average scores in both domains, demonstrating effective capability transfer from specialized teachers to the student model. Uni-OPD achieves superior performance compared to the OPD baseline in both math reasoning and code generation benchmarks. In single-teacher distillation, Uni-OPD yields the highest average scores across all evaluated math and code tasks. The method maintains its advantage in multi-teacher distillation, effectively merging capabilities from multiple specialized teachers.
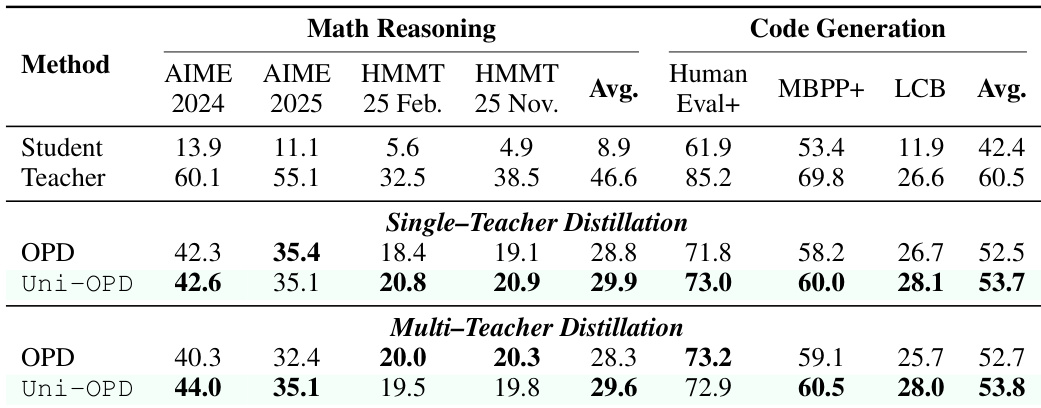
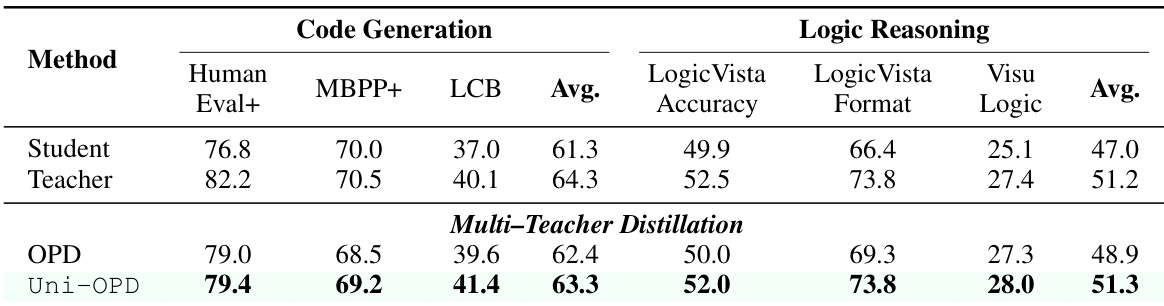
The authors assess Uni-OPD in a multi-teacher distillation scenario involving textual code generation and multimodal logic reasoning. Results indicate that Uni-OPD consistently outperforms the standard OPD baseline across all evaluated metrics in both domains. The proposed method achieves the highest average scores, demonstrating effective integration of heterogeneous teacher capabilities. Uni-OPD outperforms the standard OPD baseline in both code generation and logic reasoning benchmarks. The method achieves the highest average scores in the multi-teacher distillation setting. Consistent improvements are observed across specific tasks such as Human Eval+ and LogicVista Accuracy.
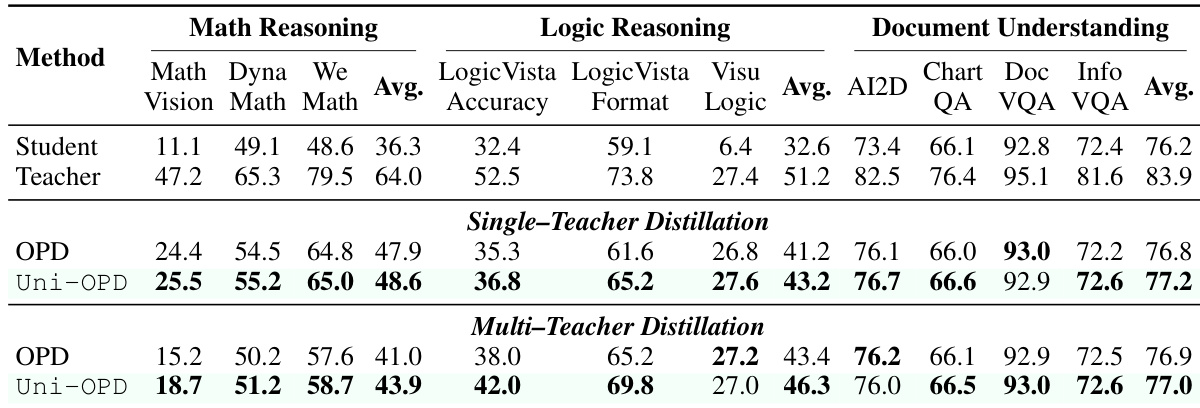
The authors evaluate Uni-OPD against a standard OPD baseline for multimodal large language models under both single-teacher and multi-teacher distillation settings. Results indicate that Uni-OPD consistently achieves superior performance across math reasoning, logic reasoning, and document understanding tasks compared to the baseline method. In multi-teacher scenarios, the proposed method successfully integrates capabilities from multiple specialized teachers into a unified student model. Uni-OPD outperforms the OPD baseline across all evaluated domains in single-teacher distillation. The method demonstrates consistent improvements over OPD when distilling from multiple teachers simultaneously. Uni-OPD effectively merges distinct capabilities from different domain-specific teachers into a single student policy.
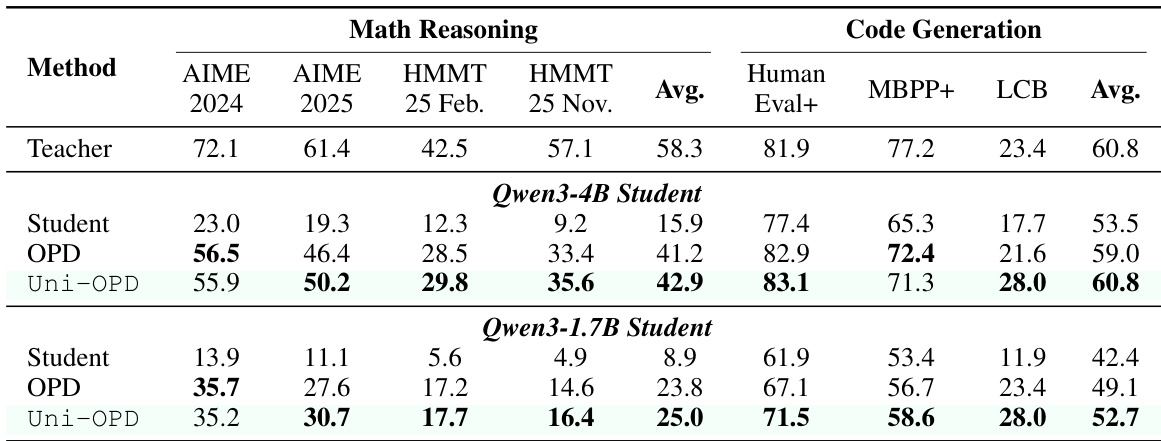
The authors evaluate Uni-OPD in a strong-to-weak distillation setting, transferring capabilities from a large teacher to smaller student models. Results show that Uni-OPD consistently outperforms the standard OPD baseline across both math reasoning and code generation tasks for different student sizes. The method effectively bridges the capacity gap, enabling smaller students to absorb complex reasoning behaviors from superior teachers. Uni-OPD consistently outperforms the standard OPD baseline across both 4B and 1.7B student configurations. The method narrows the performance gap between smaller students and the larger teacher model, particularly in code generation. Performance gains are observed across diverse benchmarks including AIME, HMMT, and HumanEval.
The authors evaluate Uni-OPD and a margin shift variant against standard On-Policy Distillation across math reasoning, code generation, and multimodal tasks using diverse student and teacher configurations. Results demonstrate that Uni-OPD consistently outperforms the baseline in both single and multi-teacher settings by effectively integrating heterogeneous capabilities and bridging capacity gaps in strong-to-weak distillation. Furthermore, the margin shift technique and optimized hyperparameter configurations yield significant performance improvements over standard methods across various benchmarks.