Command Palette
Search for a command to run...
ARIS : Recherche autonome par collaboration multi-agents adversariale
ARIS : Recherche autonome par collaboration multi-agents adversariale
Ruofeng Yang Yongcan Li Shuai Li
Résumé
Le présent rapport décrit ARIS (Auto-Research-in-sleep), une plate-forme de recherche open source destinée à la recherche autonome, en détaillant son architecture, ses mécanismes d’assurance qualité et ses premières expériences de déploiement. Les performances des systèmes à base de agents construits sur des grands modèles de langage (LLM) dépendent à la fois des poids des modèles et de l’écosystème logiciel (harness) qui les entoure, lequel gouverne les informations stockées, récupérées et présentées au modèle. Dans le cadre de workflows de recherche de longue haleine, le mode de défaillance central n’est pas une rupture visible, mais un succès plausible mais non étayé : un agent en exécution prolongée peut produire des affirmations dont le soutien factuel est incomplet, erroné ou hérité silencieusement du cadre interprétatif de l’exécutant.Par conséquent, nous présentons ARIS comme une plate-forme de recherche qui coordonne les workflows de recherche en apprentissage automatique (machine learning) grâce à une collaboration adversaire inter-modèles, configurée par défaut : un modèle exécutant assure l’avancement des travaux, tandis qu’un modèle de la famille des agents réviseurs est recommandé pour critiquer les artefacts intermédiaires et demander des révisions.ARIS repose sur trois couches architecturales. La couche d’exécution propose plus de 65 compétences réutilisables définies en Markdown, des intégrations de modèles via MCP, un wiki de recherche persistant permettant la réutilisation itérative des résultats antérieurs, ainsi que la génération déterministe de figures. La couche d’orchestration coordonne cinq workflows de bout en bout, dotés de paramètres d’effort ajustables et d’un routage configurable vers les modèles réviseurs. La couche d’assurance qualité intègre un processus en trois étapes visant à vérifier si les affirmations expérimentales sont étayées par des preuves : la vérification de l’intégrité, la cartographie des résultats vers les affirmations, et l’audit des affirmations, qui croise les énoncés du manuscrit avec le registre des affirmations et les preuves brutes. Elle inclut également un pipeline d’édition scientifique à cinq phases, des vérifications de preuves mathématiques et une inspection visuelle du PDF rendu.Une boucle d’amélioration autonome en version prototype enregistre les traces de recherche et propose des améliorations de la plateforme, qui ne sont adoptées qu’après approbation par les réviseurs.
One-sentence Summary
Addressing the risk of plausible unsupported success in long-horizon workflows, ARIS is an open-source research harness that coordinates autonomous machine learning research through cross-model adversarial collaboration, pairing an executor model that drives progress with a reviewer from a different model family that critiques intermediate artifacts, while its execution layer supports iterative discovery via a persistent research wiki, model integrations via MCP, deterministic figure generation, and more than 65 Markdown-defined skills.
Key Contributions
- ARIS is an open-source research harness that coordinates autonomous machine learning workflows through a three-layer architecture featuring over 65 reusable Markdown-defined skills, model integrations via MCP, a persistent research wiki, and deterministic figure generation.
- The framework implements a cross-model adversarial collaboration mechanism where an executor model drives progress while a reviewer from a distinct model family critiques intermediate artifacts and requests revisions, effectively breaking self-review blind spots without the coordination overhead of larger multi-agent committees.
- The system incorporates an explicit assurance stack for integrity auditing and cross-platform portability, supporting reproducible end-to-end research workflows that span idea generation, experimentation, and manuscript preparation across multiple host environments.
Introduction
Automating the end-to-end machine learning research pipeline holds significant promise for accelerating scientific discovery, yet long-horizon autonomous tasks remain highly susceptible to hallucinations, correlated errors, and misreported results. Prior autonomous research agents typically rely on same-model self-refinement and tightly coupled workflows, which fail to catch shared inductive biases, lack modular resumption capabilities, and offer minimal system-level verification of experimental integrity. To address these gaps, the authors propose ARIS, a framework that treats single-agent execution as inherently unreliable and decomposes the research process into modular, state-preserving stages. The authors leverage an adversarial cross-family executor-reviewer pairing with explicit assurance checks at critical milestones, ensuring that each research artifact is independently validated by a distinct model family before advancing to the next workflow phase.
Dataset

- Dataset composition and sources: The authors compile a skill inventory that catalogs core framework skills from a current release, as outlined in Table 5.
- Subset details: The provided excerpt does not define distinct subsets, so specific sizes, origins, or filtering criteria are not documented.
- Usage and training configuration: The authors reference the inventory to establish a baseline skill framework. The text does not outline training splits, mixture ratios, or data blending strategies.
- Processing and metadata: No cropping methods, metadata generation steps, or additional preprocessing pipelines are described in the available content.
Method
The ARIS framework is structured around three primary architectural layers—execution, orchestration, and assurance—that collectively address the challenges of long-horizon, autonomous machine learning research. The execution layer provides a modular foundation through more than 65 reusable skills, each defined as a plain-text Markdown file (SKILL.md) that specifies inputs, outputs, procedural steps, and quality gates. These skills are coordinated via versionable artifact contracts, enabling checkpoint-based recovery and auditability. The orchestration layer manages five end-to-end workflows—idea discovery, experiment bridge, auto-review loop, paper writing, and rebuttal—chained through these contracts and grouped into four research phases: Discovery, Experimentation, Manuscript, and Post-Submission. This layer supports adjustable effort settings and configurable routing to reviewer models, allowing users to scale depth and breadth while maintaining core review invariants. The assurance layer implements a multi-stage process to detect and mitigate plausible unsupported success, including evidence integrity verification, result-to-claim mapping, and claim auditing against raw evidence and a claim ledger. It also includes a five-pass scientific-editing pipeline, mathematical-proof checks, and visual inspection of rendered PDFs. A prototype meta-optimization loop records research traces and proposes harness improvements that are only adopted after reviewer approval, enabling iterative refinement of the system itself. The overall architecture is designed to enforce independent assurance by default, leveraging cross-model adversarial collaboration between an executor and a reviewer drawn from different model families, thereby reducing shared inductive biases and enhancing critical evaluation.



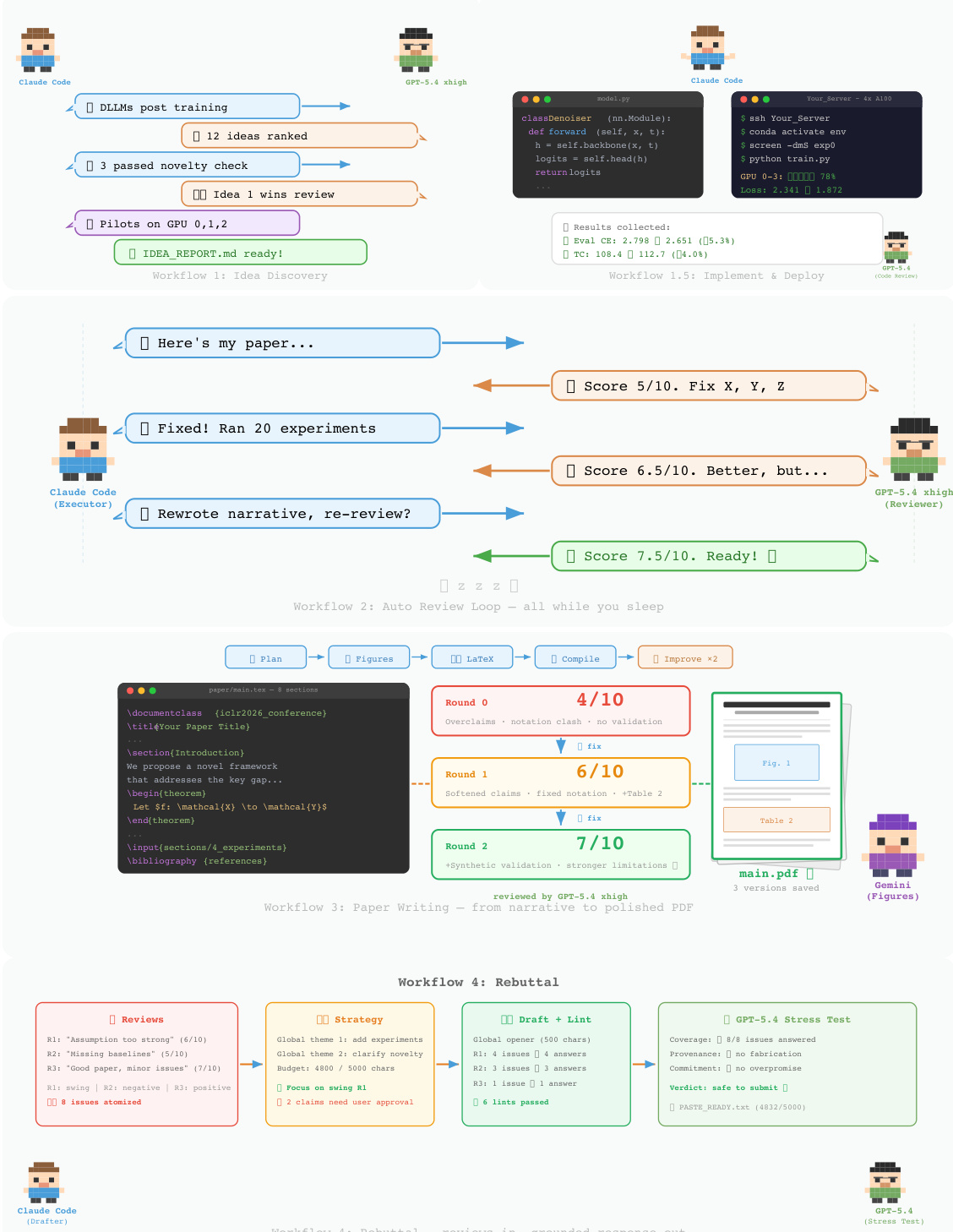
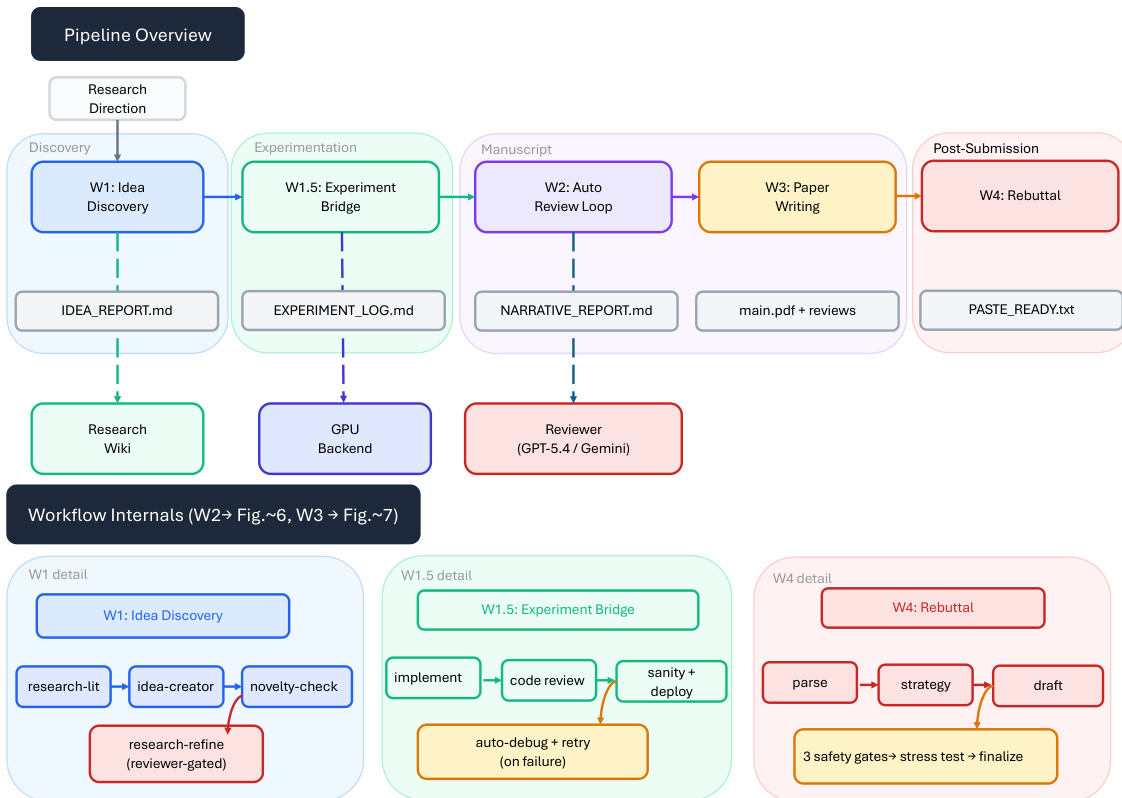
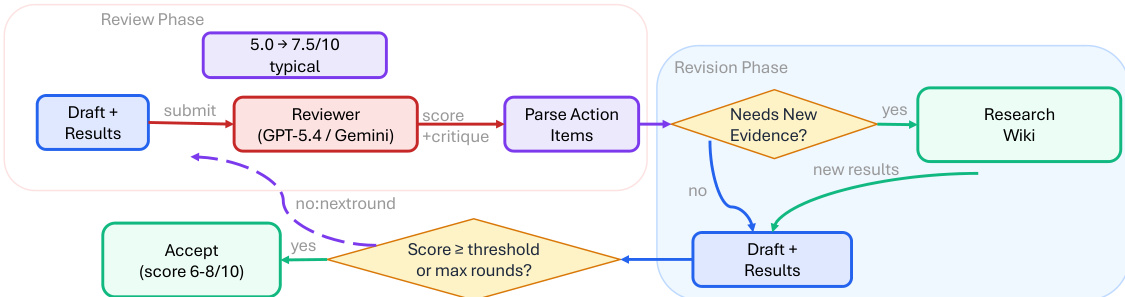
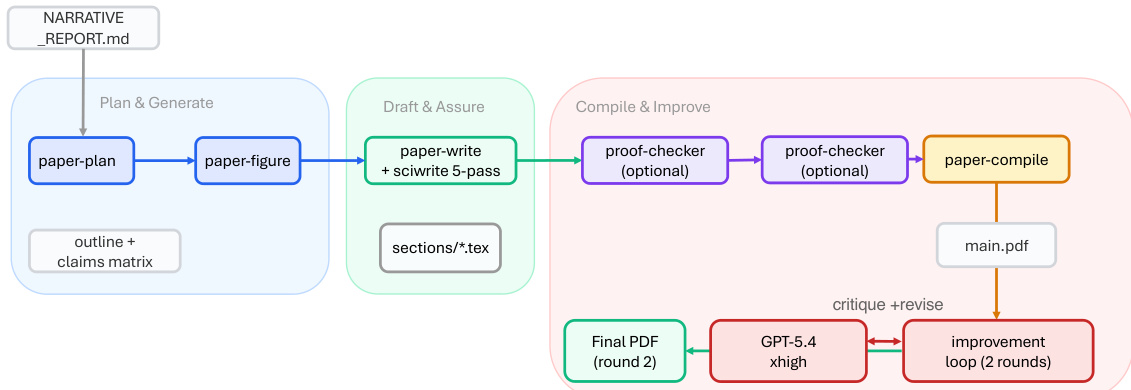
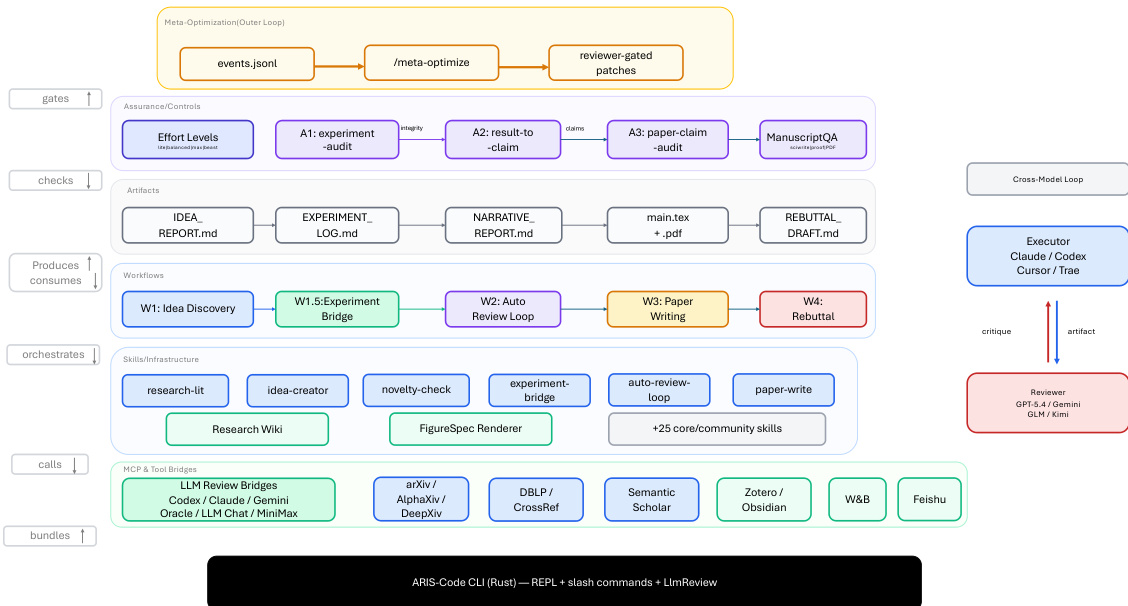
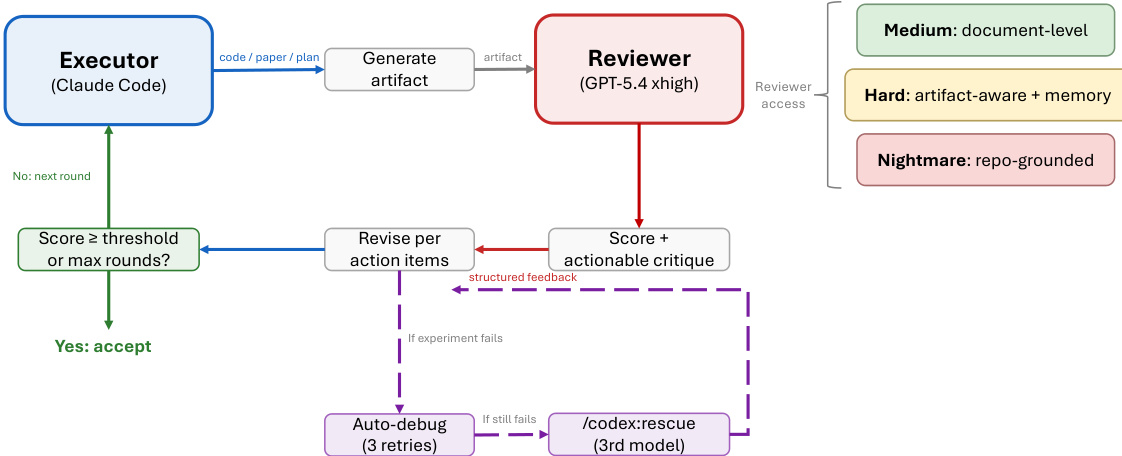
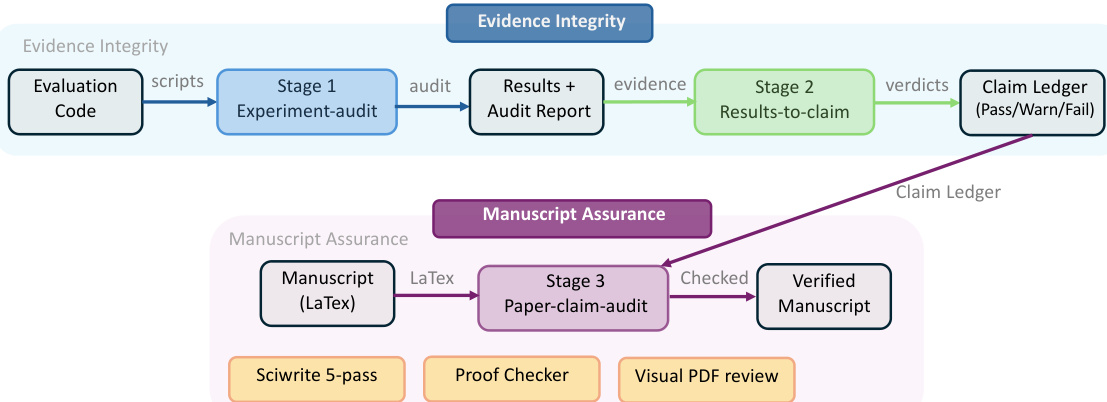
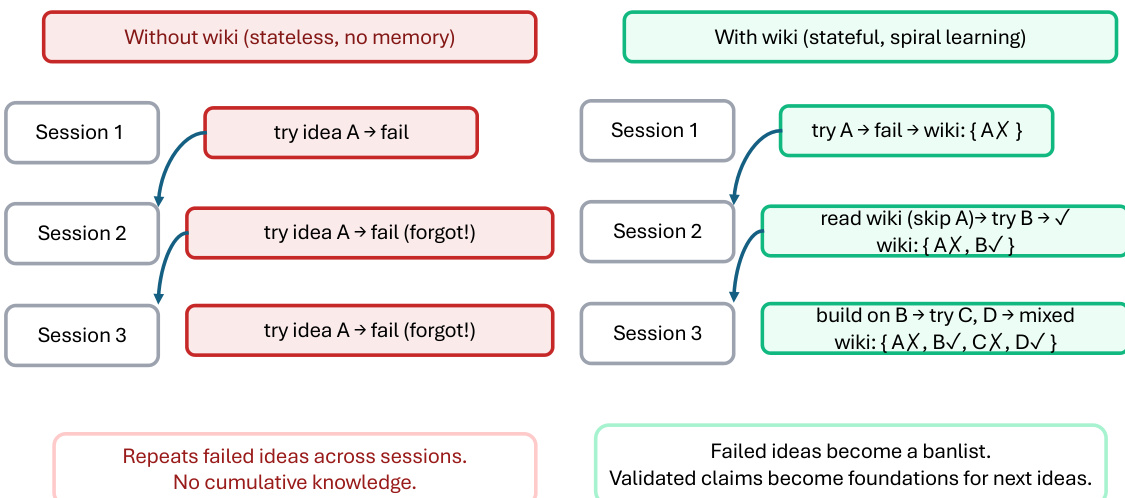

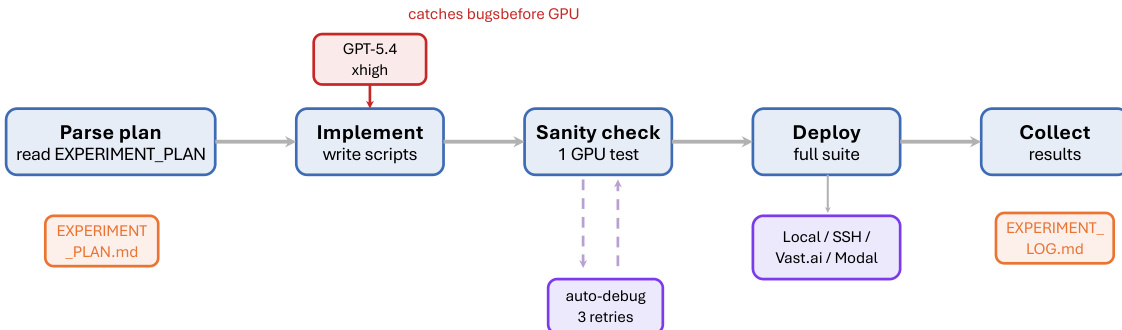
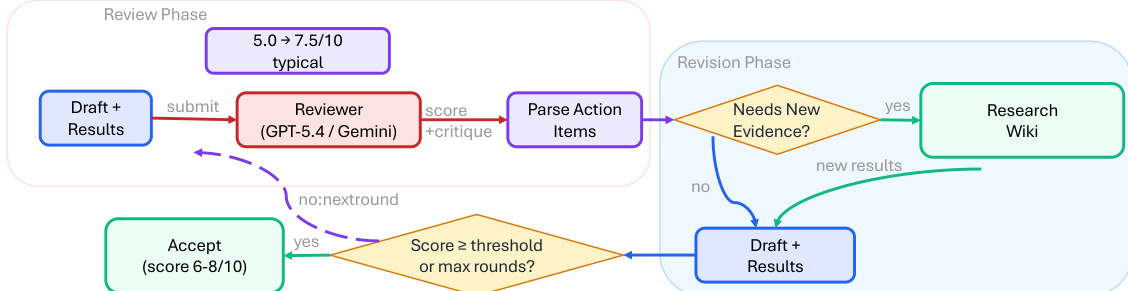
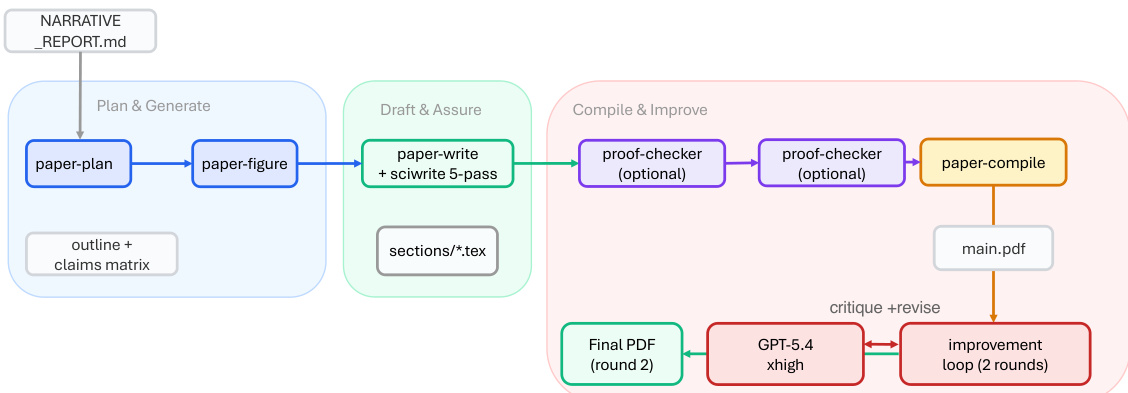

Experiment
The evaluation relies on observational deployment tracking and a single overnight operational run to assess ARIS under realistic conditions. These experiments validate the system's practical capability to autonomously prune unsupported claims and iteratively refine manuscripts through automated review cycles, alongside demonstrating substantial ecosystem expansion across multiple technical domains. Because the reported outcomes remain observational, they confirm operational feasibility rather than establishing causal advantages for specific reviewer architectures or model configurations. A future controlled benchmark protocol will be required to isolate the impact of algorithmic design from external variables like researcher expertise and task difficulty.
The authors present a comparison of different systems, including their own, across several capabilities such as cross-family review, adversarial review, composability, E2E research workflows, assurance stack, and cross-platform portability. The system developed by the authors, ARIS, demonstrates a comprehensive set of features, particularly in composability and E2E research workflows, and supports cross-platform portability. ARIS supports cross-platform portability and E2E research workflows, which are not supported by other systems. ARIS includes composable skills and an assurance stack, features absent in most compared systems. ARIS implements a default cross-family policy, whereas other systems either lack this capability or use partial or none policies.
The evaluation compares ARIS against existing systems across multiple capability dimensions, validating its performance in cross-family and adversarial reviews, composability, end-to-end research workflows, assurance stacks, and cross-platform portability. ARIS demonstrates superior integration by uniquely supporting full end-to-end workflows and cross-platform deployment while introducing composable skills and a dedicated assurance stack absent in competing tools. Additionally, it establishes a comprehensive default cross-family policy that addresses the partial or missing coverage found in alternative approaches.