Command Palette
Search for a command to run...
HEAVYSKILL : La réflexion profonde comme compétence interne dans le système de pilotage des agents
HEAVYSKILL : La réflexion profonde comme compétence interne dans le système de pilotage des agents
Résumé
Les avancées récentes dans le domaine des systèmes multi-agents, alimentées par des cadres d’orchestration qui coordonnent plusieurs agents dotés de mémoire, de compétences et de capacités d’utilisation d’outils, ont permis des succès remarquables dans le traitement de tâches de raisonnement complexes. Cependant, les mécanismes sous-jacents qui pilotent véritablement ces performances restent masqués par la complexité des architectures de systèmes. Dans cet article, nous proposons HEAVYSKILL, une perspective qui envisage la « réflexion lourde » (heavy thinking) non pas uniquement comme une unité d’exécution minimale au sein des frameworks d’orchestration, mais également comme une compétence interne internalisée dans les paramètres du modèle, capable de guider l’orchestrateur pour résoudre des tâches complexes. Nous identifions cette compétence comme un pipeline en deux étapes, à savoir un raisonnement parallèle suivi d’une synthèse, capable d’opérer sous-jacemment à n’importe quel agentic harness. Nous présentons une étude empirique systématique de HEAVYSKILL dans divers domaines. Nos résultats montrent que cette compétence interne surpasse constamment les stratégies traditionnelles de Best-of-N (BoN) ; plus particulièrement, les LLMs plus puissants peuvent même s’approcher des performances Pass@N. De manière cruciale, nous démontrons que la profondeur et la largeur de la réflexion lourde, en tant que compétence apprenable, peuvent être davantage amplifiées via l’apprentissage par renforcement, offrant ainsi une voie prometteuse vers des LLMs auto-évoluants qui internalisent le raisonnement complexe sans dépendre de couches d’orchestration fragiles.
One-sentence Summary
The authors propose HEAVYSKILL, a perspective framing heavy thinking not merely as a minimal execution unit but as an inner skill internalized within model parameters and identified as a two-stage pipeline of parallel reasoning and summarization, demonstrating through systematic empirical study that it outperforms traditional Best-of-N strategies and allows stronger LLMs to approach Pass@N performance while scaling via reinforcement learning to offer a path toward self-evolving LLMs without relying on brittle orchestration layers.
Key Contributions
- This work introduces HEAVYSKILL, a training-free framework that reproduces heavy thinking for complex reasoning tasks through a two-stage pipeline of parallel reasoning and sequential deliberation.
- A comprehensive empirical study across diverse model scales and task domains establishes the effectiveness of this approach, showing it consistently outperforms traditional Best-of-N strategies.
- Systematic analyses demonstrate that reinforcement learning from verifiable rewards can scale the depth and width of heavy thinking to improve reasoning metrics like Heavy-Mean@k and Pass@k.
Introduction
Recent advances in agentic harnesses coordinate multiple agents to solve complex reasoning tasks, yet the mechanisms driving this performance remain obscured by intricate system designs. Existing parallel reasoning methods often depend on static schedules or hand-crafted heuristics that lack adaptivity and rely heavily on brittle orchestration layers. To address this, the authors introduce HEAVYSKILL, a perspective that treats heavy thinking as an inner skill internalized within the model's parameters rather than just an execution unit. They propose a two-stage pipeline involving parallel reasoning followed by sequential deliberation that operates beneath any agentic harness. Systematic empirical studies demonstrate that this approach consistently outperforms traditional Best-of-N strategies and can be scaled via reinforcement learning to improve reasoning depth and width without external orchestration.
Method
The Heavy Thinking framework operates through a structured inference pipeline designed to scale reasoning capabilities at test time. As shown in the figure below, the architecture decomposes the process into two distinct phases: parallel reasoning and sequential deliberation.
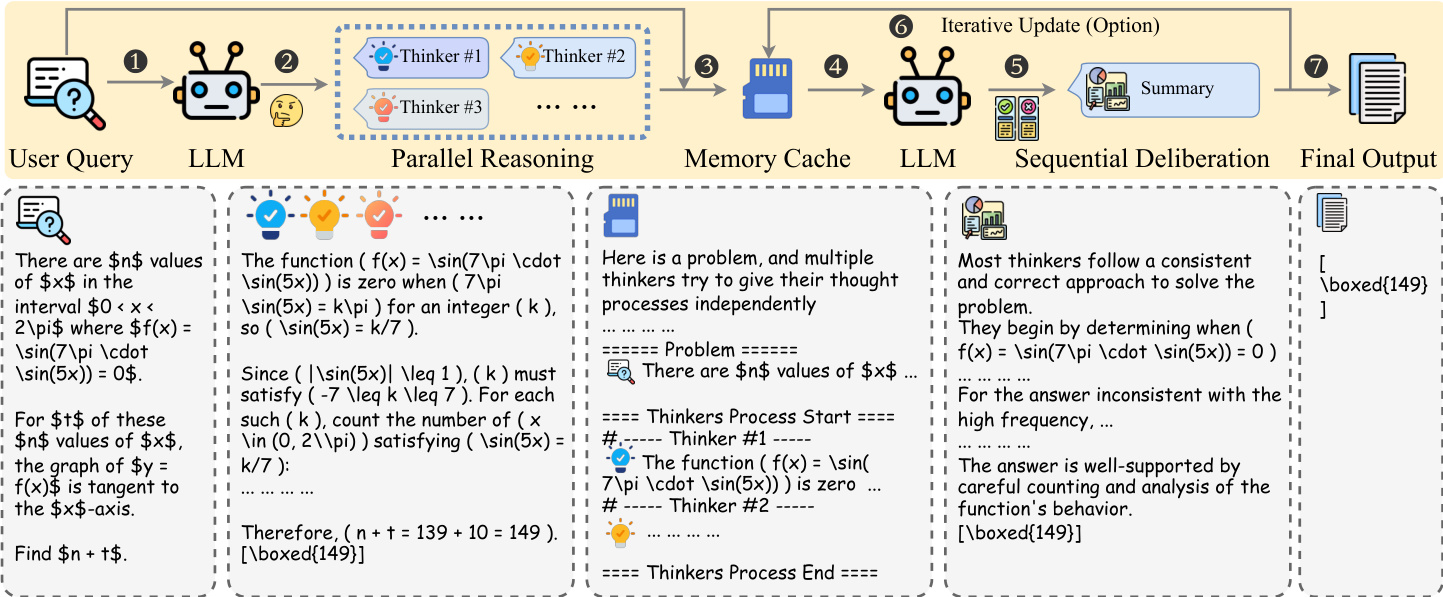
In the first phase, parallel reasoning, the system aims to generate multiple independent trajectories for a given problem q. Formally, the model πθ produces a set of trajectories Tπθ(q,K)={y1,⋯,yK}, where K represents the number of parallel agents. Each trajectory yi is generated autoregressively. This stage encourages diverse problem-solving strategies without the agents sharing context or seeing each other's work.
To facilitate the transition to the next stage, the framework employs a serialized memory cache mechanism. Since full reasoning traces can exceed context limits, the trajectories are pruned and shuffled to create a serialized context C(xc). This ensures the subsequent model does not develop positional bias and can process the information within token constraints.
The second phase, sequential deliberation, involves a separate LLM πϕ that aggregates the information from the cache. This model acts as a meta-reasoner, tasked with synthesizing the independent thought processes. The prompt structure used for this deliberation is illustrated in the image below.

The deliberation prompt explicitly instructs the model to analyze the reasoning quality of each thinker rather than relying on simple majority voting. It requires the model to identify logical errors, cross-validate approaches, and apply professional skepticism. If the model determines that all provided trajectories are flawed, it is instructed to re-think the problem independently to derive the correct answer.
The implementation of this workflow is further detailed in the readable skill documentation shown in the following image.

This documentation outlines specific protocols for the orchestrator, such as spawning parallel agents and managing the deliberation process. It emphasizes that the final output should contain only the synthesized answer in the appropriate format (e.g., boxed for math) rather than the meta-analysis itself.
Furthermore, the skill definition includes key principles for effective execution, as seen in the subsequent image.

These principles mandate that parallel agents remain independent and that deliberation focuses on synthesis rather than voting. For particularly challenging problems, the framework supports an optional iterative refinement loop. In this mode, the result from the sequential deliberation is fed back into the memory cache as an additional expert trajectory, allowing the system to re-run the deliberation phase until convergence is reached.
Experiment
The evaluation utilized diverse models across STEM and general reasoning benchmarks to compare a heavy thinking framework against standard baselines such as majority voting. Experiments validate that sequential deliberation consistently outperforms single-trajectory attempts, particularly on objective tasks where it synthesizes correct solutions beyond the raw reasoning potential of individual trajectories. While the framework demonstrates robust test-time scaling and compatibility with agentic tool use, findings indicate a trade-off between iterative depth and information consistency, with performance gains varying based on task subjectivity.
The authors evaluate a heavy thinking framework on various STEM benchmarks using both closed and open-weights models. Results indicate that combining parallel reasoning with sequential deliberation consistently yields higher performance than standard metrics like mean accuracy and majority voting. Furthermore, the framework demonstrates the ability to approach or exceed the intrinsic reasoning potential of the models, particularly on complex tasks. Heavy thinking metrics consistently outperform the average accuracy of parallel trajectories across all tested models. Sequential deliberation proves more effective than heuristic voting strategies, especially on challenging benchmarks. The potential of the deliberation process often matches or surpasses the raw pass rate of parallel sampling, indicating synthesized reasoning gains.
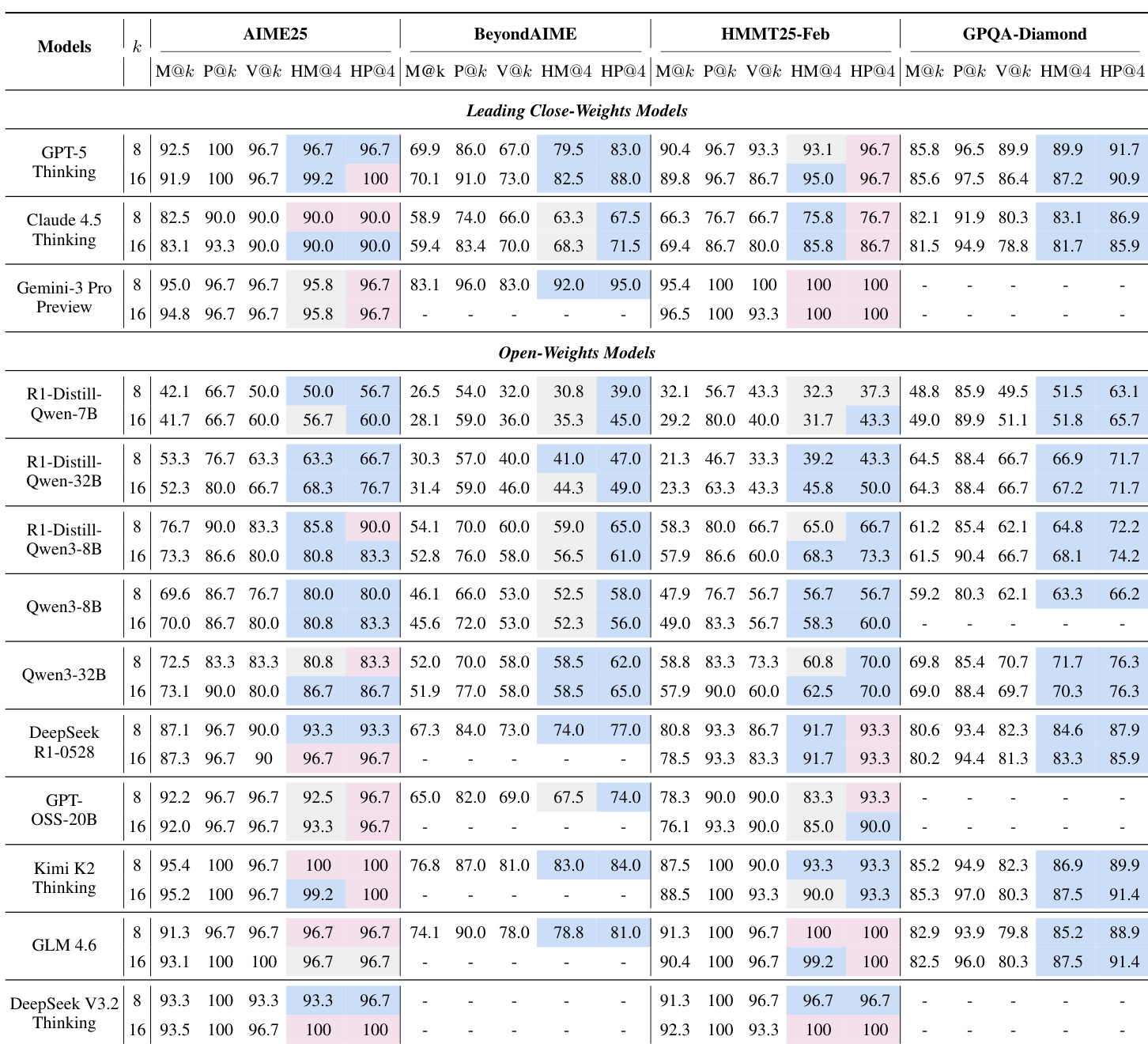
The authors evaluate a heavy thinking framework combining parallel reasoning with sequential deliberation on STEM benchmarks. Results indicate that the heavy thinking metric consistently surpasses standard metrics like majority voting and mean accuracy, demonstrating the effectiveness of synthesizing multiple reasoning paths. Furthermore, larger models achieve higher performance, with the framework helping them approach their theoretical reasoning limits. Heavy thinking consistently outperforms heuristic majority voting strategies across all evaluated models. Sequential deliberation provides a significant boost over the average accuracy of parallel reasoning trajectories. Larger models exhibit superior performance, with heavy thinking scores approaching the intrinsic potential of the raw trajectories.
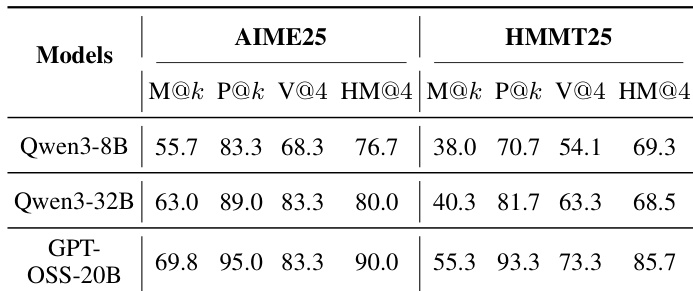
The authors evaluate a heavy thinking framework that combines parallel reasoning with sequential deliberation across various models and benchmarks. The results demonstrate that this approach yields substantial improvements on objective tasks involving coding and instruction following, while showing more limited benefits on subjective preference alignment. Furthermore, the deliberation process consistently unlocks higher performance potential than the initial parallel sampling alone. Sequential deliberation yields substantial performance gains on objective benchmarks like LiveCodeBench and IFEval compared to standard parallel reasoning. The framework provides marginal or inconsistent improvements on subjective tasks such as Arena-Hard where preference alignment is key. The deliberation phase consistently achieves higher potential pass rates than the raw parallel trajectories, indicating an ability to synthesize new correct solutions.
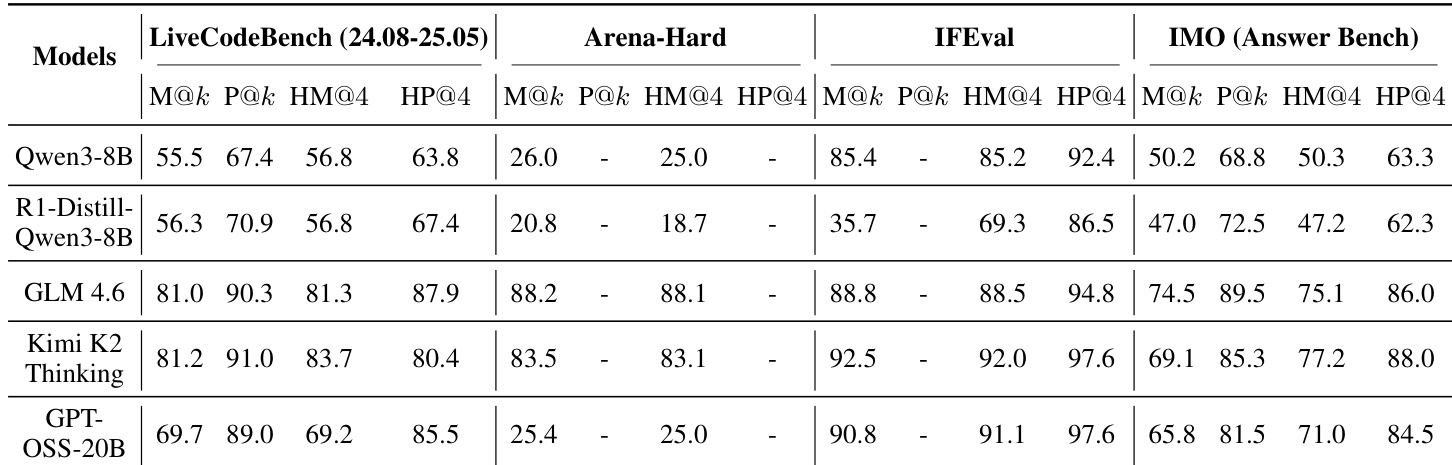
The authors evaluate a heavy thinking framework integrating parallel reasoning with sequential deliberation across diverse models and benchmarks including STEM, coding, and instruction following. Experiments demonstrate that sequential deliberation consistently outperforms standard heuristic voting strategies, unlocking higher performance potential than parallel sampling alone on objective tasks. While larger models approach their intrinsic reasoning potential with this method, the framework yields only marginal improvements on subjective preference alignment benchmarks.