Command Palette
Search for a command to run...
X2SAM : toute segmentation dans les images et vidéos
X2SAM : toute segmentation dans les images et vidéos
Hao Wang Limeng Qiao Chi Zhang Lin Ma Guanglu Wan Xiangyuan Lan Xiaodan Liang
Résumé
Les modèles de langage multimodaux de grande échelle (MLLM) ont démontré de solides capacités de compréhension visuelle et de raisonnement au niveau de l’image, mais leur perception au niveau des pixels, tant dans les images que dans les vidéos, reste limitée. Les modèles de segmentation de base, tels que la série SAM, produisent des masques de haute qualité, mais ils dépendent d’invites visuelles de bas niveau et ne peuvent pas interpréter nativement des instructions conversationnelles complexes. Les MLLM de segmentation existants comblent partiellement cette lacune, mais sont généralement spécialisés soit pour les images, soit pour les vidéos, et rarement capables de prendre en charge à la fois des invites textuelles et visuelles dans une même interface.Nous présentons X2SAM, un MLLM de segmentation unifié qui étend les capacités de segmentation « any-segment » des images aux vidéos. À partir d’instructions conversationnelles et d’invites visuelles, X2SAM couple un LLM avec un module de Mask Memory (mémoire des masques) qui stocke des caractéristiques visuelles guidées afin de générer des masques vidéo cohérents dans le temps. Cette même formulation prend en charge la segmentation générique, à vocabulaire ouvert, de référence, fondée sur le raisonnement, la génération de conversations ancrées (grounded), interactive et la segmentation visuellement ancrée (visual grounded), tant pour les entrées images que vidéos.Nous introduisons également le benchmark de segmentation Video Visual Grounded (V-VGD), qui évalue si un modèle peut segmenter des trajectoires d’objets dans des vidéos à partir d’invites visuelles interactives. Grâce à une stratégie d’entraînement conjointe unifiée sur des ensembles de données hétérogènes d’images et de vidéos, X2SAM offre des performances solides en segmentation vidéo, demeure compétitif sur les benchmarks de segmentation d’images, et préserve ses capacités générales de conversation avec images et vidéos.
One-sentence Summary
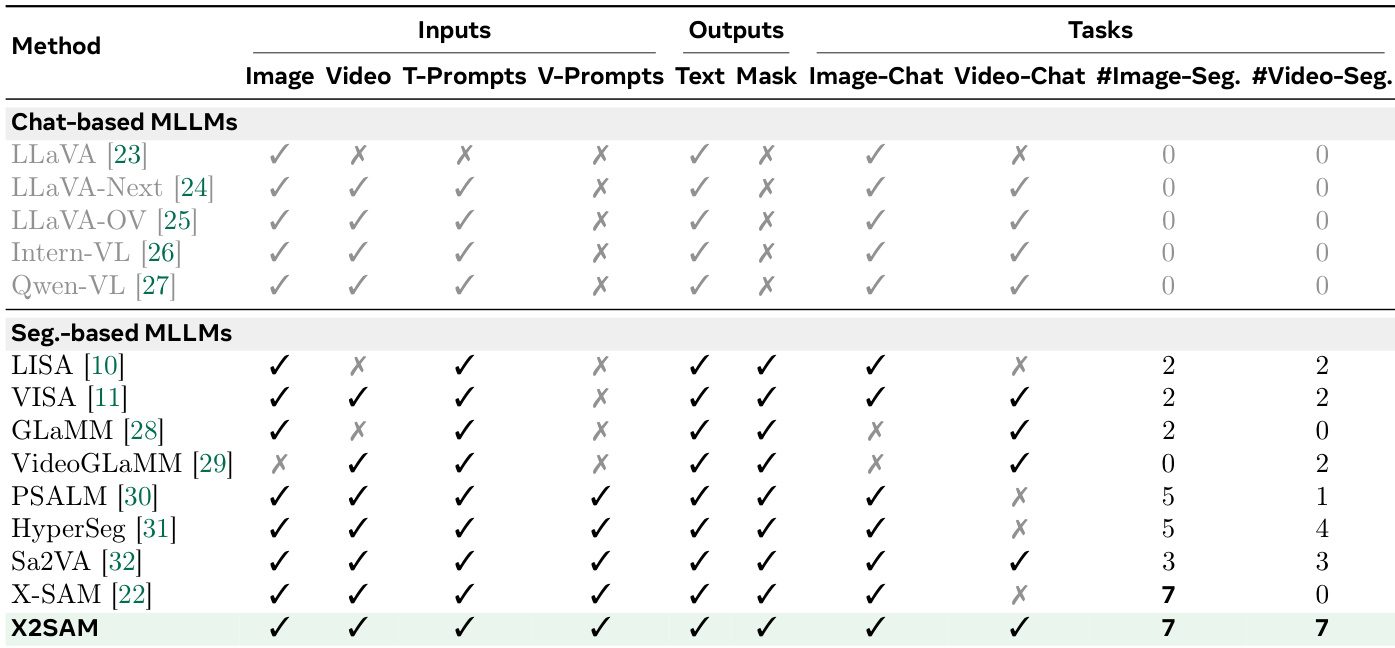
The authors propose X2SAM, a unified multimodal large language model that extends any-segmentation from images to videos by coupling an LLM with a Mask Memory module to store guided vision features for temporally consistent mask generation, natively supporting textual and visual prompts across diverse segmentation tasks while delivering strong video and competitive image performance, preserving conversational abilities through joint training on heterogeneous datasets, and introducing the Video Visual Grounded (V-VGD) benchmark to evaluate interactive prompt-based tracking.
Key Contributions
- X2SAM is introduced as a unified segmentation-oriented multimodal large language model that extends pixel-level any-segmentation capabilities from static images to dynamic video sequences. The architecture couples an LLM with a Mask Memory module that stores guided vision features to enable temporally consistent mask generation from conversational instructions and visual prompts.
- Diverse segmentation tasks, including open-vocabulary, referring, reasoning, and interactive grounding, are consolidated into a single instruction-following framework that natively processes both textual and visual inputs. This unified formulation jointly optimizes semantic grounding and memory-based temporal propagation to overcome the structural fragmentation of prior image-only or video-only models.
- The Video Visual Grounded (V-VGD) benchmark is introduced to evaluate video object grounding from interactive visual prompts, alongside an adaptive joint training strategy for heterogeneous image and video datasets. This training protocol enables competitive image segmentation performance, enhanced video segmentation accuracy, and preserved general multimodal chat capabilities.
Introduction
Multimodal large language models have transformed high-level visual understanding, yet generating precise pixel-level masks across both static images and dynamic videos remains essential for applications requiring fine-grained spatial and temporal analysis. Prior segmentation systems suffer from structural fragmentation, with image-focused models lacking temporal capabilities and video-centric approaches struggling to maintain mask consistency or natively process combined textual and visual prompts. To bridge this divide, the authors leverage a unified architecture that couples an LLM with a novel Mask Memory module to store guided vision features and enforce temporally coherent mask generation. This design enables a single conversational interface to execute diverse segmentation tasks across image and video inputs using interleaved text and visual prompts, while a joint training strategy on heterogeneous datasets delivers competitive performance across modalities without sacrificing general reasoning abilities.
Dataset
- Dataset Composition and Sources: The authors use a two-phase training pipeline that starts with the mask-only SA-1B dataset to initialize the mask decoder. The unified joint training phase then combines data across fourteen segmentation tasks spanning image and video modalities, alongside dedicated image and video chat corpora. All other benchmarks are strictly reserved for validation and zero-shot evaluation.
- Key Details for Each Subset: Image tasks follow the X-SAM mixed fine-tuning setup, utilizing COCO for generic segmentation, RefCOCO variants for referring tasks, ReasonSeg for reasoning, GLaMM-derived collections for grounded conversation, COCO-VGD for visual grounding, and LLaVA-1.5 for image chat. Video segmentation tasks draw from VIPSeg, VSPW, and YT-VIS19 for generic segmentation; YT-RefVOS21 and DAVIS17-RefVOS for referring; ReVOS for reasoning; VideoGLaMM-derived datasets for grounded conversation; and YT-VOS19 for object segmentation. The authors also introduce two newly constructed video visual grounded segmentation datasets. YT19-VGD builds directly on YT-VIS19 instance annotations to emphasize instance-centric objects. VIPSeg-VGD filters panoptic annotations to retain only thing categories with consistent instance identities across frames, providing denser multi-object contexts. Video chat training relies on the VideoInstruct100K corpus.
- Training Usage and Data Mixing: The authors train the model in two distinct stages. The first stage freezes the mask encoder and optimizes only the mask decoder as a binary classification task for one epoch. The second stage unfreezes the mask encoder and jointly trains the projectors, large language model, mask decoder, and mask memory through multi-task learning. To balance the diverse data sources, the authors apply dataset-balanced resampling with a temperature of 0.1. They also implement a modality-aware batching strategy that maintains a global batch size of 32 for video data while applying a four-fold multiplier to image data, achieving an effective global batch size of 128.
- Processing and Metadata Construction: Frame sampling is tailored to each task type. Most video segmentation tasks use consecutive frame sampling with a stride of one and a sequence length of eight frames. Video grounded conversation tasks employ a global sampling strategy to extract sixteen frames per clip, while video chat inputs expand to sixty-four frames to support long-range temporal understanding. For the newly constructed V-VGD datasets, each target object is paired with four automatically generated visual prompts (point, scribe, box, and mask) derived from the first visible annotated frame. The supervision target consists of the complete spatio-temporal mask sequence across the clip. During training, the system randomly samples one prompt type per instance to enhance robustness, whereas evaluation focuses primarily on point and box conditions. The large language model is fine-tuned using LoRA with a rank of 128 and a scaling factor of 256, and the mask memory is configured to store eight slots.
Method
The authors propose X2SAM, a segmentation-oriented multimodal large language model (MLLM) designed to extend segmentation capabilities from static images to dynamic video sequences. The overall framework operates as a dual-branch visual extraction system that processes both global and fine-grained visual features, integrating them with language instructions to generate a segmentation mask and a contextual language response. Refer to the framework diagram for an overview of the system architecture.
The input processing pipeline begins with a visual input Xv∈RT×H×W×C, where T=1 for images and T>1 for videos, and a textual instruction Xq. The visual input is processed through two complementary paths. The vision encoder fv, adopted from Qwen3-VL-4B, extracts global visual representations Zv by augmenting the input with timestamps, partitioning it into spatial patches, and projecting it into latent embeddings. Simultaneously, the mask encoder gm, derived from SAM2, processes the input frame-wise to capture fine-grained visual features Zm suitable for dense prediction. When region-specific information is needed, the region sampler gr extracts localized visual prompt embeddings from Zm using point-sampling and adaptive pooling to generate region-level features Hr. The textual instruction is formatted with task-specific templates, tokenized, and embedded into text latent representations Hq. The projected global features Hv, region features Hr, and textual embeddings Hq are then fed into the Large Language Model (LLM) fϕ.
The LLM auto-regressively generates a language response Yq and produces a dedicated latent embedding for the token, which acts as a semantic bridge between language understanding and mask prediction. This embedding is transformed by the MLLM projector into the prompt token embedding Zp. To maintain temporal coherence across video frames, the model employs a Mask Memory module. This module operates as a temporal cache, storing guided vision features from previous frames. The data flow of the Mask Memory module is detailed in the diagram below.
As shown in the figure below, the Mask Memory module consists of four components: Memory Attention, Mask Decoder, Memory Encoder, and Memory Bank. Memory Attention attends to guided vision features from previous frames to produce temporally-refined vision features Zw for the current frame. The Mask Decoder then generates the segmentation mask Ym by integrating Zp, learnable mask queries Qm, and Zw. After the mask is predicted, the Memory Encoder encodes the downsampled vision features and current-frame mask logits into a guided vision feature Zmt. This feature is stored in the Memory Bank, which updates the cache using a First-In-First-Out (FIFO) strategy. This fixed-size memory design ensures temporal consistency for video segmentation while bounding computational cost.
The Mask Decoder is redesigned to overcome limitations in parallel mask generation. Inspired by X-SAM, it incorporates structured attention modules: Query-to-Image Attention and Token-to-Image Attention. These modules allow the LLM's semantic token embedding Zp to directly interact with spatial features, enabling the decoder to generate masks that are spatially accurate and semantically aligned with the language instruction. The Token-to-Image Attention parameters are zero-initialized to ensure a smooth and stable integration of token-level conditional information during early training.
Training X2SAM involves a two-stage process. First, a category-agnostic segmentor training stage is performed to provide a stable initialization for the mask decoder. In this stage, the mask encoder is kept frozen, and only the mask decoder is optimized using a combined mask loss Lmask, which combines binary cross-entropy and dice loss. This encourages the decoder to learn class-independent shape and boundary priors.
Next, a unified joint training stage is conducted on heterogeneous image and video datasets. To handle the differing temporal lengths and memory footprints, a dimension-shifting pipeline is employed. The visual input tensor is transposed and split into frame-level tensors, which are processed by the mask encoder. Temporal dependencies are introduced via the mask memory module during sequential mask decoding. To optimize efficiency, modality-aware batching is used: the base per-device batch size is set to B=1 for videos to manage memory, while image-only batches are expanded. Gradient accumulation is also modality-specific, and a temporal-aware sampler groups video clips of the same length into batches. The joint training objective Ljoint integrates the auto-regressive loss for language generation, the mask loss for segmentation, and a focal loss for mask classification.
Experiment
The evaluation encompasses a comprehensive suite of image and video segmentation benchmarks alongside visual chat tasks to assess the model’s cross-modal generalization and temporal reasoning capabilities. Ablation experiments validate key architectural components, demonstrating that strategic parameter initialization, unified joint training, and multi-scale mask memory significantly enhance training efficiency and spatio-temporal alignment. Benchmark evaluations validate the model’s overall generalization, showing that it successfully preserves strong static image segmentation performance while substantially advancing video understanding compared to specialist and generalist multimodal baselines. Ultimately, the findings confirm that a unified formulation effectively bridges precise spatial grounding with complex temporal reasoning without compromising conversational abilities, though a performance gap remains compared to highly specialized video object segmentation models.
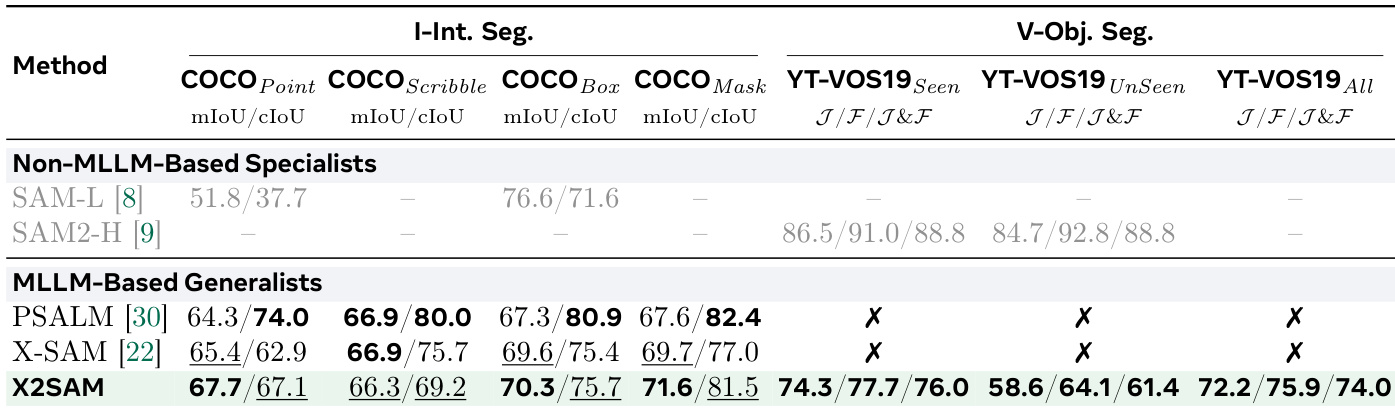
The the the table compares the performance of various methods on image and video object segmentation tasks, highlighting X2SAM's strong results across multiple benchmarks. X2SAM achieves competitive or superior performance compared to non-MLLM specialists and other MLLM-based generalists, particularly in video object segmentation and interactive segmentation tasks, while some methods are marked as unsupported or unreported. X2SAM achieves high performance on both image and video object segmentation tasks, outperforming other MLLM-based generalists and non-MLLM specialists. X2SAM shows strong results in interactive segmentation, with top scores on COCO Point, Scribble, and Box prompts. Some methods are marked as unsupported or unreported, indicating limitations in their applicability to certain segmentation benchmarks.
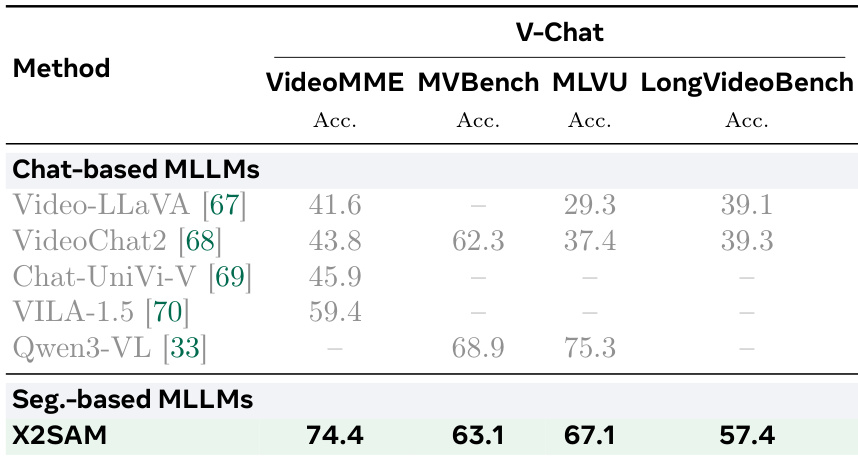
The authors compare the performance of X2SAM against other segmentation-based and chat-based multimodal language models on video chat benchmarks. Results show that X2SAM achieves competitive accuracy across multiple video chat tasks, outperforming several chat-centric models while maintaining strong segmentation capabilities. The model demonstrates consistent improvements in video understanding, particularly in long-form video comprehension and multi-modal reasoning. X2SAM outperforms several chat-based MLLMs on video chat benchmarks, achieving higher accuracy across multiple tasks. The model shows strong performance in long-form video comprehension, with notable gains on LongVideoBench compared to other methods. X2SAM achieves competitive results on multi-modal reasoning tasks, demonstrating its effectiveness in integrating segmentation and language understanding for video analysis.
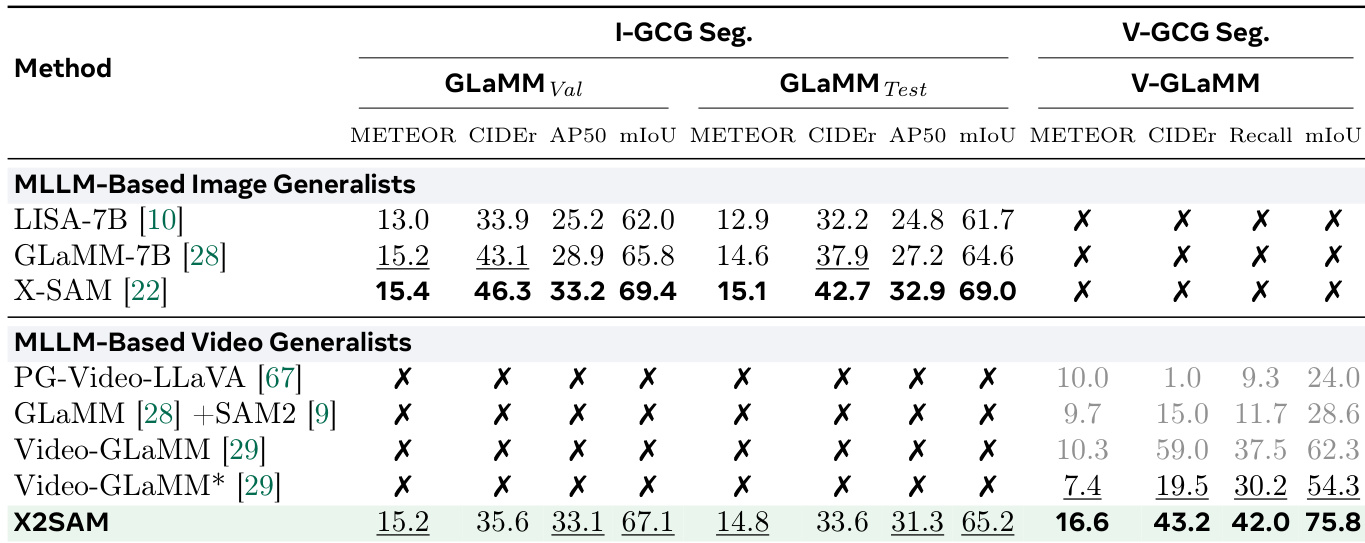
The authors compare the performance of different MLLMs on image and video segmentation tasks, evaluating their effectiveness across various benchmarks. Results show that the model with a specific vision encoder and LLM configuration achieves strong performance on both image and video segmentation, particularly excelling in video tasks with higher metrics compared to other models. The model maintains competitive performance on image segmentation while demonstrating significant improvements in video segmentation, especially in tasks requiring temporal reasoning and grounding. The model achieves strong performance on both image and video segmentation tasks, with notable improvements in video segmentation metrics compared to other models. The model maintains competitive performance on image segmentation benchmarks while showing significant gains in video segmentation, particularly in tasks requiring temporal reasoning. The model outperforms other MLLMs in video segmentation tasks, especially in video-referring and video-grounded conversation generation, demonstrating robust temporal comprehension.

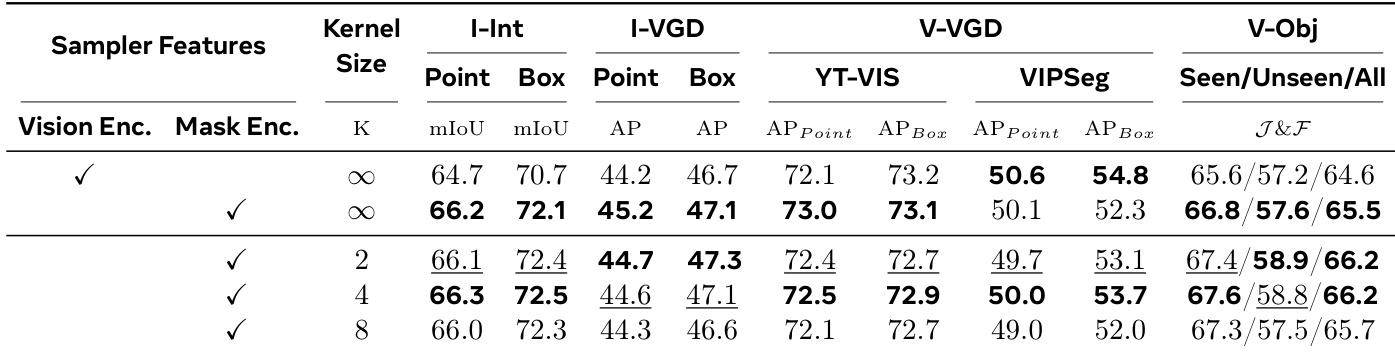
The authors compare X2SAM against existing methods on generic segmentation benchmarks for both image and video tasks. Results show that X2SAM achieves competitive performance on image segmentation tasks and outperforms other MLLM-based generalists on video generic segmentation, particularly on VSPW and YT-VIS19. The model maintains strong results across both domains without sacrificing performance on one for the other. X2SAM achieves state-of-the-art results on video generic segmentation benchmarks, surpassing previous MLLM-based generalists. X2SAM maintains competitive performance on image generic segmentation tasks compared to specialist models. The model demonstrates balanced performance across image and video domains, indicating effective generalization without domain-specific specialization.
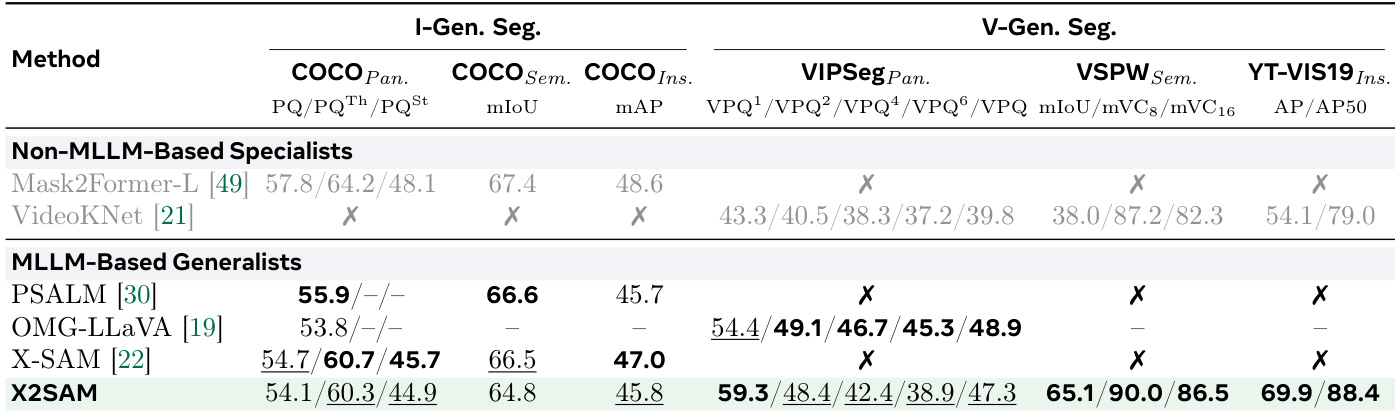
The the the table evaluates the impact of different region sampler configurations on segmentation performance across various benchmarks. It compares the use of vision encoder versus mask encoder features and different kernel sizes for spatial aggregation. Results show that using mask encoder features with a kernel size of 4 consistently improves performance across most tasks, particularly in image interactive and video visual grounded segmentation. The combination of these configurations leads to the best overall results on multiple benchmarks. Using mask encoder features consistently outperforms vision encoder features across most segmentation tasks. A kernel size of 4 achieves the best performance compared to larger or global aggregation kernels. The combination of mask encoder features and a kernel size of 4 yields the highest scores on multiple benchmarks, indicating optimal spatial aggregation for segmentation.
The experiments evaluate X2SAM against specialist and generalist multimodal models across image and video segmentation, interactive prompting, and video chat benchmarks to validate its capacity for unified spatial grounding and temporal reasoning. Primary evaluations demonstrate that the model consistently matches or exceeds competing methods in long-form video comprehension and cross-modal understanding while maintaining balanced performance across distinct visual domains. Supplementary ablation studies further confirm that leveraging mask encoder features with optimized spatial aggregation kernels effectively enhances segmentation accuracy, highlighting the architectural choices that enable robust video analysis.