Command Palette
Search for a command to run...
La mémoire visuelle persistante : Maintien de la perception pour la génération profonde dans les LVLMs
La mémoire visuelle persistante : Maintien de la perception pour la génération profonde dans les LVLMs
Siyuan Huang Xiaoye Qu Yafu Li Tong Zhu Zefeng He Muxin Fu Daizong Liu Wei-Long Zheng Yu Cheng
Résumé
Bien que les modèles de langage visuel autogressifs (LVLMs) démontrent une compétence remarquable dans les tâches multimodales, ils sont confrontés à un phénomène de « dilution du signal visuel » : l’accumulation de l’historique textuel élargit la fonction de partition d’attention, provoquant une décroissance de l’attention visuelle en proportion inverse de la longueur de la séquence générée. Pour contrer ce problème, nous proposons une mémoire visuelle persistante (PVM), un module léger et apprenable conçu pour assurer une perception visuelle soutenue et à la demande. Intégré en parallèle à la réseau de neurones à propagation avant (FFN) des LVLMs, le PVM établit un chemin de récupération indépendant de la distance, qui fournit directement les embeddings visuels pour une perception visuelle précise, atténuant ainsi structurellement la suppression de signal inhérente à la génération en profondeur. Des expériences étendues sur les modèles Qwen3-VL montrent que le PVM apporte des améliorations notables avec une surcharge négligeable en paramètres, offrant des gains moyens constants en précision pour les échelles 4B et 8B, en particulier dans les tâches de raisonnement complexes nécessitant une perception visuelle persistante. En outre, une analyse approfondie révèle que le PVM peut résister à la décroissance du signal induite par la longueur et accélérer la convergence de la prédiction interne.
One-sentence Summary
To counteract visual signal dilution in autoregressive large vision-language models, the authors propose Persistent Visual Memory (PVM), a lightweight parallel module integrated alongside the feed-forward network that establishes a distance-agnostic retrieval pathway to sustain visual perception, resisting length-induced signal decay while delivering consistent accuracy gains across 4B and 8B Qwen3-VL models on complex reasoning tasks with negligible parameter overhead.
Key Contributions
- This work introduces Persistent Visual Memory (PVM), a lightweight parallel module integrated alongside the Feed-Forward Network to address visual signal dilution in autoregressive Large Vision-Language Models.
- PVM establishes a distance-agnostic retrieval pathway that directly supplies visual embeddings on demand, structurally decoupling visual perception from expanding textual history to suppress length-induced hallucinations.
- Evaluations on the Qwen3-VL 4B and 8B models demonstrate consistent accuracy gains across diverse benchmarks with negligible parameter overhead, while effectively resisting signal decay and accelerating prediction convergence.
Introduction
Large vision-language models have transformed multimodal intelligence by bridging visual encoders with language models, enabling complex reasoning and extended dialogue. As these systems tackle longer generation tasks, maintaining visual fidelity becomes essential to prevent hallucinations and ensure reliable, fact-grounded outputs. Standard autoregressive architectures suffer from visual signal dilution, where static image tokens are progressively drowned out by accumulating textual history. Previous mitigation strategies rely on direct visual injection or complex context management, which often disrupt linguistic coherence, alter model backbones, or sacrifice fine-grained visual details. The authors leverage a lightweight parallel module called Persistent Visual Memory to decouple visual retrieval from the autoregressive flow. By integrating a gated cross-attention mechanism alongside the standard feed-forward network, the design establishes a dedicated pathway that continuously accesses original visual embeddings. This approach sustains high-fidelity perception across extended contexts without interfering with logical reasoning, delivering consistent performance gains across multiple benchmarks.
Dataset
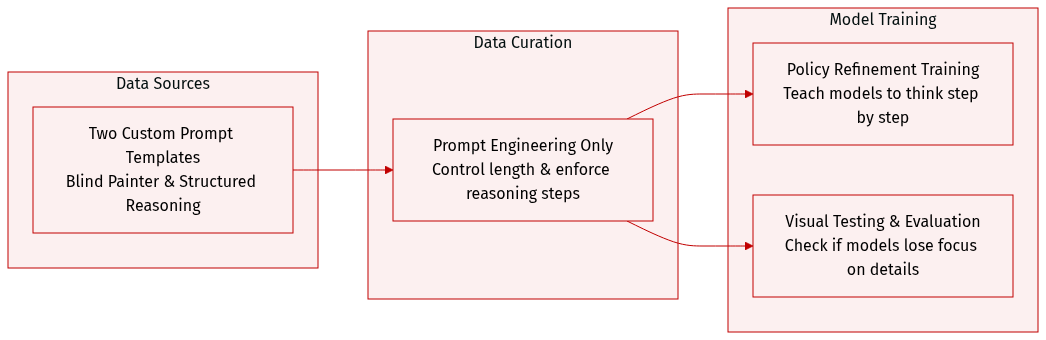
-
Dataset Composition and Sources: The authors construct a specialized instruction corpus centered on two custom prompt templates rather than relying on a pre-existing external dataset. These templates serve as the primary data generation and structuring mechanism for both training and evaluation.
-
Subset Details:
- Visual Stress Test (Blind Painter): This template explicitly demands exhaustive visual descriptions ("every single brushstroke") and forces long-form, continuous text generation to isolate sustained visual attention and prevent generic hallucinations.
- Structured Reasoning: Adapted from OpenMMReasoner-SFT-874K, this template enforces a structured Chain-of-Thought workflow by requiring models to output an internal reasoning monologue within
<anth Thinking>tags before producing final answers.
-
Training and Evaluation Usage: The authors apply the Visual Stress Test to empirically verify the Visual Signal Dilution phenomenon, while the Structured Reasoning template guides the policy refinement training stage and subsequent model assessments. Both templates are integrated directly into the instruction fine-tuning pipeline.
-
Processing and Formatting Details: The authors forgo traditional data filtering, cropping, or metadata construction. Instead, they rely on strict prompt engineering to control output length, enforce continuous visual dependency, and standardize reasoning steps. These directive constraints effectively shape the dataset's structure and model behavior across all phases.
Method
The authors leverage a parallel architecture to address the visual signal dilution problem inherent in autoregressive Large Vision-Language Models (LVLMs). The proposed Persistent Visual Memory (PVM) module is integrated as a parallel branch alongside the Feed-Forward Network (FFN) within the Transformer decoder block. This design establishes a dedicated, distance-agnostic retrieval pathway that directly accesses visual embeddings, thereby structurally mitigating the signal suppression caused by the accumulation of textual history.
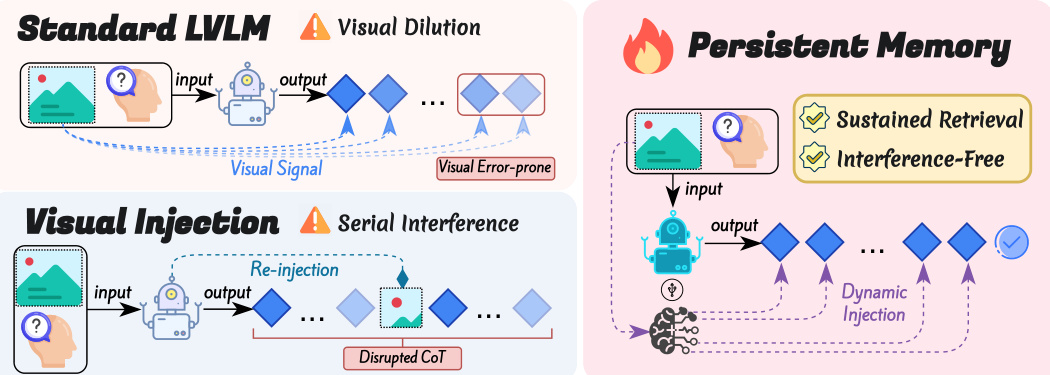
Refer to the framework diagram, which illustrates the core contrast between the standard LVLM and the PVM-enhanced architecture. In the standard LVLM, visual signals are subject to dilution and interference as the autoregressive generation process unfolds, leading to a decay in visual attention mass. In contrast, the PVM framework ensures sustained and interference-free visual retrieval by isolating the visual perception process from the main reasoning stream. The module treats the hidden state from the Multi-Head Self-Attention (MHSA) layer as a query to retrieve specific visual contexts, enabling active visual retrieval during the generation process.
As shown in the figure below, the PVM module operates in three stages to ensure parameter efficiency and minimize inference overhead. First, the input hidden state and the visual features are projected into a lower-dimensional latent space using independent learnable reducers. This projection step serves as a bottleneck adapter, distilling core visual semantics and filtering redundancy. Second, a cross-attention mechanism is performed where the projected hidden state acts as the query and the projected visual features serve as both keys and values. This operation restricts the attention domain solely to the visual set, realizing independent attention normalization. A lightweight feed-forward network is applied to refine the latent features. Finally, the refined latent feature is projected back to the original high-dimensional space via an up-projection matrix.
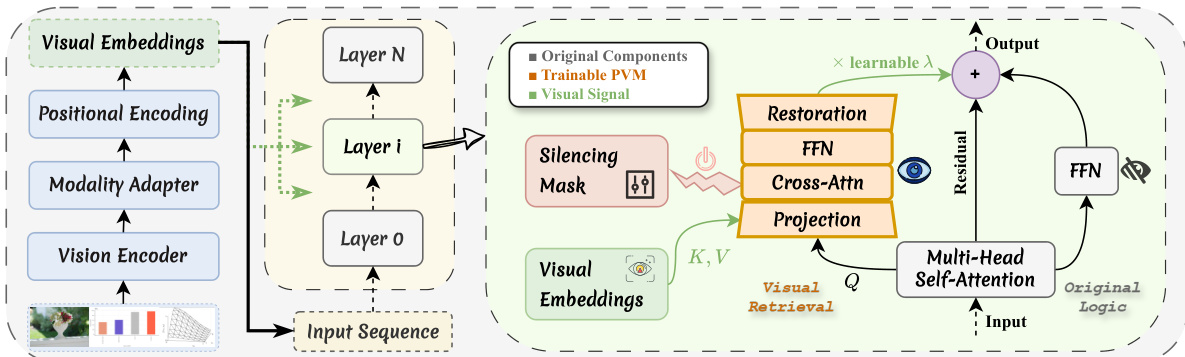
The visual memory is injected into the main stream via a residual connection controlled by a learnable scalar gate. To preserve the integrity of visual representations, a Visual Silencing Mask is employed, which activates the module only for text tokens. This selective activation prevents redundant self-referencing by visual tokens and ensures that the visual signal is injected only when needed. The final output is computed as the sum of the original hidden state, the FFN output, and the gated visual injection, maintaining the same shape as the input and allowing for seamless integration into the backbone without structural changes.
Experiment
The evaluation employs a comprehensive suite of multimodal benchmarks and ablation studies on Qwen3-VL architectures to validate the Persistent Visual Memory framework. Performance benchmarks and extended generation tests confirm that the method effectively counteracts inherent visual signal dilution, substantially stabilizing model outputs across long reasoning chains. Mechanistic probing and ablation studies further demonstrate that these gains originate from active raw visual retrieval and a strided layer injection strategy, which accelerate predictive convergence without relying on passive parameter expansion. Ultimately, the approach delivers consistent improvements across diverse tasks while introducing negligible inference overhead.
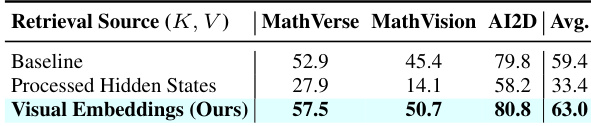
The authors conduct an ablation study to evaluate the impact of different retrieval sources on model performance, comparing raw visual embeddings against processed hidden states. Results show that using raw visual embeddings leads to superior performance across all benchmarks, while replacing them with processed hidden states causes a significant drop in accuracy, particularly in reasoning tasks. This indicates that the model's gains are driven by the ability to retrieve unprocessed visual signals rather than relying on text-dominated representations. Using raw visual embeddings leads to higher performance compared to processed hidden states across all benchmarks. Replacing raw visual embeddings with processed hidden states results in severe performance degradation, especially in reasoning tasks. The improvement from raw visual retrieval is attributed to the model's ability to access unprocessed visual signals rather than text-dominated representations.
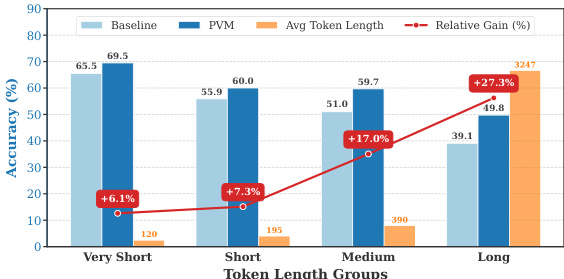
The authors conduct an empirical analysis to evaluate the effectiveness of their Persistent Visual Memory (PVM) framework in mitigating visual signal dilution during long-form multimodal generation. Results show that PVM consistently improves performance across various sequence lengths, with gains becoming significantly more pronounced in longer outputs. The approach demonstrates a strong positive correlation between generation length and relative improvement, indicating that PVM is particularly effective in stabilizing reasoning chains where visual attention tends to decay. PVM shows the greatest relative improvement in longer generation tasks, with performance gains increasing as sequence length grows. The improvement provided by PVM is consistent across different token length groups, demonstrating its robustness to extended generation. PVM achieves significant performance gains in long sequences, where baseline models typically suffer from severe visual attention dilution.
The authors compare their PVM-8B model against a baseline MLP variant and a standard SFT+GRPO setup across multiple multimodal reasoning benchmarks. Results show that PVM consistently outperforms both baselines, achieving higher average accuracy and demonstrating improvements across individual tasks. The performance gains are attributed to the model's ability to actively retrieve and integrate visual signals during generation, rather than increased parameter capacity. PVM-8B achieves higher average accuracy and outperforms both the MLP baseline and SFT+GRPO across all evaluated benchmarks. The performance improvement of PVM is consistent across individual tasks, with notable gains in MMBench-CN, MMT, and AI2D. The gains are attributed to the model's active visual retrieval mechanism rather than increased parameter count, as shown by the inferior performance of an iso-parameter MLP baseline.

The authors compare the inference performance of their PVM-enhanced model against the baseline Qwen3-VL model, focusing on decoding throughput and time per output token. Results show that the PVM-enhanced model achieves slightly lower throughput and higher decoding latency compared to the baseline, indicating a small but measurable increase in computational cost during generation. The PVM-enhanced model exhibits a slight reduction in decoding throughput compared to the baseline model. The time per output token increases marginally in the PVM-enhanced model, indicating a small latency overhead. Despite the minor increase in latency, the PVM-enhanced model maintains high-speed generation with negligible impact on real-time inference capability.

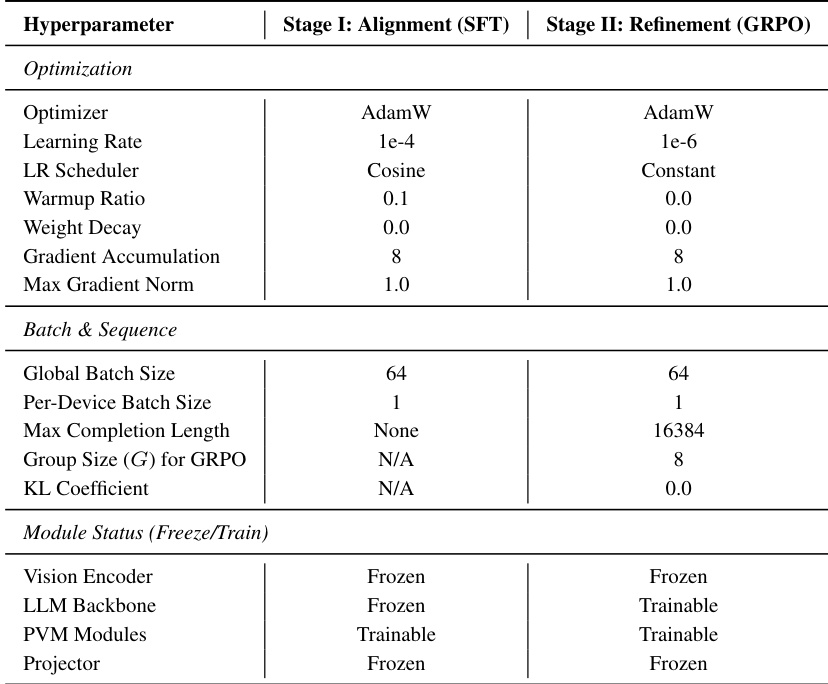
The authors present a two-stage training pipeline for their Persistent Visual Memory (PVM) method, with distinct optimization settings for the alignment and refinement stages. The first stage uses a high learning rate and cosine scheduling with frozen vision and LLM backbones, while the second stage employs a lower learning rate and constant scheduling, allowing the LLM and PVM modules to be trained while keeping the vision encoder frozen. The training pipeline consists of two stages with different optimization settings, including distinct learning rates and schedulers. The vision encoder and LLM backbone are frozen during the first stage, while the LLM and PVM modules are trainable in the second stage. The PVM modules are trainable in both stages, but the projector is frozen throughout the training process.
The evaluation framework assesses a Persistent Visual Memory (PVM) approach across multimodal reasoning benchmarks through targeted ablation studies, comparative baseline tests, and efficiency analyses. Experimental validation confirms that directly retrieving raw visual embeddings is essential for maintaining reasoning accuracy, while the memory mechanism effectively counters attention dilution in long-form generation, with performance benefits scaling as sequence length increases. Comparative benchmarks further demonstrate that PVM consistently outperforms parameter-matched and standard fine-tuning variants, proving that its advantages stem from active visual signal integration rather than increased model capacity. Finally, efficiency tests reveal that the memory retrieval process introduces only minimal computational overhead, preserving real-time inference capabilities.