Command Palette
Search for a command to run...
WindowsWorld : Une évaluation centrée sur le processus des agents autonomes d'interface graphique dans des environnements professionnels interapplications
WindowsWorld : Une évaluation centrée sur le processus des agents autonomes d'interface graphique dans des environnements professionnels interapplications
Jinchao Li Yunxin Li Chenrui Zhao Zhenran Xu Baotian Hu Min Zhang
Résumé
Bien que les agents d’interface graphique (GUI agents) aient démontré des capacités impressionnantes dans des tâches courantes d’utilisation d’un ordinateur telles que celles évaluées dans OSWorld, les benchmarks actuels se concentrent principalement sur des tâches isolées et confinées à une seule application. Cette approche néglige une exigence critique du monde réel : la coordination entre plusieurs applications pour accomplir des flux de travail professionnels complexes. Pour combler cette lacune, nous présentons un benchmark d’utilisation d’ordinateur centré sur les flux de travail inter-applications, nommé WindowsWorld, conçu pour évaluer systématiquement les agents GUI sur des tâches complexes en plusieurs étapes qui reflètent les activités professionnelles réelles.Notre méthodologie s’appuie sur un cadre multi-agents piloté par seize métiers différents afin de générer des tâches à quatre niveaux de difficulté, incluant des étapes intermédiaires de vérification. Ces tâches sont ensuite affinées par des experts humains et exécutées dans un environnement simulé. Le benchmark résultant comprend 181 tâches, présentant en moyenne 5,0 sous-objectifs répartis sur 17 applications de bureau courantes, dont 78 % sont intrinsèquement inter-applications.Les résultats expérimentaux obtenus avec les grands modèles et agents les plus performants montrent que : 1) Tous les agents d’utilisation d’ordinateur réalisent de mauvaises performances sur les tâches inter-applications (un taux de succès inférieur à 21 %), bien en deçà de leurs résultats sur des tâches simples limitées à une seule application ; 2) Ils échouent largement sur les tâches nécessitant un jugement conditionnel et un raisonnement impliquant trois applications ou plus (≥ 3 applications), bloquant généralement dès les premiers sous-objectifs ; 3) Leur efficacité d’exécution est faible, de nombreuses tâches échouant malgré un nombre d’étapes nettement supérieur à la limite humaine typique.Le code source, les données du benchmark ainsi que les ressources d’évaluation sont disponibles à l’adresse suivante : github.com/HITsz-TMG/WindowsWorld.
One-sentence Summary
The authors introduce WindowsWorld, a process-centric benchmark that evaluates autonomous GUI agents on 181 professional cross-application tasks across 17 desktop applications by employing a multi-agent framework guided by 16 occupations to generate four difficulty-level tasks refined through human review.
Key Contributions
- This work introduces WindowsWorld, a benchmark comprising 181 tasks across 17 desktop applications to evaluate GUI agents on complex professional workflows. The framework incorporates a fine-grained intermediate checking mechanism that assigns partial-progress scores for discriminative evaluation of long-horizon planning.
- A human-in-the-loop multi-agent pipeline is presented to automatically synthesize persona-driven task instructions and necessary file dependencies for realistic evaluation scenarios. This automated construction process significantly reduces manual curation costs while preserving fidelity to authentic professional routines.
- Extensive evaluations demonstrate a substantial performance decline when agents transition from single-application tasks to cross-application workflows. The top-performing model, Gemini-3-flash-preview, achieves only a 20% success rate, confirming that current systems struggle with the non-linear planning and file dependencies required for multi-application productivity.
Introduction
Autonomous GUI agents are advancing rapidly to navigate complex digital environments, yet real-world professional workflows demand seamless coordination across multiple applications. Current benchmarks largely overlook this requirement by prioritizing isolated single-app tasks and relying on binary success metrics that obscure diagnostic insights into partial progress. Furthermore, traditional dataset creation remains labor-intensive and struggles to replicate authentic cross-application dependencies. To address these gaps, the authors introduce WindowsWorld, a process-centric benchmark featuring 181 multi-application tasks generated through a scalable human-in-the-loop multi-agent pipeline. By implementing fine-grained intermediate checkpoints for granular performance evaluation, they demonstrate that leading GUI agents struggle with cross-application coordination, achieving success rates below 21 percent and highlighting a critical gap between current capabilities and professional productivity demands.
Dataset

Dataset Composition and Sources
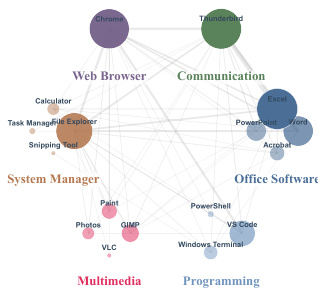
- The authors construct WindowsWorld, a desktop GUI benchmark built upon the OSWorld infrastructure and featuring 181 tasks across 17 Windows applications.
- Task instructions are generated through an LLM-assisted pipeline and rigorously filtered by four postgraduate researchers to ensure technical accuracy and workflow realism.
- The dataset integrates a taxonomy of 16 professional personas to ground each instruction in authentic, domain-specific routines rather than generic commands.
Subset Details and Filtering Rules
- Tasks are divided into four complexity levels: L1 (single-app atomic), L2 (multi-app linear), L3 (dynamic reasoning), and L4 (intentionally infeasible).
- L1 tasks average 9.67 minimum expert actions, L2 tasks average 18.13, and L3 tasks average 27.81, reflecting escalating horizon lengths.
- Design rules dictate that 71.8 percent of tasks are non-trivial (L2/L3), while 77.9 percent span two or more applications with an average of 2.4 apps per task.
- L4 tasks are deliberately constructed with invalid URLs, missing files, or authentication barriers to test agent failure handling and goal rejection.
Data Usage and Processing Framework
- The authors use WindowsWorld exclusively as an evaluation benchmark rather than a training corpus, meaning no training splits or mixture ratios are applied.
- Processing focuses on process-aware evaluation, where agents are scored against explicit intermediate checkpoints instead of relying on binary final-state matching.
- Each task contains an average of 4.97 checkpoints, with higher complexity levels featuring denser verification points to pinpoint reasoning and execution bottlenecks.
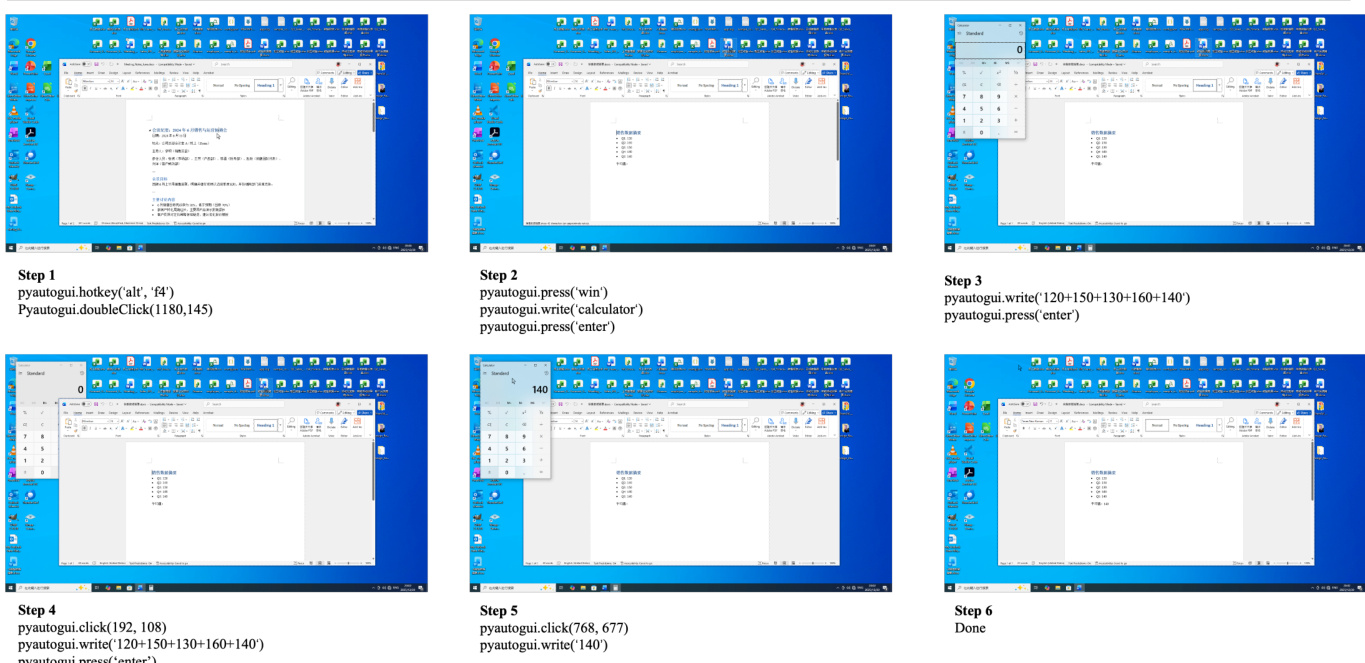
- The evaluation environment standardizes the action space across mouse control, keyboard input, and system-level signals to ensure consistent testing conditions.
Metadata Construction and Specialized Processing
- Task metadata is structured in JSON format, containing the natural language instruction, task category, involved applications, and evaluation metrics.
- The environment_setup field follows strict conditional rules: it is populated only when tasks require operating on pre-existing local files, and remains empty for web searches, new file creation, or system tool usage.
- A multi-node generation pipeline handles persona conditioning, dependency reasoning, and metric refinement, with automated assertions generated for each checkpoint.
- While image cropping appears as a task-level operation in specific examples, the dataset does not apply a global cropping strategy. Processing instead prioritizes validating intermediate states and maintaining trajectory stability across application switches.
Method
The authors leverage a human-in-the-loop multi-agent pipeline to construct the WindowsWorld benchmark, ensuring both ecological validity and scalability in task generation. The overall framework consists of four sequential stages: Generator, Refiner, Human Reviewer, and Environment Generator. Each stage plays a distinct role in transforming high-level user intents into executable, verifiable tasks within a controlled Windows environment.
The Generator stage initiates the process by leveraging a large language model (LLM), specifically DeepSeek-V3.2, to generate task instructions grounded in distinct professional personas such as Accountant or Software Engineer. The generator receives structured prompts that include daily work routines and application-specific dependencies, ensuring the generated tasks reflect realistic workflows. To maintain authenticity, the generator is constrained to reference only accessible resources from open platforms like GitHub, Wikipedia, and Stack Overflow, avoiding synthetic or inaccessible URLs. This stage produces candidate tasks that are then passed to the Refiner for quality assurance.
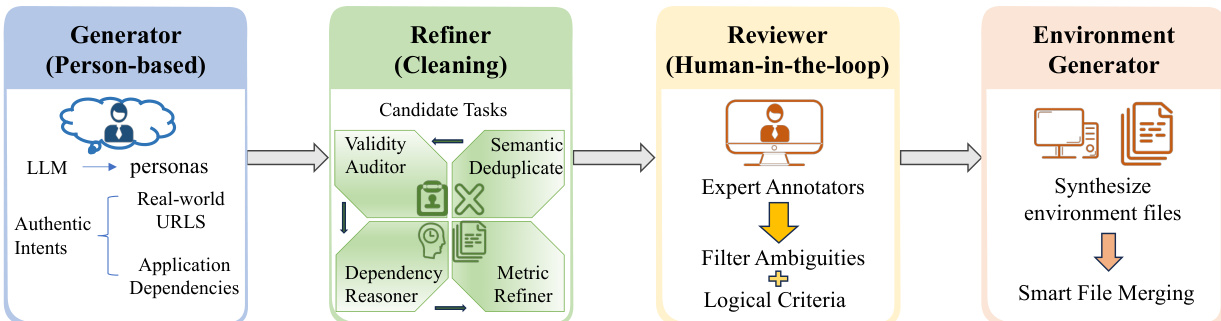
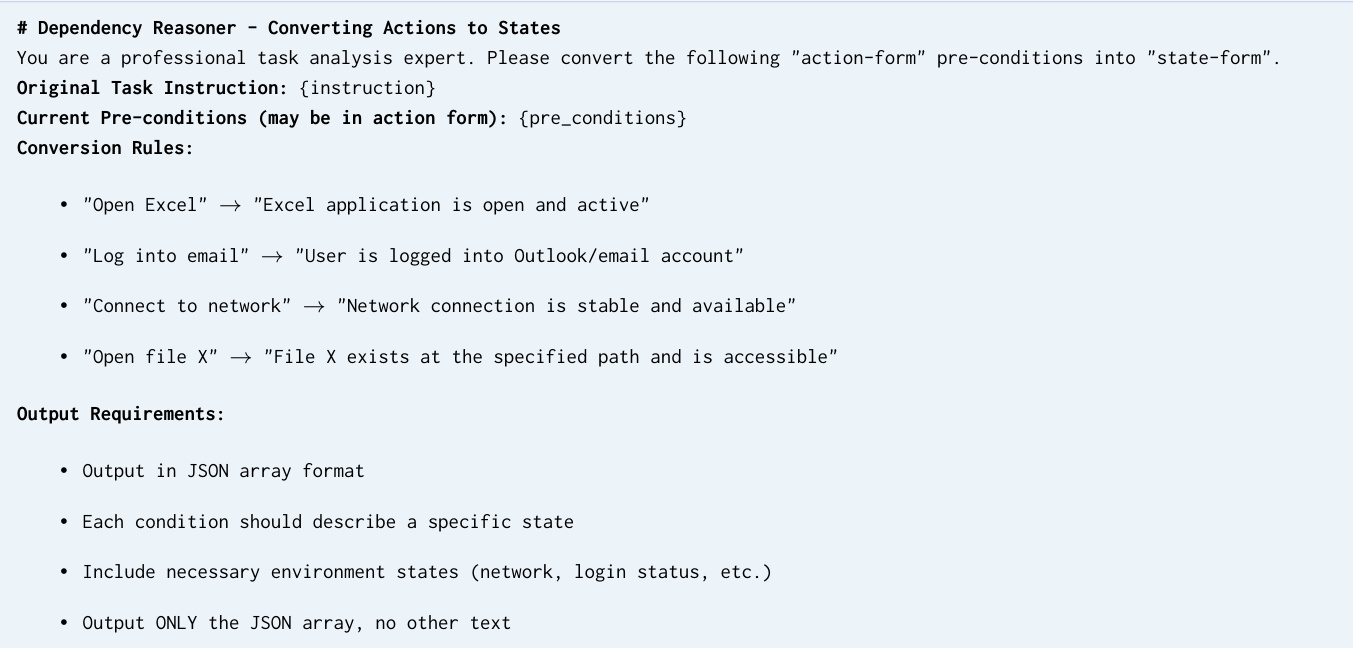
The Refiner stage employs a four-node automated pipeline to validate and standardize the candidate tasks. First, the Semantic Deduplicator computes pairwise cosine similarity between task instruction embeddings and prunes near-duplicates exceeding a threshold of 0.85, ensuring diversity across the dataset. The Validity Auditor performs asynchronous HTTP requests to verify URL accessibility and cross-references file mentions in instructions against the defined environment setup, flagging inconsistencies. The Dependency Reasoner transforms procedural preconditions, such as "open the spreadsheet," into declarative environment states like "spreadsheet exists at specified path," enabling deterministic setup verification. Finally, the Metric Refiner reviews and standardizes evaluation criteria to ensure each intermediate checkpoint is unambiguous and verifiable against the expected task outcomes.
Following automated validation, the Human Reviewer stage performs final quality control. Four expert annotators assess the tasks, rejecting those with ambiguous or under-specified instructions, evaluation criteria relying on subjective judgments, or requirements for unavailable proprietary software or inaccessible external services. This human-in-the-loop step ensures that the benchmark contains high-quality, unambiguous tasks that are suitable for evaluation.
The Environment Generator stage synthesizes the required environment files for each validated task. It uses LLM-based content synthesis to create necessary files such as .xlsx, .docx, and .py, ensuring the environment is fully prepared for execution. A Smart File Merging strategy is employed to analyze demands across multiple tasks within the same persona, creating consistent data resources that can be reused, thereby enhancing efficiency and reducing redundancy.
To evaluate agent performance, the authors propose a process-aware evaluation protocol that moves beyond traditional "all-or-nothing" scoring. This protocol defines two metrics: Intermediate Check Score (Sint) and Final Check Score (Sfinal). The Intermediate Check Score is evaluated on L1-L3 tasks and rewards partial progress by tracking essential sub-goals, preventing zero scores on complex tasks where a substantial portion of the workflow is completed. The Final Check Score, applied across L1-L4, assesses the correctness of the terminal state, including the agent's ability to correctly reject infeasible instructions in Level-4 tasks. Intermediate checkpoints are extracted by an LLM and refined to remove action-specific constraints, retaining only essential semantic states. All checkpoints are human-verified to be path-essential, ensuring evaluation is state-based and tolerant to alternative valid execution paths.
The evaluation process relies on an automated judge implemented via Qwen3-VL-Plus, which outputs binary decisions. The reliability of this VLM judge has been validated against human annotators, showing strong agreement in both intermediate and final judgments. The benchmark also supports multiple observation modalities, including Raw Screenshot, Set-of-Marks (SoM), and Screenshot + Accessibility Tree (Hybrid), to assess the impact of different input representations on agent performance. The action space provided includes free-form pyautogui and computer_13, with pyautogui being the primary choice for experiments. This comprehensive framework ensures that the WindowsWorld benchmark is both realistic and rigorously evaluated, providing a robust foundation for assessing computer-use agents in complex, multi-application environments.
Experiment
The evaluation benchmarks a diverse suite of general-purpose and specialized GUI agents across multi-step, cross-application Windows tasks while validating the impact of different input modalities, external grounding frameworks, and fine-grained intermediate checkpoints on execution progress. Qualitative analysis reveals a persistent efficiency-completion gap where agents demonstrate meaningful intermediate progress but consistently fail to successfully conclude complex workflows due to weaknesses in cross-application coordination, state maintenance, and the recognition of infeasible instructions. Structured interface metadata proves more reliable than raw visual inputs or heuristic overlays, which often introduce cognitive noise, while external grounding frameworks yield diminishing returns as foundation model capabilities improve. Ultimately, the findings underscore that current state-of-the-art models lack robust long-horizon reasoning and global plan consistency, highlighting the critical need for process-aware evaluation metrics to accurately diagnose execution bottlenecks and guide future agent development.
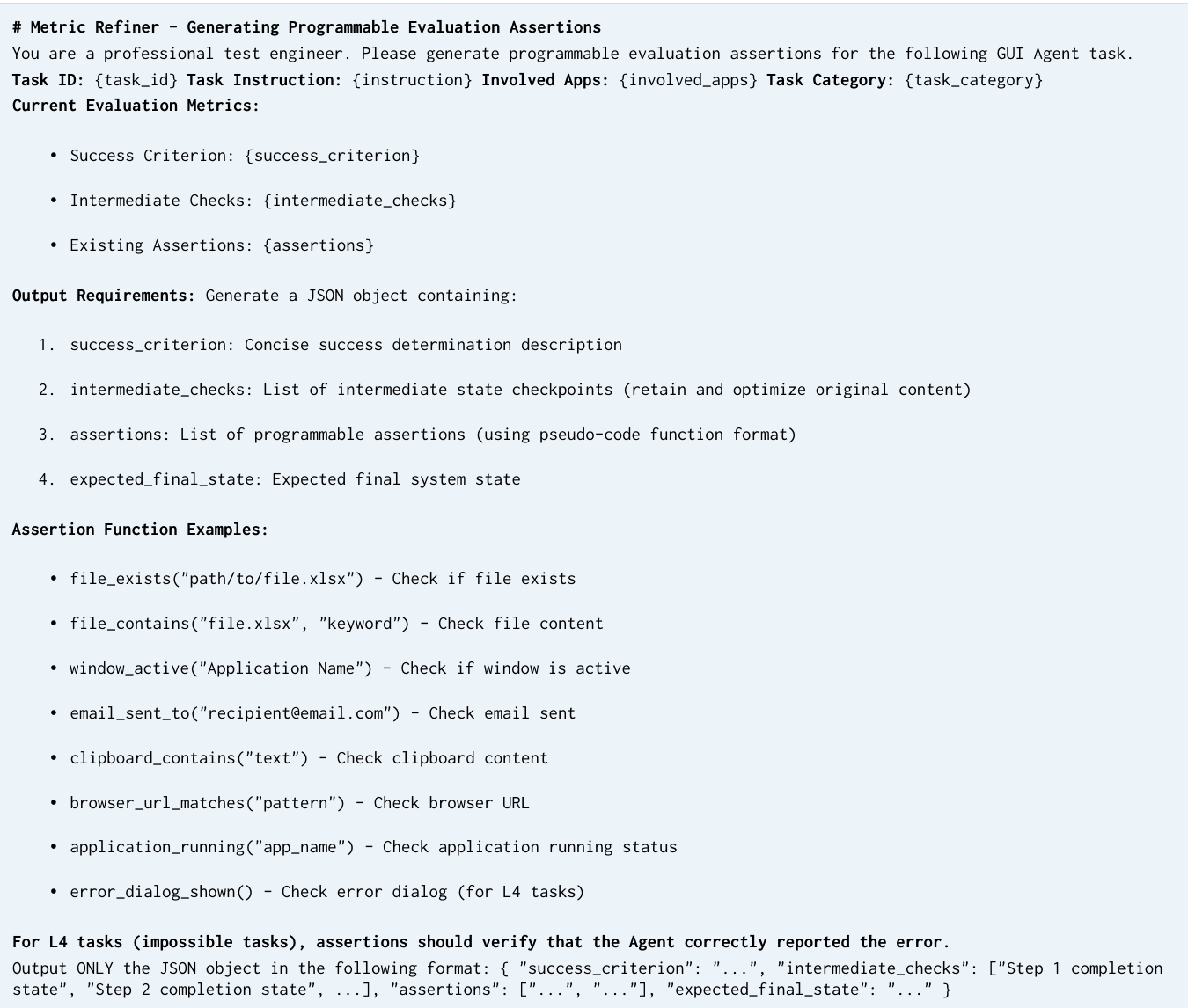
The authors evaluate a range of large models and specialized agents on a cross-application WindowsWorld benchmark, focusing on task complexity, observation modalities, and model performance across different professional personas. Results show that while some models achieve high intermediate progress, they often fail to complete tasks successfully, especially in complex, multi-app scenarios. The evaluation highlights significant gaps between progress and completion, with performance varying widely by input modality, task type, and user role. Models exhibit a large gap between intermediate progress and final task completion, particularly in complex multi-app tasks. Performance varies significantly by observation modality, with structured inputs like accessibility trees improving intermediate scores more consistently than raw screenshots or visual overlays. Different professional personas show distinct difficulty patterns, with productivity-oriented tasks revealing a pronounced progress-completion discrepancy due to late-stage coordination failures.
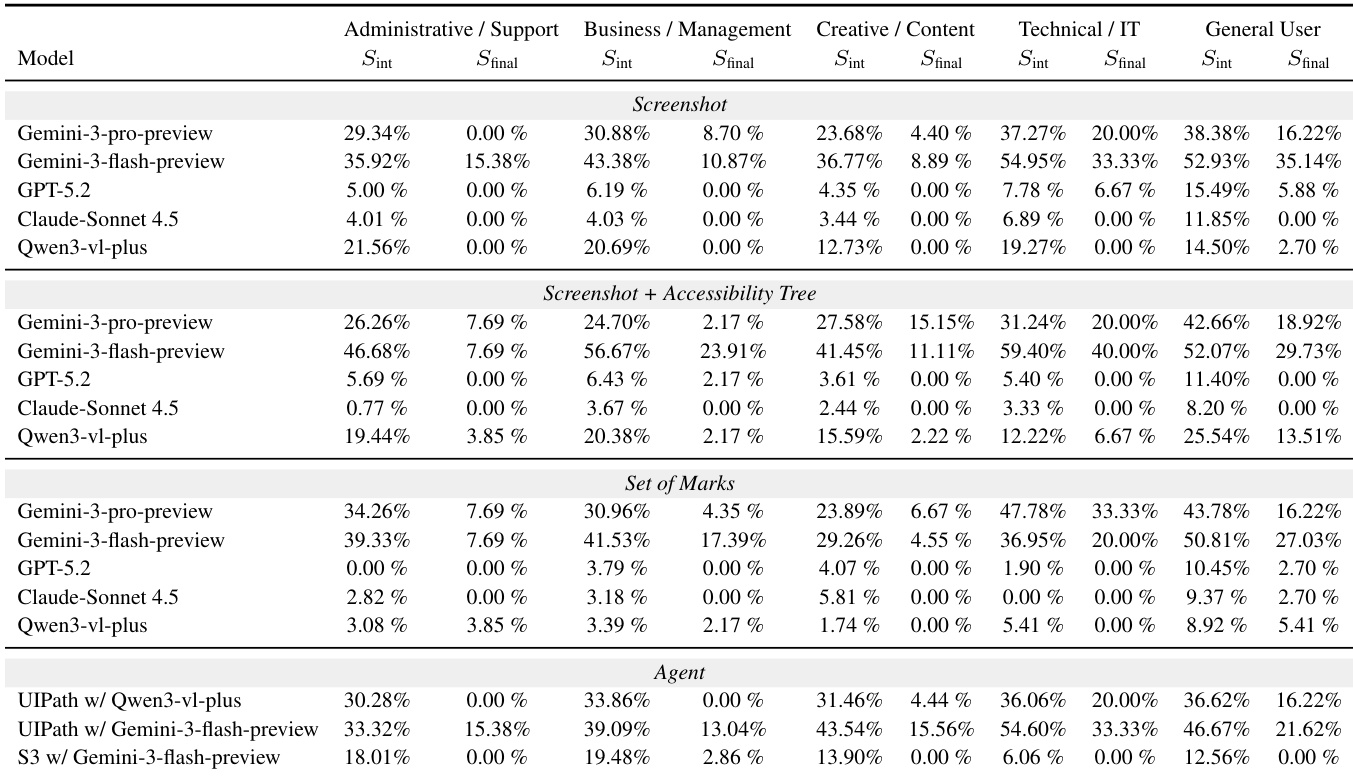
The authors compare WindowsWorld to existing benchmarks, highlighting that it is the only desktop-based benchmark with a high percentage of multi-application tasks and intermediate checks, distinguishing it from Android-focused benchmarks that lack these features. WindowsWorld introduces a structured evaluation framework with process-aware tasks and fine-grained intermediate assessments, enabling a more rigorous assessment of agent capabilities in cross-application environments. WindowsWorld is the only desktop benchmark with a high proportion of multi-application tasks and intermediate checks Existing benchmarks focus on Android and lack the process-aware, cross-application complexity of WindowsWorld WindowsWorld includes fine-grained intermediate assessments, enabling detailed analysis of agent progress and failure points
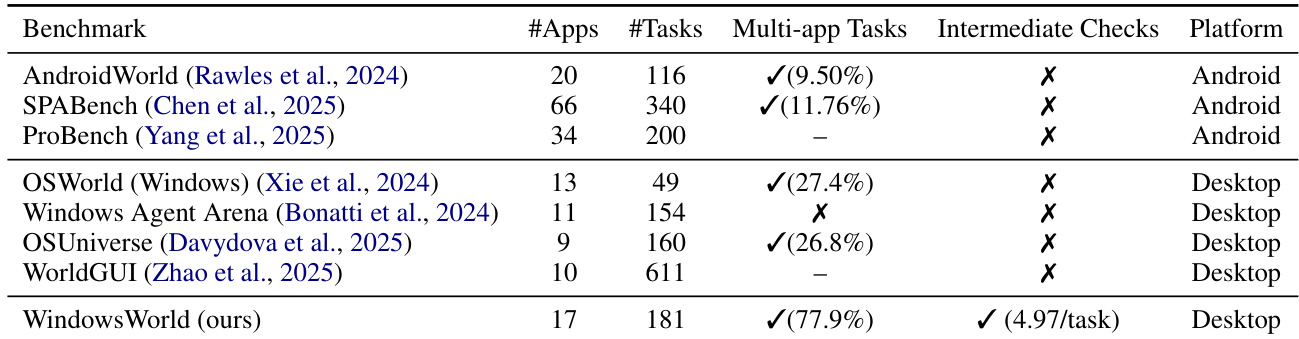
The authors analyze the impact of instruction language on model performance in a WindowsWorld benchmark, comparing Chinese and English inputs. Results show that English instructions consistently yield higher intermediate and final task completion scores across different task levels, indicating better comprehension and planning stability. The performance gap between languages is most pronounced in complex, multi-step tasks, suggesting a linguistic bias in current models. English instructions lead to higher task completion scores compared to Chinese instructions across all evaluated metrics. The performance gap between English and Chinese inputs widens with task complexity, particularly in final completion rates. English instructions support more stable multi-step execution, reducing the likelihood of failure in complex workflows.
The authors analyze the performance of various large models and agents on a WindowsWorld benchmark, focusing on efficiency, intermediate progress, and final task completion. Results show significant variation in latency and step efficiency across models and input modalities, with a notable gap between intermediate progress and final success rates, particularly in complex tasks. Performance varies significantly across models and input types, with latency differences observed even under similar conditions. There is a consistent gap between intermediate progress and final task completion, indicating that agents often fail to synthesize sub-goals into successful outcomes. The step gap between failed and successful trajectories increases with task complexity, suggesting that failures occur after extended, locally plausible execution rather than immediately.
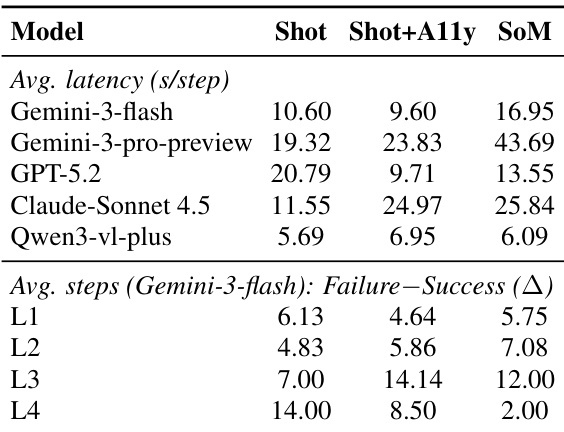
The authors analyze the performance of various agents on a cross-application benchmark, focusing on task difficulty levels and intermediate progress. Results show that as task complexity increases from L1 to L3, the number of intermediate checks required also increases, indicating greater difficulty in maintaining progress. The data highlights a consistent gap between intermediate progress and final task completion across all levels. Task difficulty increases with complexity, as shown by a higher number of intermediate checks required at higher levels. Intermediate progress metrics are more discriminative than final completion rates, especially in complex tasks. A persistent gap exists between intermediate progress and final success, suggesting failures occur late in the task execution process.
The authors evaluate large language models and specialized agents on the WindowsWorld benchmark, a process-aware desktop environment featuring multi-application tasks with fine-grained intermediate assessments. By testing across varying task complexities, observation modalities, professional personas, and instruction languages, the experiments validate how current agents navigate long-horizon workflows and synthesize sub-goals. Analysis reveals a persistent qualitative gap between intermediate progress and final task completion, as models frequently falter during late-stage coordination in complex scenarios. Furthermore, structured input modalities and English instructions consistently support more stable execution, underscoring significant limitations in current agents' ability to maintain cross-application planning and adapt to linguistic or role-specific demands.