Command Palette
Search for a command to run...
Collaboration de modèles de fondation scientifiques hétérogènes
Collaboration de modèles de fondation scientifiques hétérogènes
Zihao Li Jiaru Zou Feihao Fang Xuying Ning Mengting Ai Tianxin Wei Sirui Chen Xiyuan Yang Jingrui He
Résumé
Les systèmes de modèles de langage à grande échelle de type « agentic » ont démontré des capacités remarquables. Cependant, leur dépendance au langage comme interface universelle limite fondamentalement leur applicabilité à de nombreux problèmes du monde réel, en particulier dans les domaines scientifiques où des modèles fondamentaux spécifiques au domaine ont été développés pour traiter des tâches spécialisées qui dépassent le cadre du langage naturel. Dans cet ouvrage, nous présentons Eywa, un cadre agentic hétérogène conçu pour étendre les systèmes centrés sur le langage à une classe plus vaste de modèles fondamentaux scientifiques. L’idée clé d’Eywa consiste à enrichir les modèles fondamentaux spécifiques au domaine d’une interface de raisonnement basée sur les modèles de langage, permettant ainsi aux modèles de langage de guider l’inférence sur des modalités de données non linguistiques. Cette conception permet aux modèles prédictifs fondamentaux, généralement optimisés pour des données et des tâches spécialisées, de participer à des processus de raisonnement et de prise de décision de plus haut niveau au sein des systèmes agentic. Eywa peut servir de remplacement direct pour un pipeline mono-agent (EywaAgent) ou être intégré dans des systèmes multi-agents existants en remplaçant les agents traditionnels par des agents spécialisés (EywaMAS). Nous explorons également un cadre d’orchestration basé sur la planification, dans lequel un planificateur coordonne dynamiquement les agents traditionnels et les agents Eywa pour résoudre des tâches complexes sur des modalités de données hétérogènes (EywaOrchestra). Nous évaluons Eywa dans divers domaines scientifiques couvrant les sciences physiques, les sciences de la vie et les sciences sociales. Les résultats expérimentaux démontrent qu’Eywa améliore les performances sur les tâches impliquant des données structurées et spécifiques au domaine, tout en réduisant la dépendance au raisonnement basé sur le langage grâce à une collaboration efficace avec des modèles fondamentaux spécialisés.
One-sentence Summary
The authors introduce Eywa, a heterogeneous agentic framework that augments domain-specific scientific foundation models with a language-model-based reasoning interface to guide inference over non-linguistic data, supporting single-agent, multi-agent, and planning-based orchestration configurations that improve performance on structured scientific tasks while reducing reliance on natural language reasoning across physical, life, and social science domains.
Key Contributions
- This work introduces Eywa, a heterogeneous agentic framework that extends language-centric pipelines to scientific foundation models. By augmenting specialized models with a language-based reasoning interface, the architecture enables large language models to guide inference over non-linguistic data modalities while preserving native structured-data inductive biases.
- The framework supports flexible deployment through a drop-in single-agent pipeline (EywaAgent), a modular multi-agent integration module (EywaMAS), and a planning-based orchestration system (EywaOrchestra) that dynamically coordinates heterogeneous experts across incompatible data formats.
- Evaluations across physical, life, and social science benchmarks demonstrate that Eywa improves performance on tasks involving structured and domain-specific data while reducing reliance on language-only reasoning through coordinated inference with specialized foundation models.
Introduction
Agentic AI systems powered by large language models have transformed complex problem solving, yet their strict reliance on natural language creates a significant bottleneck for scientific applications that depend on specialized, non-linguistic data like time series, molecular structures, and crystal graphs. Prior approaches typically force structured information into textual formats or treat domain-specific foundation models as passive callable tools, which sacrifices structural fidelity and prevents direct, modality-native collaboration. To bridge this gap, the authors introduce Eywa, a heterogeneous agentic framework that connects generalist LLMs with specialized scientific models through a novel reasoning interface. The framework augments domain-specific foundation models with language-based coordination, enabling them to participate directly in planning and decision-making workflows. Deployed across single-agent, multi-agent, and dynamic orchestration configurations, Eywa consistently improves task utility while reducing token consumption and execution time across physical, life, and social science domains.
Dataset

-
Dataset Composition and Sources
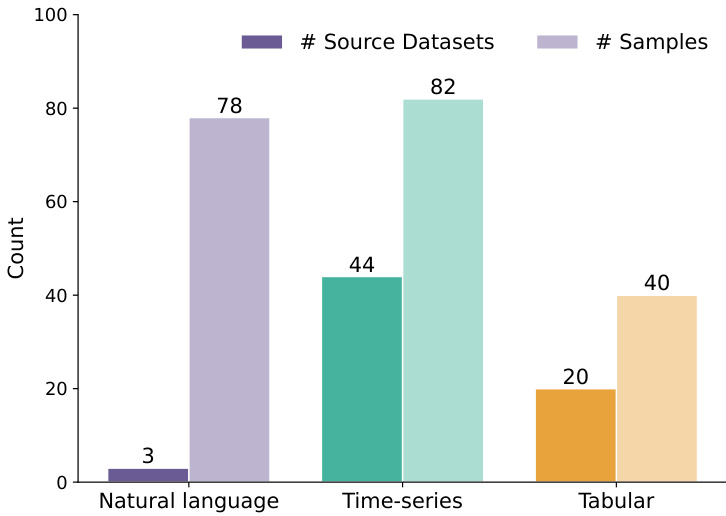
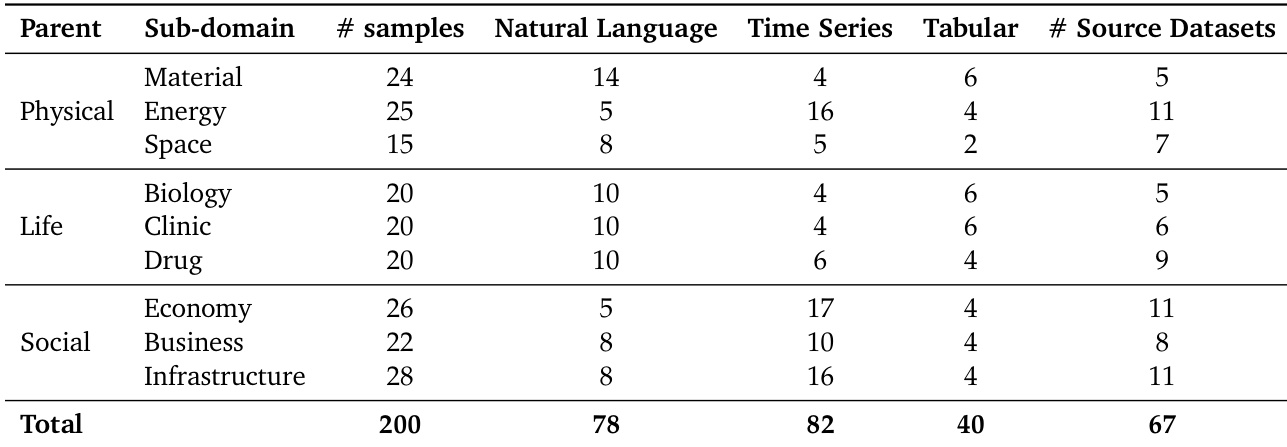
- The authors introduce EywaBench as a scalable benchmark designed to evaluate scientific agentic systems across three core modalities: natural language, time series, and tabular data.
- The benchmark aggregates tasks from four primary sources: DeepPrinciple, MMLU-Pro, fev-bench, and TabArena. These sources collectively draw from 67 distinct underlying scientific datasets spanning physical, life, and social sciences.
-
Subset Details and Sizing
- The released EywaBench-V1 split contains exactly 200 curated task instances sampled from much larger source pools.
- DeepPrinciple contributes scientific QA tasks (1,125 original questions), MMLU-Pro provides open-ended reasoning questions (6,978 original questions), fev-bench supplies time-series forecasting tasks (96 datasets with up to 30,000 covariate series each), and TabArena offers tabular classification and regression tasks (51 datasets with up to 150,000 rows each).
- The authors enforce a near-uniform distribution across three parent domains (32%, 30%, 38%), nine sub-domains (15 to 28 instances each), and three modalities (41%, 39%, 20%) to prevent domain collapse and ensure every sub-domain contains a mix of all modalities.
-
Processing and Schema Construction
- Each source dataset is converted into a unified six-column schema using custom parsing scripts and stored as a single dictionary-encoded Parquet file with Snappy compression.
- The authors apply timestamp anonymization and re-indexing to temporal features to prevent models from relying on memorized historical trends, and they normalize numerical signals to maintain consistent scaling across tasks.
- For tabular tasks, target columns are masked to simulate real-world prediction scenarios, while the underlying pipeline supports scalable resampling of temporal windows, covariate groups, or row subsets without altering the benchmark schema.
-
Usage and Evaluation Strategy
- The dataset is strictly used for evaluation rather than training, providing a controlled environment to test multi-agent orchestration, cross-modal reasoning, and specialist model integration.
- The authors sample 200 instances to maintain balanced modality coverage while keeping the evaluation reproducible and feasible for expert validation.
- Performance is measured using a unified utility score between zero and one, calculated via soft-match scoring for language tasks and normalized prediction errors for time-series and tabular tasks, enabling direct cross-modal comparison.
Method
The Eywa framework introduces a modular architecture designed to integrate specialized domain-specific foundation models (FMs) with general-purpose language models (LLMs) to enhance both reasoning and acting capabilities in agentic systems. At its core is the EywaAgent, a unified agent that combines language-based reasoning with domain-specific computation through a bidirectional communication interface termed the FM-LLM "Tsaheylu" bond. This bond enables a language model to correctly configure and invoke a foundation model for specialized computation while seamlessly reintegrating the output back into the reasoning process. The Tsaheylu interface is formalized as a pair of functions: a query compiler ϕk that translates the task state into a structured invocation for the foundation model, and a response adapter ψk that converts the foundation model's output into a language-compatible representation. This communication pipeline allows the agent to dynamically decide whether to perform a computation internally or delegate it to the foundation model, thereby adapting between generalized reasoning and specialized acting.
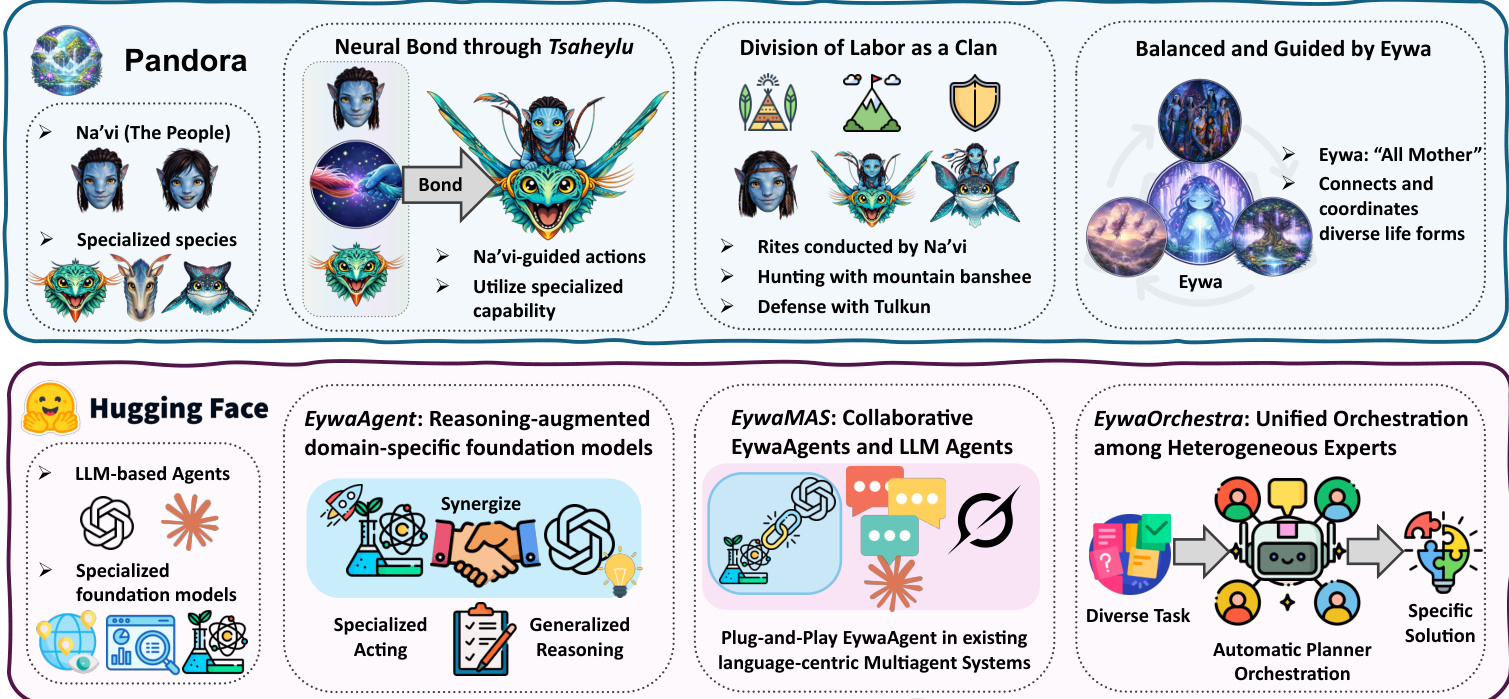
The framework extends this single-agent paradigm to multi-agent systems through EywaMAS, which generalizes existing multi-agent systems by allowing heterogeneous agents—comprising both standard LLM agents and EywaAgents—to interact within a unified framework. This enables the plug-and-play integration of domain-specific foundation models into existing multi-agent architectures without requiring changes to communication protocols or system designs. The communication and state update dynamics of EywaMAS follow the standard multi-agent system model, where agents update their states and produce messages based on received information, with interactions governed by a communication topology. This approach supports flexible composition across different language models, foundation models, and agent types.
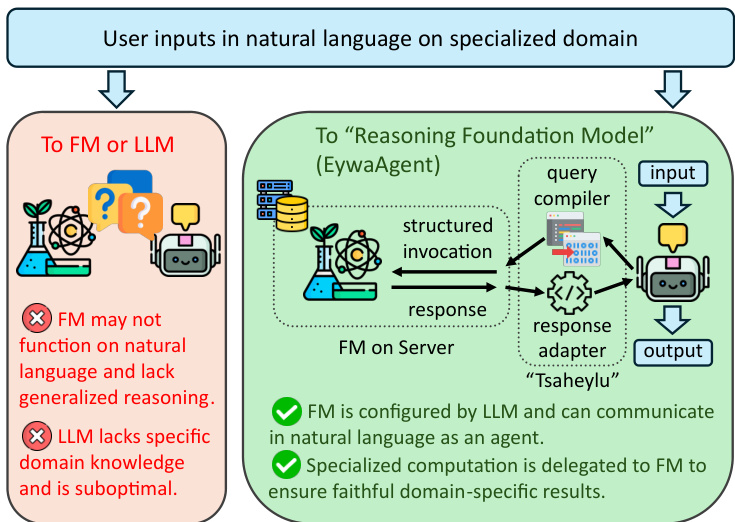
To address the challenge of diverse real-world tasks requiring different configurations of agents and topologies, the framework introduces EywaOrchestra, a dynamic orchestration system. EywaOrchestra functions as a conductor that, conditioned on the input task, dynamically instantiates a heterogeneous multi-agent system by selecting the appropriate language model, foundation model, and communication topology. This adaptive orchestration allows the system to move beyond static designs, leveraging both model adaptivity and structural adaptivity to select the optimal configuration for each task. The conductor, instantiated as a large language model, maps the input task to a system configuration from a finite pool of candidate configurations, which are then executed to solve the task. This framework ensures that the system can adaptively leverage the strengths of different components to achieve optimal performance across a wide range of tasks.
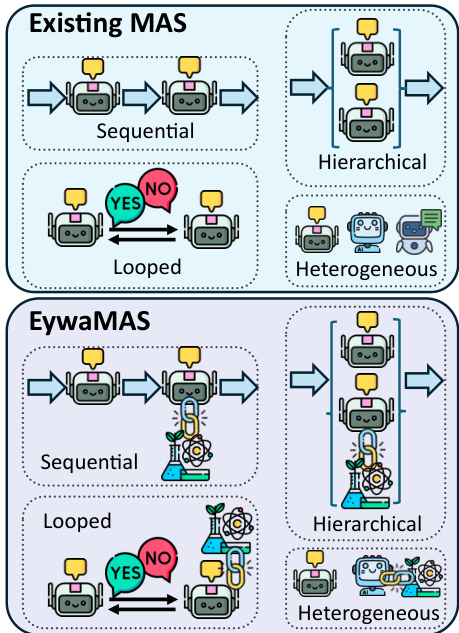
The theoretical analysis of the Eywa framework establishes its superiority over language-only agents and systems. Under the assumption that foundation models have a domain advantage—meaning they achieve better performance on domain-specific inputs than language-only models—the EywaAgent achieves a strictly lower optimal expected task loss. This improvement is due to the ability of the EywaAgent to bypass the information bottleneck of language serialization by directly accessing domain-specific inputs through the Tsaheylu interface. The analysis further shows that EywaMAS can propagate this advantage through communication graphs, enabling systems with at least one EywaAgent to solve tasks that are intractable for language-only systems, provided the information reaches the final output node. Finally, the dynamic orchestration of EywaOrchestra provides an additional strict improvement over any fixed configuration, as it can adapt to the optimal setup for each task, thereby dominating the performance of static multi-agent systems.
Experiment
Evaluated on EywaBench across multiple scientific domains, the study compares Eywa’s single-agent, multi-agent, and dynamically orchestrated configurations against LLM-only baselines to validate the necessity of integrating domain-specific foundation models into agentic workflows. Main performance trials and efficiency analyses validate that cross-modality collaboration consistently outperforms purely linguistic multi-agent systems by routing structured numerical tasks to specialized predictors rather than relying on redundant language model exchanges. Hyperparameter and backbone ablations further validate the framework’s architectural robustness, confirming that its gains stem from cross-modality design rather than specific model checkpoints or prompt templates. Finally, qualitative case studies validate that adaptive orchestration successfully matches task complexity to appropriate configurations, demonstrating that dynamic system selection yields superior quality and efficiency compared to fixed multi-agent topologies.
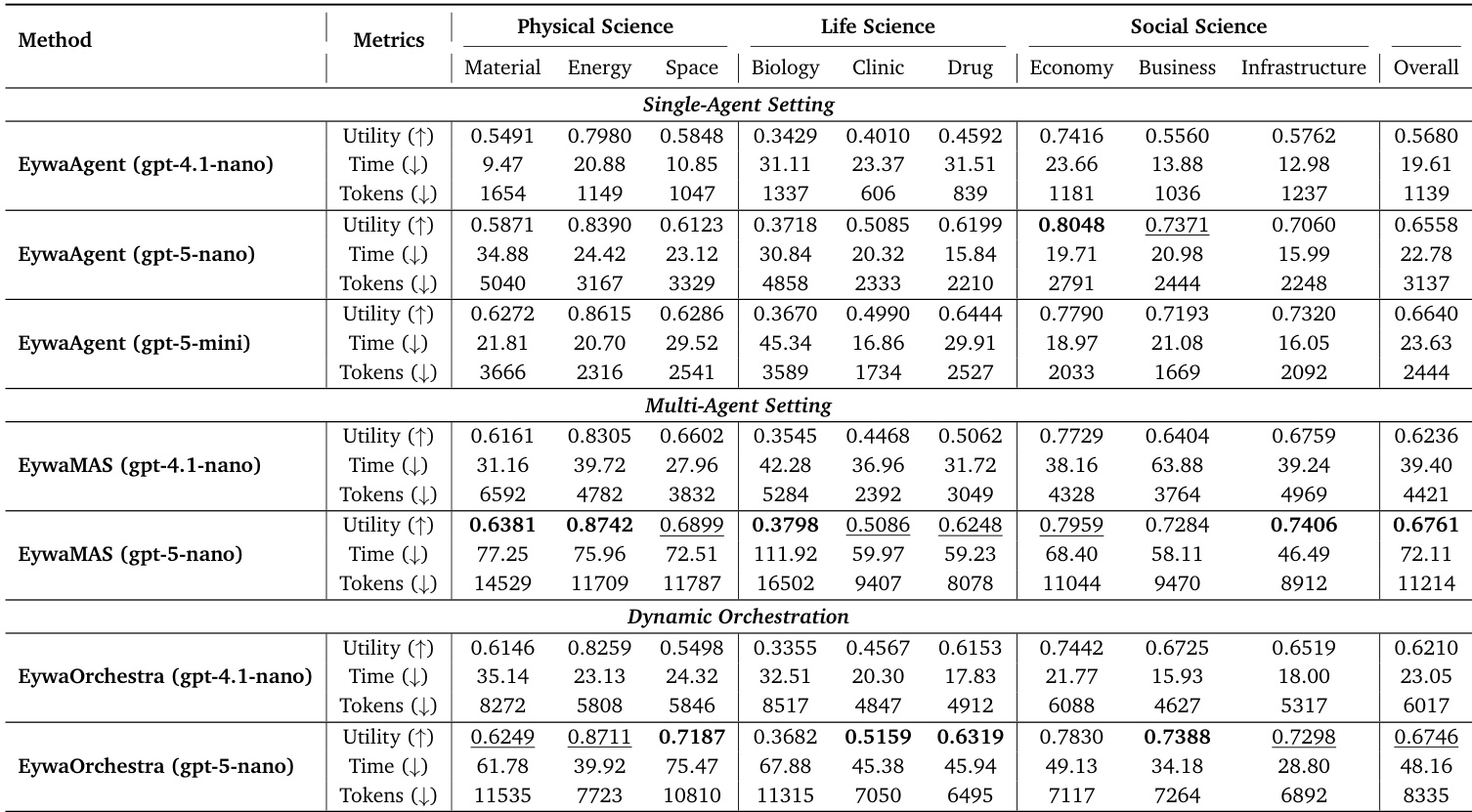
The authors evaluate the performance of EywaAgent, EywaMAS, and EywaOrchestra against various baseline methods on EywaBench, focusing on utility, inference time, and token consumption. The results show that Eywa methods achieve strong overall performance, with EywaAgent being particularly efficient in terms of token usage while maintaining competitive utility. EywaMAS achieves the highest utility among the proposed methods, while EywaOrchestra dynamically selects optimal configurations to balance utility and efficiency. The analysis highlights that integrating domain-specific foundation models improves performance and reduces redundancy in multi-agent systems. EywaAgent achieves higher utility and significantly reduces inference cost compared to single-agent baselines by leveraging domain-specific foundation models. EywaMAS outperforms homogeneous multi-agent baselines in utility while maintaining lower token consumption. EywaOrchestra dynamically selects configurations to achieve utility close to EywaMAS with reduced inference cost, demonstrating the effectiveness of adaptive orchestration.
The authors evaluate multiple agent configurations on EywaBench, comparing single-agent, multi-agent, and dynamically orchestrated systems across scientific domains. Results show that EywaAgent and its variants achieve high utility while reducing inference cost, with EywaOrchestra offering a balance of performance and efficiency through adaptive task routing. The proposed methods outperform LLM-only baselines in both utility and efficiency, particularly in domain-specific tasks where specialized foundation models are leveraged. EywaAgent improves utility and reduces inference cost compared to single-agent baselines by delegating domain-specific tasks to specialized foundation models. EywaMAS achieves higher utility than homogeneous multi-agent baselines, with better efficiency due to cross-modality coordination. EywaOrchestra dynamically selects optimal configurations, reaching utility close to expert-designed systems while significantly reducing token consumption and latency.
The authors evaluate their proposed Eywa systems against various baselines on EywaBench, demonstrating that integrating domain-specific foundation models with language models improves utility while reducing inference cost. EywaAgent achieves higher utility and lower token usage compared to single-agent baselines, while EywaMAS and EywaOrchestra further improve utility through multi-agent coordination and adaptive orchestration, respectively. The results show that cross-modality heterogeneity is more beneficial than LLM-only heterogeneity, and that dynamic orchestration can achieve performance close to expert-designed systems with lower cost. EywaAgent improves utility and reduces token usage compared to single-agent baselines by delegating domain-specific tasks to foundation models. EywaMAS achieves higher utility than homogeneous multi-agent baselines through cross-modality coordination, while EywaOrchestra matches its performance with lower inference cost. Dynamic orchestration in EywaOrchestra enables task-adaptive system selection, achieving strong utility with reduced computational cost compared to fixed multi-agent setups.
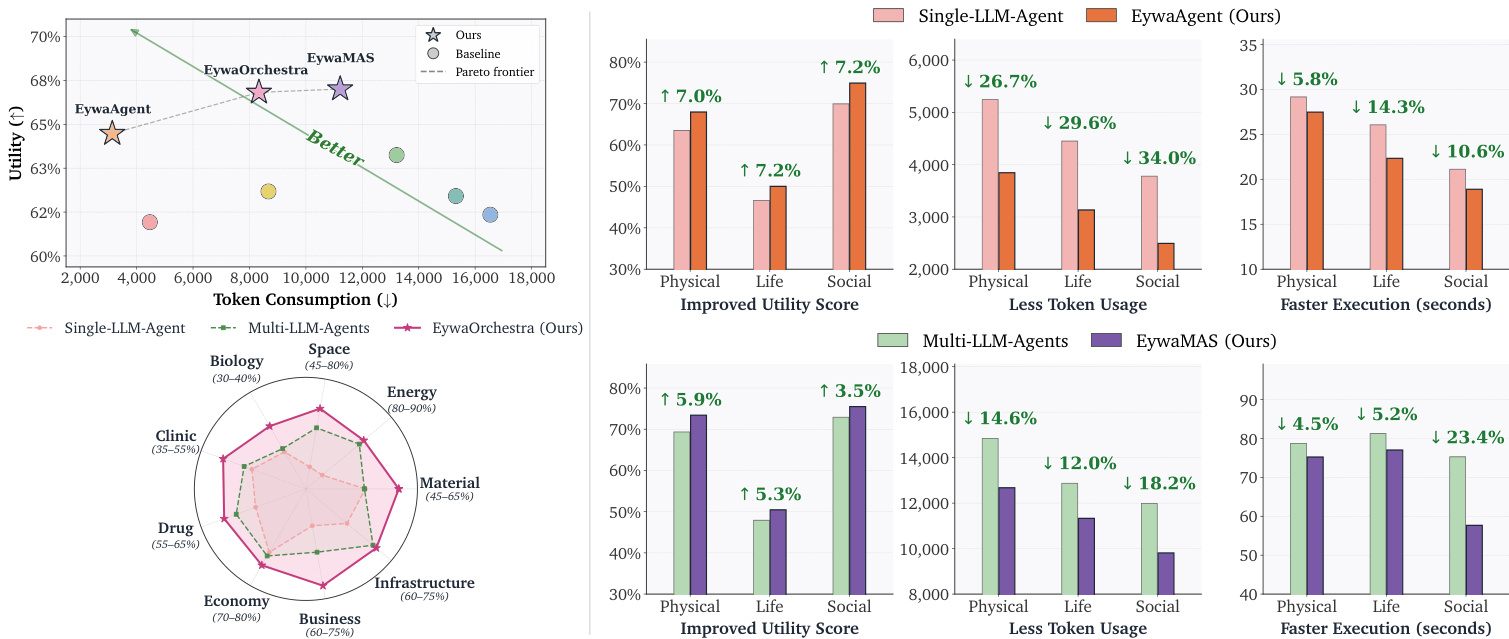
The authors evaluate multiple agent systems on EywaBench, comparing single-agent and multi-agent approaches that integrate language models with domain-specific foundation models. Results show that their proposed methods, EywaAgent, EywaMAS, and EywaOrchestra, achieve high utility with lower token consumption compared to baseline methods, particularly in scientific domains. The analysis reveals that cross-modality heterogeneity and dynamic orchestration improve performance while reducing computational cost. EywaAgent achieves high utility with significantly lower token consumption than LLM-only baselines, demonstrating efficient delegation to domain-specific models. EywaMAS and EywaOrchestra achieve higher utility than homogeneous and heterogeneous LLM-only multi-agent baselines, with EywaOrchestra approaching EywaMAS performance while reducing inference cost. All Eywa variants consistently occupy or approach the Pareto frontier across sub-domains, indicating superior trade-offs between utility and token consumption compared to other methods.
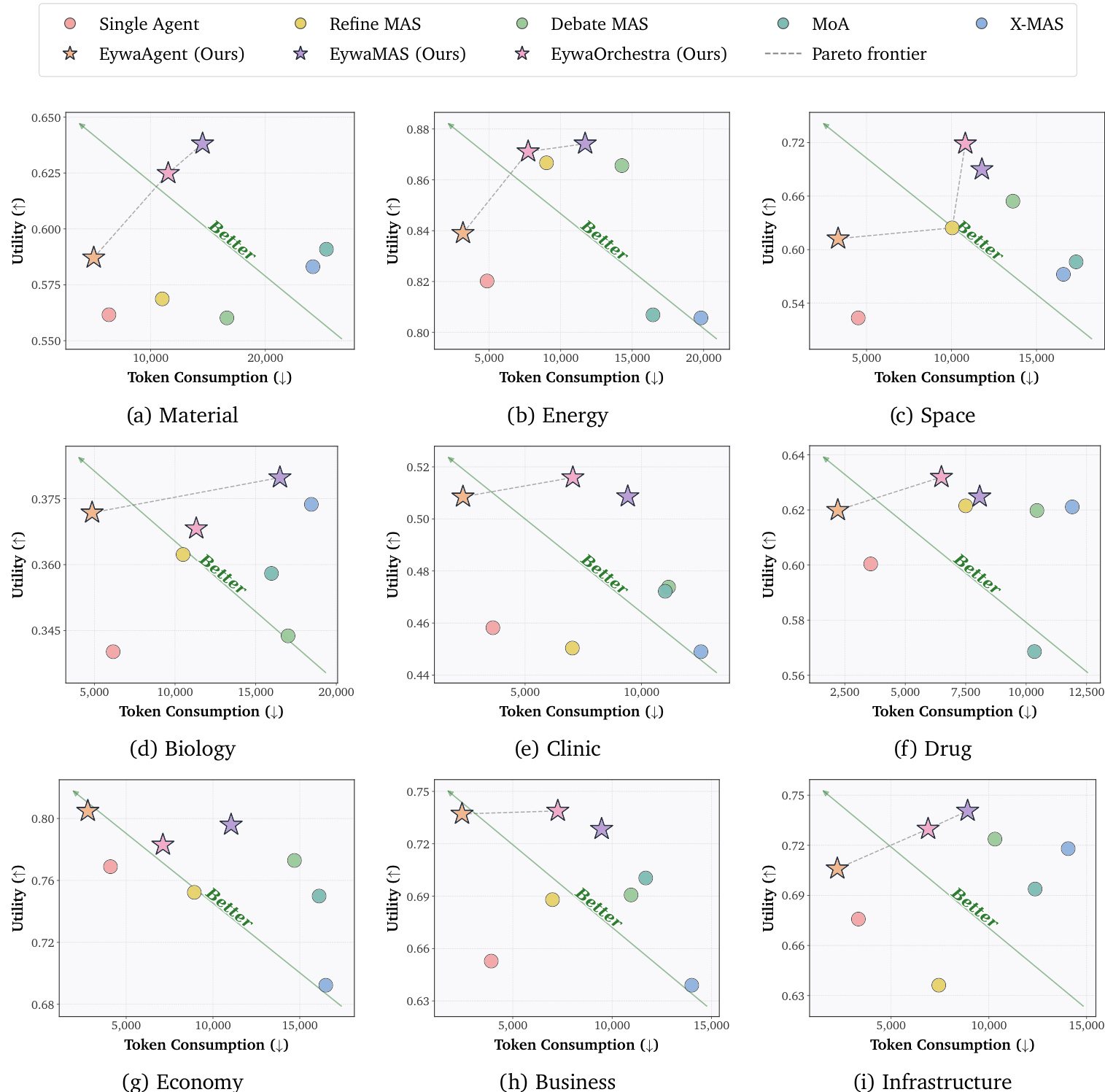
The experiment evaluates the performance of EywaAgent, EywaMAS, and EywaOrchestra across multiple scientific domains, comparing them against various LLM-based baselines. The results show that Eywa methods achieve strong utility while reducing inference cost and token consumption, with EywaAgent being the most efficient and EywaOrchestra providing adaptive orchestration that matches high utility with lower cost. The effectiveness of Eywa is consistent across different LLM backends and remains robust to variations in hyperparameters and prompt design. EywaAgent significantly improves utility while reducing inference cost and token usage compared to single-agent baselines. EywaOrchestra achieves utility close to EywaMAS with lower cost by dynamically selecting the optimal configuration for each task. Eywa methods maintain strong performance across different LLM backends and are robust to hyperparameter variations and prompt design choices.
Evaluated on EywaBench across multiple scientific domains, the experiments compare EywaAgent, EywaMAS, and EywaOrchestra against single-agent, multi-agent, and LLM-only baselines. This setup validates that EywaAgent effectively delegates tasks to domain-specific foundation models to enhance utility while reducing computational overhead. It further confirms that EywaMAS and EywaOrchestra leverage cross-modality coordination and adaptive orchestration to consistently outperform fixed configurations, achieving expert-level results at substantially lower costs. Collectively, the findings demonstrate that integrating specialized models with dynamic system selection yields robust, cost-effective trade-offs between performance and efficiency across diverse conditions.