Command Palette
Search for a command to run...
SketchVLM : Les modèles de langage visuel peuvent annoter des images pour expliquer les pensées et guider les utilisateurs
SketchVLM : Les modèles de langage visuel peuvent annoter des images pour expliquer les pensées et guider les utilisateurs
Brandon Collins Logan Bolton Hung Huy Nguyen Mohammad Reza Taesiri Trung Bui Anh Totti Nguyen
Résumé
Lorsqu’ils répondent à des questions sur des images, les humains ont naturellement pour réflexe de pointer, d’étiqueter et de dessiner afin d’expliciter leur raisonnement. À l’inverse, les modèles de vision et de langage (VLM) modernes, tels que Gemini-3-Pro et GPT-5, se limitent à des réponses textuelles, ce qui peut s’avérer difficile à vérifier pour les utilisateurs. Nous présentons SketchVLM, un framework indépendant du modèle et ne nécessitant pas d’apprentissage, qui permet aux VLM de générer des superpositions SVG non destructives et modifiables sur l’image d’entrée, offrant ainsi une explication visuelle de leurs réponses.Sur sept jeux d’évaluation couvrant le raisonnement visuel (navigation dans des labyrinthes, prédiction de trajectoires de chutes de balles et comptage d’objets) et le dessin (étiquetage de parties, connexion de points et tracé de formes autour d’objets), SketchVLM améliore la précision des tâches de raisonnement visuel jusqu’à +28,5 points de pourcentage, et la qualité des annotations jusqu’à un facteur de 1,48, par rapport aux références reposant sur l’édition d’images ou l’apprentissage supervisé de schémas (fine-tuned sketching). De plus, les annotations produites sont plus fidèles à la réponse explicite du modèle. Nous observons que la génération en un seul tour suffit déjà à obtenir une forte précision et une qualité d’annotation élevée, tandis que la génération multi-tours ouvre de nouvelles perspectives pour la collaboration homme-machine.
One-sentence Summary
SketchVLM is a training-free, model-agnostic framework that enables vision-language models to produce non-destructive, editable SVG overlays for visual explanation, improving visual reasoning accuracy by up to 28.5 percentage points and annotation quality by up to 1.48× across seven benchmarks relative to image-editing and fine-tuned sketching baselines, while also producing annotations more faithful to the model's stated answer.
Key Contributions
- This work presents SketchVLM, a training-free, model-agnostic framework that enables vision-language models to produce non-destructive, editable SVG overlays on input images to visually explain answers. The method supports free-form drawing and annotation without requiring fine-tuning or destructive image editing.
- Evaluation spans seven benchmarks covering visual reasoning tasks like maze navigation and ball-drop trajectory prediction alongside drawing tasks such as part labeling and shape drawing. These tests assess capabilities including point localization, object counting, and connecting dots in order.
- Results indicate that SketchVLM improves visual reasoning task accuracy by up to +28.5 percentage points and annotation quality by 1.48× relative to image-editing and fine-tuned sketching baselines. The framework produces annotations that are more faithful to the model's stated answer.
Introduction
As vision-language models integrate into consumer workflows, users struggle to verify text-only responses against complex visual queries. Prior approaches like image-editing models risk altering source images in unintended ways, while specialized fine-tuned models often fail to generalize beyond their training domains. The authors present SketchVLM, a training-free framework that enables standard VLMs to generate non-destructive SVG overlays directly on input images. This approach grounds reasoning in visual annotations, significantly improving task accuracy and allowing users to inspect the model's thought process without modifying the original content.
Dataset
The authors utilize a suite of seven tasks to evaluate spatial reasoning and sketching capabilities, drawing from both public benchmarks and synthetic generation.
- Connect-the-Dots: Contains 100 images across three subsets, including 21 random patterns generated via Python, 30 SVG outlines processed with the Douglas-Peucker algorithm, and 49 online worksheets requiring manual annotation.
- Counting Objects: Combines 746 samples from CountBench and TallyQA with 443 filtered images from Pixmo-Count, covering object counts from 0 to 10.
- Drawing Shapes: Uses 1,000 images selected from the 5,000-image COCO validation set to balance object counts and sizes across classes.
- Part Labeling: Includes 985 images from PACO and Pascal-Part covering 52 classes, filtered for single objects occupying at least 10% of the area with four or more part labels.
- Maze Navigation: Consists of 200 generated 3x3 grid mazes with path lengths from 3 to 8 steps, where invalid paths are created by perturbing ground truth directions.
- Visual Physics (VPCT): Features 100 hand-crafted images requiring models to predict which container a dropped ball will land in.
- Ball Drop: Provides 198 synthetic images generated using PHYRE to establish ground truth ball trajectories with randomized line configurations.
The data supports both single-turn and multi-turn generation workflows. In multi-turn settings, the model reuses system prompts and previous annotations provided in rendered image and text forms. All stroke annotations are output in XML format containing point coordinates and timing values to enable precise evaluation of drawing tasks.
Method
The authors propose SketchVLM, a framework designed to enhance Visual Language Models (VLMs) with sketching capabilities to improve spatial reasoning and precision. The architecture integrates visual prompting, a specialized system prompt for structured output, and a rendering pipeline. To facilitate precise drawing, the authors append a coordinate grid to the left and bottom of the input image, scaled to the image resolution. This grid provides a reference system where locations are identified by coordinates.
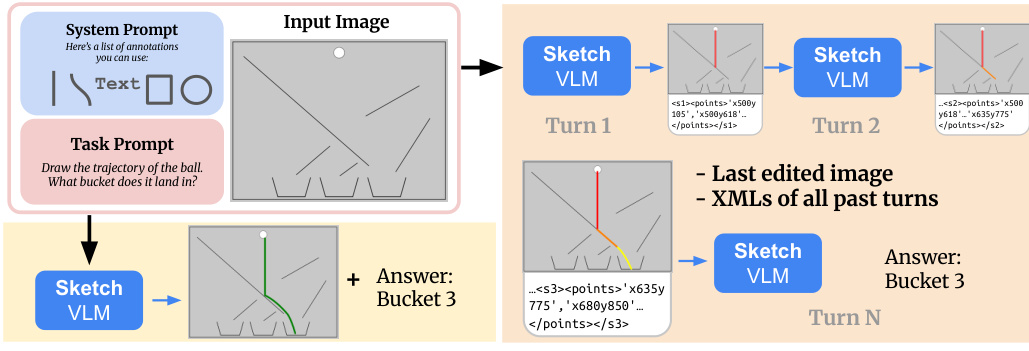
As shown in the framework diagram, the system supports multi-turn interaction. The model receives the task prompt, the last edited image, and the XMLs of all past turns. In each turn, the Sketch VLM generates new strokes and updates the image state, allowing for iterative refinement before providing a final answer.
To enable the generation of these annotations, the authors introduce a system prompt that instructs the model to produce stroke sequences in a specific format. While XML is used for experiments, the interactive demo utilizes JSON for better human readability. The prompt defines drawing primitives including rectangles, arrows, text labels, straight lines, and Bézier curves. The model specifies starting points, ending points, and intermediate points with corresponding normalized timestamps t∈[0,1].
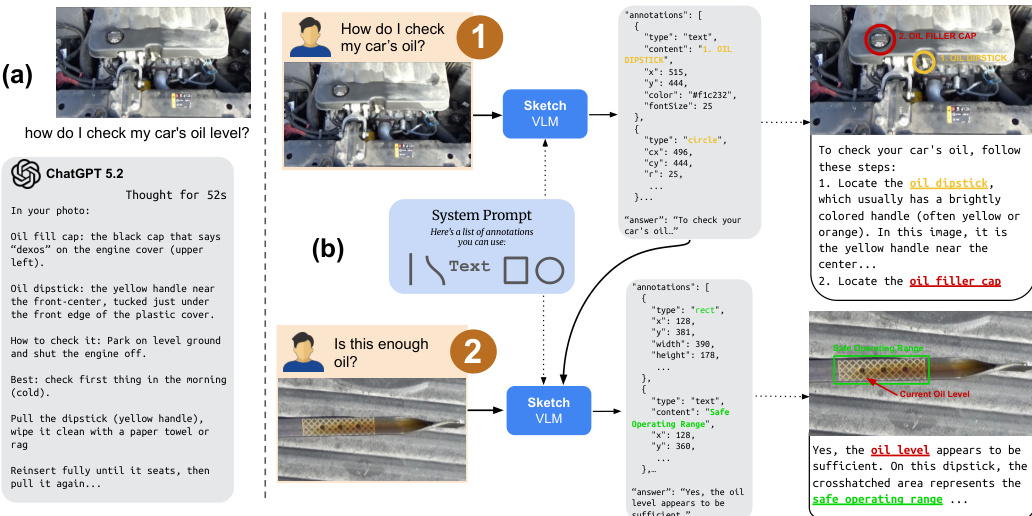
Refer to the example workflow where the model outputs annotations in a structured format. The raw output is then parsed and converted into Standard Vector Graphics (SVG) to render an overlay on the source image. If a stroke consists of exactly two points, a straight line is rendered. For strokes with more points, described by m ordered samples Si={(xj,yj)}j=1m and normalized timestamps Ti={tj}j=1m, the system fits a smooth Bézier curve using a least squares solution for the control points.

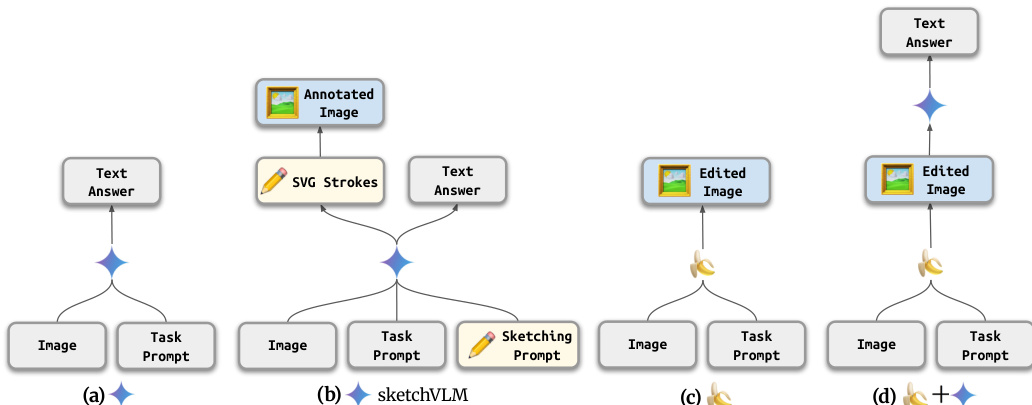
This approach distinguishes SketchVLM from standard VLMs that only output text or editing models that modify pixels directly. As illustrated in the architecture comparison, SketchVLM outputs both SVG strokes and a text answer, allowing for precise spatial reasoning without altering the original image pixels.
Experiment
The study evaluates SketchVLMs against image editing and fine-tuned sketching baselines using single-turn and multi-turn configurations to test visual reasoning and annotation fidelity. Experiments demonstrate that SketchVLMs consistently outperform competitors in accuracy and annotation-text alignment, particularly for tasks involving spatial grounding and physics understanding. Additionally, the framework generates high-quality, coherent visual traces that enable direct user verification, with single-turn generation achieving comparable results to multi-turn interactions while requiring significantly fewer steps.
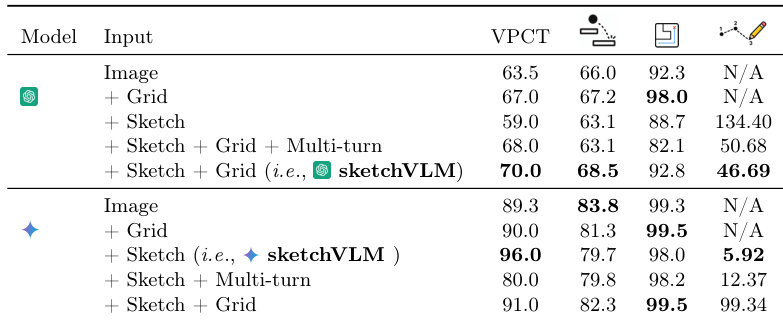
The authors evaluate SketchVLMs across different input configurations and baselines to determine optimal prompting strategies. Results indicate that while one model variant benefits from coordinate grids for spatial precision, another performs better without them to avoid significant localization errors. Additionally, SketchVLMs demonstrate superior annotation quality and task accuracy compared to fine-tuned sketching models, with single-turn generation proving as effective as multi-turn approaches. One model variant achieves peak performance with sketching and grid inputs, whereas the other degrades significantly when a grid is added. SketchVLMs outperform fine-tuned sketching baselines on visual reasoning tasks, particularly in physics understanding scenarios where baselines fail to generalize. Single-turn generation yields comparable accuracy to multi-turn methods but requires substantially fewer interaction steps.
The authors measure inter-annotator agreement to validate the reliability of human judgments used for evaluating annotation quality. The data shows that human annotators are highly consistent on most datasets, particularly for valid maze paths and ball-drop tasks. However, agreement drops significantly for the maze-invalid dataset, indicating greater difficulty in reaching a consensus on invalid path evaluations. Human annotators demonstrate strong consistency on the maze-valid and ball-path datasets. Agreement levels are notably lower for the maze-invalid dataset compared to other tasks. Both quadratic Kappa and Pearson correlation metrics confirm high reliability across most evaluation scenarios.

The provided the the table compares SketchVLM against various baseline models regarding training requirements, interaction modes, and annotation styles. SketchVLM is distinguished as a training-free framework that supports multi-turn interaction, free-form drawing, and vector-based annotations without modifying the original image. In contrast, many alternative models require fine-tuning or rely on image editing techniques that alter the input. SketchVLM is the only approach listed that combines training-free operation with free-form drawing and vector overlay annotations. Several baseline models require fine-tuning and rely on image editing rather than non-destructive vector annotations. Unlike some competitors such as SketchAgent, SketchVLM preserves the input image while supporting multi-turn interaction for iterative tasks.

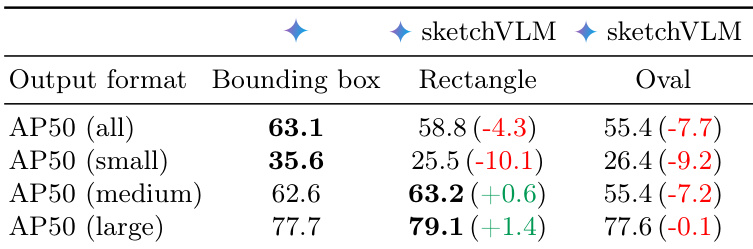
The authors compare object localization performance between standard bounding boxes and sketch-based annotations using rectangles and ovals. While sketch-based rectangles demonstrate improved accuracy for medium and large objects, they lead to a significant degradation in performance for small objects, resulting in a lower overall detection score. Sketch-based rectangles outperform the baseline bounding box method on medium and large objects. Small object detection accuracy suffers a notable decline when using sketch-based annotations compared to standard bounding boxes. Both rectangle and oval sketch formats yield lower overall Average Precision scores than the original bounding box approach.
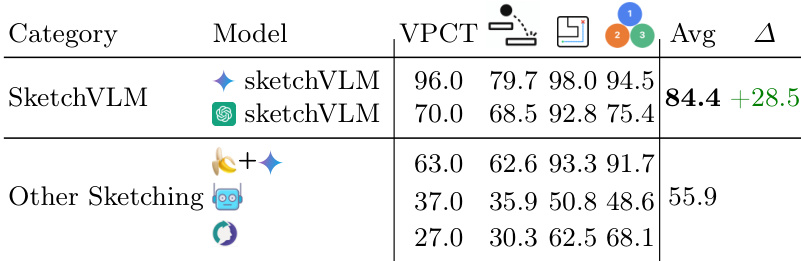
The authors compare SketchVLM models against various baseline sketching approaches across multiple visual reasoning tasks. Results indicate that SketchVLM achieves significantly higher average accuracy than the other sketching methods, with a notable performance gap favoring the proposed framework. While baseline models often struggle with tasks like physics prediction and object counting, SketchVLM maintains robust performance across all categories. SketchVLM outperforms baseline sketching models by a substantial margin in average accuracy. Fine-tuned sketching baselines perform near random chance on complex visual reasoning tasks. The proposed framework demonstrates consistent high accuracy across physics, navigation, and counting benchmarks.
The experiments evaluate SketchVLMs across input configurations and baselines to validate optimal prompting strategies and the reliability of human judgments. Results indicate that SketchVLMs achieve superior visual reasoning accuracy and annotation quality compared to fine-tuned sketching models, particularly in physics understanding scenarios where baselines fail to generalize. While sketch-based annotations improve localization for medium and large objects, they degrade performance on small objects compared to standard bounding boxes, and single-turn generation proves as effective as multi-turn approaches with fewer interaction steps. Furthermore, the framework distinguishes itself as a training-free solution that supports non-destructive vector annotations without modifying the original image.