Command Palette
Search for a command to run...
FlowAnchor : Stabilisation du signal d'édition pour une édition vidéo sans inversion
FlowAnchor : Stabilisation du signal d'édition pour une édition vidéo sans inversion
Ze Chen Lan Chen Yuanhang Li Qi Mao
Résumé
Nous proposons FlowAnchor, un framework sans entraînement (training-free) conçu pour une édition vidéo basée sur le flux (flow-based), stable, efficace et sans inversion (inversion-free). Les méthodes d'édition sans inversion ont récemment démontré une efficacité et une préservation de la structure impressionnantes sur les images, en dirigeant directement la trajectoire d'échantillonnage grâce à un signal d'édition. Cependant, l'extension de ce paradigme à la vidéo demeure complexe, échouant souvent dans les scènes multi-objets ou lorsque le nombre de trames augmente. Nous identifions la cause profonde de ce problème comme étant l'instabilité du signal d'édition dans les espaces latents vidéo de haute dimension, laquelle résulte d'une localisation spatiale imprécise et d'une atténuation de l'amplitude induite par la longueur de la séquence.Pour surmonter ce défi, FlowAnchor ancre explicitement à la fois le lieu de l'édition et l'intensité de celle-ci. Le framework introduit le Raffinement de l'Attention sensible à l'Espace (Spatial-aware Attention Refinement), qui impose un alignement cohérent entre le guidage textuel et les régions spatiales, ainsi que la Modulation Adaptative de l'Amplitude (Adaptive Magnitude Modulation), qui préserve de manière adaptative une force d'édition suffisante. Ensemble, ces mécanismes stabilisent le signal d'édition et guident l'évolution basée sur le flux vers la distribution cible souhaitée.Des expériences approfondies démontrent que FlowAnchor permet une édition vidéo plus fidèle, temporellement cohérente et informatiquement efficace, même dans des scénarios complexes impliquant plusieurs objets ou des mouvements rapides. La page du projet est disponible à l'adresse suivante : https://cuc-mipg.github.io/FlowAnchor.github.io/.
One-sentence Summary
FlowAnchor is a training-free framework for stable and efficient inversion-free video editing that utilizes Spatial-aware Attention Refinement and Adaptive Magnitude Modulation to overcome signal instability in high-dimensional latent spaces, ensuring temporal coherence and precise spatial localization in complex multi-object and fast-motion scenarios.
Key Contributions
- The paper introduces FlowAnchor, a training-free framework designed to stabilize the editing signal in inversion-free, flow-based video editing by anchoring both spatial localization and editing strength.
- This work presents Spatial-aware Attention Refinement (SAR), which modulates cross-attention maps at text token and spatio-temporal levels to ensure consistent semantic alignment between textual guidance and specific spatial regions across frames.
- The method incorporates Adaptive Magnitude Modulation (AMM) to prevent the editing signal from vanishing in high-dimensional video latent spaces, using normalized maps to amplify semantic contrast and maintain sufficient editing strength.
Introduction
Inversion-free video editing is a critical area of research aimed at achieving fast, structure-preserving video modifications without the high computational costs of traditional inversion methods. While these techniques work effectively for images, extending them to video often results in poor performance due to the instability of the editing signal in high-dimensional latent spaces. Specifically, prior work suffers from imprecise spatial localization, which causes semantic leakage in multi-object scenes, and magnitude attenuation, where the editing strength weakens as the video length increases.
The authors leverage a training-free framework called FlowAnchor to stabilize these signals by explicitly anchoring both the location and intensity of the edits. They introduce Spatial-aware Attention Refinement to ensure precise alignment between textual guidance and specific spatial regions, alongside Adaptive Magnitude Modulation to dynamically rescale the editing signal for consistent strength. Together, these mechanisms enable more faithful, temporally coherent, and efficient video editing across complex scenarios involving fast motion and multiple objects.
Dataset
The authors introduce Anchor-Bench, a specialized benchmark designed to evaluate fine-grained, localized video editing in complex, multi-object scenarios. The dataset details are as follows:
- Dataset Composition and Sources: The benchmark consists of 74 text-video editing pairs collected from the internet. These videos feature diverse real-world environments characterized by cluttered backgrounds, fast motion, and multiple objects.
- Subsets and Categories: The data is categorized into three localized editing types: color editing, material editing, and object replacement (covering both rigid and non-rigid objects).
- Prompt Construction and Metadata: For every source video, the authors provide one source prompt and multiple target prompts. They utilize GPT-5 to generate initial candidate prompts, which are then manually refined for semantic accuracy. To resolve ambiguity in scenes with multiple similar objects, the authors incorporate discriminative cues such as color, relative position, or surrounding context into the prompts.
- Processing and Masking: To facilitate localized evaluation, the authors provide an edit mask sequence for each target prompt. These masks are created by manually annotating the target region on the first frame and propagating the selection across the remaining frames using optical flow.
- Technical Specifications: The videos in the benchmark reach up to 81 frames in length at a resolution of 480p.
Method
The authors leverage the Rectified Flow framework to enable inversion-free text-to-video editing, building upon the FlowEdit method. The core approach involves constructing an editing trajectory Ztedit that evolves from the source image Xsrc towards a target distribution guided by a new prompt P∗. This is achieved by iteratively estimating a velocity difference field ΔVti, which serves as the editing signal. At each timestep ti, a pseudo-source state Ztisrc is generated via linear interpolation between the source image and noise, while a target state Ztitar is defined as Ztiedit+Ztisrc−Xsrc. The velocity fields for both states are then computed using a text-conditioned model, V(Ztisrc,ti,P) and V(Ztitar,ti,P∗), and their difference yields the editing signal ΔVti. This signal guides the evolution of the editing trajectory, Zti−1edit=Ztiedit+(ti−1−ti)ΔVti. 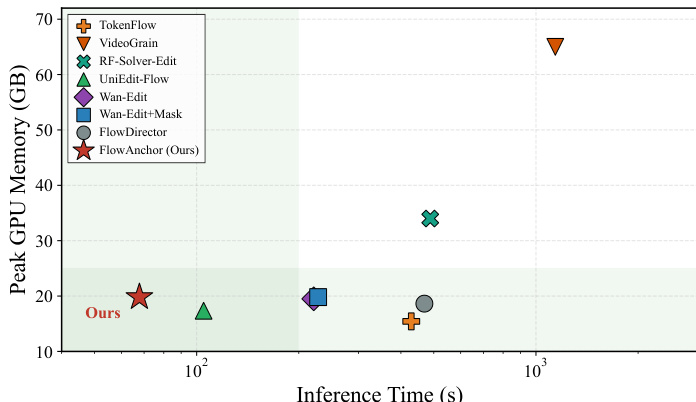
The primary challenge addressed is the imprecise localization and weakened magnitude of the editing signal in video editing. To resolve the localization issue, the authors propose Spatial-aware Attention Refinement (SAR), a two-step refinement of the cross-attention (CA) maps that govern the alignment between text and visual tokens. This process is applied to all CA layers during the early denoising stage. The first step, text-token modulation, strengthens the attention to the target text tokens Jtar and suppresses non-target tokens within the intended editing region M. This is achieved by pulling the attention weights of target tokens toward the maximum response and pushing non-target tokens toward the minimum response for each spatio-temporal video token inside the mask, using a modulation strength β1. The second step, spatio-temporal modulation, enforces global temporal coherence by regulating the attention weights of the target tokens across the entire video sequence. It amplifies the maximum attention response and suppresses the minimum response for each target token, thereby reducing flickering across frames. This step uses a modulation strength β2. The refined attention maps are then used to compute a more accurate target velocity field Vtitar for the editing signal.
To address the second failure mode—the attenuation of the editing signal magnitude in longer videos—the authors introduce Adaptive Magnitude Modulation (AMM). This mechanism adaptively reinforces the signal based on its intrinsic contrast. At each step, a contrast map Cti is derived by applying max-min normalization to the editing signal ΔVti, creating a soft importance mask that highlights regions with strong semantic variation. The contrast map is then combined with a frame-adaptive amplification factor γF=γ⋅log(F)/log(F0), where F is the actual video length and F0 is the model's default maximum length. This factor ensures that longer videos receive proportionally stronger compensation for the length-induced signal weakening. The final modulated editing signal ΔVtiAMM is obtained by element-wise multiplication: (1+γF⋅Cti)⊙ΔVti. This selectively amplifies high-contrast regions while leaving background noise largely unchanged. The refined editing signal drives the trajectory evolution.
The overall framework, FlowAnchor, integrates these components into a unified pipeline. As shown in the framework diagram, the source and target video tokens are fed into a DiT block with self-attention layers. The editing process begins by sampling a pseudo-source state and defining a target state. The velocity fields are computed, and their difference forms the initial editing signal. This signal is then processed by SAR to enhance spatial localization and by AMM to adaptively increase its magnitude. The final modulated signal is added to the current state to produce the next state in the editing trajectory. The process iterates backward in time until the final edited video is obtained. The framework's effectiveness is demonstrated through qualitative comparisons, which show that FlowAnchor produces more accurate and temporally consistent edits compared to baselines.
Experiment
The proposed method is evaluated on the FiVE-Bench and the newly introduced Anchor-Bench to validate its performance in localized video editing tasks such as object replacement, color modification, and material changes. Ablation studies and hyperparameter analyses demonstrate that the SAR and AMM modules are essential for achieving precise semantic localization and sufficient editing strength without compromising structural fidelity. Results show that the framework outperforms state-of-the-art baselines in text alignment, temporal consistency, and efficiency, while remaining highly robust to varying levels of mask granularity.
The authors compare their method with several state-of-the-art baselines in terms of inference time and peak GPU memory usage. Results show that their method achieves the lowest inference time among all compared methods while maintaining competitive memory consumption, indicating a favorable trade-off between efficiency and performance. the method achieves the lowest inference time compared to all baselines. the method uses competitive peak GPU memory, demonstrating efficient resource utilization. The method provides a favorable trade-off between speed and memory consumption.
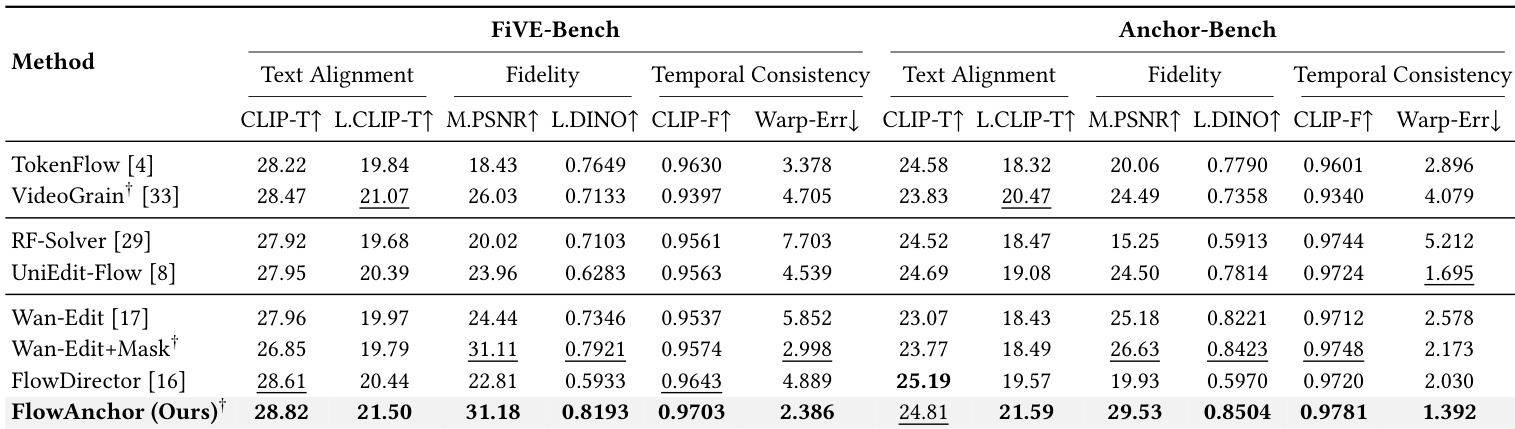
The authors compare their method, FlowAnchor, against several state-of-the-art baselines on two benchmarks, FiVE-Bench and Anchor-Bench, evaluating performance across text alignment, fidelity, and temporal consistency. Results show that FlowAnchor achieves the highest scores in most metrics, particularly in localized text alignment and temporal coherence, while also demonstrating superior efficiency. The method maintains strong performance across different mask granularities, indicating robustness to imprecise user inputs. FlowAnchor achieves the highest scores in localized text alignment and temporal consistency across both benchmarks compared to all baselines. FlowAnchor demonstrates superior efficiency with the lowest inference time while maintaining competitive performance in editing quality. The method remains effective across various mask granularities, showing consistent results from tight masks to coarse bounding boxes, indicating robustness to imprecise user inputs.
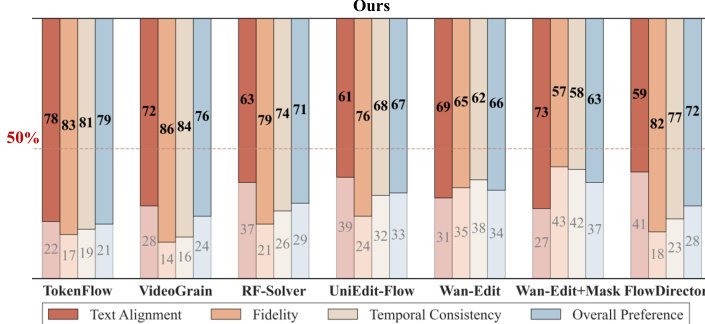
The authors compare their method against several baselines across multiple metrics, including text alignment, fidelity, temporal consistency, and overall preference. Results show that their approach consistently outperforms the baselines in text alignment and overall preference, while maintaining strong performance in fidelity and temporal consistency. The method achieves the highest scores in most categories, particularly in text alignment and user preference, and demonstrates superior efficiency. The method achieves the highest scores in text alignment and overall preference compared to all baselines. The method maintains strong performance in fidelity and temporal consistency across all evaluated metrics. The method demonstrates superior efficiency, achieving the lowest inference time among all compared methods.
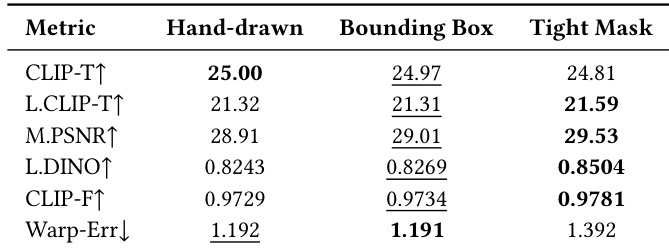
The authors evaluate the robustness of their method to different mask granularities, including hand-drawn masks, bounding boxes, and tight masks, on a benchmark. Results show that the method maintains strong performance across all mask types, with tight masks yielding the best overall scores, particularly in terms of temporal consistency and structure preservation. The method demonstrates consistent editing quality regardless of mask precision, indicating a high tolerance for imprecise user inputs. The method achieves consistent performance across hand-drawn, bounding box, and tight masks, showing robustness to mask granularity. Tight masks result in the highest scores for most metrics, especially temporal consistency and structure preservation. The method maintains strong text alignment and fidelity even with coarse or imprecise masks, indicating practical usability for interactive editing.
The authors conduct an ablation study to analyze the impact of different components and hyperparameters on the performance of their method. The results show that the proposed SAR and AMM modules significantly improve editing quality, with specific configurations achieving the best balance between localization, fidelity, and temporal consistency. The method demonstrates robust performance across various settings, maintaining high effectiveness even when mask precision varies. The SAR and AMM modules are crucial for achieving precise and strong editing signals, with specific hyperparameter settings leading to optimal performance. The method maintains high performance across different mask granularities, indicating robustness to imprecise user inputs. The proposed approach achieves a favorable trade-off between editing quality and computational efficiency, outperforming baselines in both metrics.
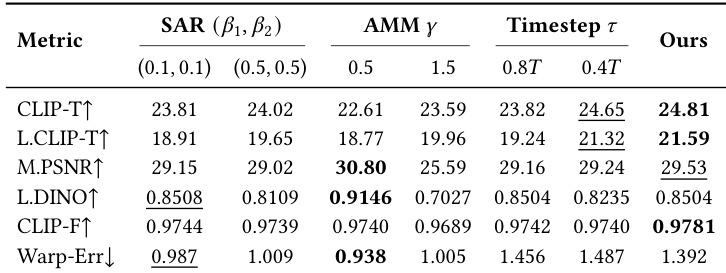
The authors evaluate FlowAnchor against state-of-the-art baselines using multiple benchmarks to assess efficiency, editing quality, and robustness to varying mask granularities. The results demonstrate that the method provides a superior balance of speed and memory usage while achieving high scores in text alignment, temporal consistency, and user preference. Furthermore, ablation studies confirm that the proposed SAR and AMM modules are essential for high-quality editing, and the model remains robust even when provided with imprecise user inputs.