Command Palette
Search for a command to run...
Percevoir le rapide et le lent : apprendre le flux temporel dans les vidéos
Percevoir le rapide et le lent : apprendre le flux temporel dans les vidéos
Yen-Siang Wu Rundong Luo Jingsen Zhu Tao Tu Ali Farhadi Matthew Wallingford Yu-Chiang Frank Wang Steve Marschner Wei-Chiu Ma
Résumé
Comment pouvons-nous déterminer si une vidéo a été accélérée ou ralentie ? Comment pouvons-nous générer des vidéos à différentes vitesses ? Bien que la vidéo soit au cœur de la recherche moderne en vision par ordinateur, peu d'attention a été accordée à la perception et au contrôle du passage du temps. Dans cet article, nous étudions le temps en tant que concept visuel apprenable et développons des modèles permettant de raisonner sur le flux temporel des vidéos et de le manipuler.Dans un premier temps, nous exploitons les indices multimodaux et la structure temporelle naturellement présents dans les vidéos afin d'apprendre, par un mode d'apprentissage auto-supervisé (self-supervised learning), à détecter les changements de vitesse et à estimer la vitesse de lecture. Nous démontrons ensuite que ces modèles de raisonnement temporel appris nous permettent de constituer, à partir de sources brutes et non structurées (in-the-wild), le plus grand ensemble de données de vidéos au ralenti (slow-motion) à ce jour. De telles séquences au ralenti, généralement filmées par des caméras à haute vitesse, contiennent des détails temporels nettement plus riches que les vidéos standard.En utilisant ces données, nous développons ensuite des modèles capables de contrôle temporel, notamment la génération de vidéos conditionnée par la vitesse, qui produit un mouvement à une vitesse de lecture spécifiée, ainsi que la super-résolution temporelle, qui transforme des vidéos floues à faible nombre d'images par seconde (low-FPS) en séquences à haut débit d'images (high-FPS) dotées de détails temporels précis. Nos conclusions mettent en évidence le fait que le temps constitue une dimension perceptive et manipulable dans l'apprentissage vidéo, ouvrant ainsi la voie à la génération de vidéos temporellement contrôlables, à la détection forensique temporelle et, potentiellement, à des modèles de monde (world-models) plus riches capables de comprendre le déroulement des événements au fil du temps.
One-sentence Summary
By treating time as a learnable visual concept, the researchers propose a self-supervised framework to detect playback speed and curate large-scale slow-motion datasets, which enables advanced temporal control through speed-conditioned video generation and temporal super-resolution for enhancing low-frame-rate sequences.
Key Contributions
- The paper introduces a self-supervised method for detecting temporal speed changes and estimating playback speed by leveraging the natural coupling between visual motion and audio pitch shifts. This approach enables the training of a visual speed-change detector that operates solely on video input during inference.
- This work presents the SloMo-44K dataset, which is the largest slow-motion video dataset to date, curated from noisy in-the-wild sources using the learned temporal reasoning models. This dataset provides the rich temporal detail necessary for training models to understand and control the flow of time.
- The research develops models for fine-grained temporal control, including speed-conditioned video generation that produces motion at specific playback speeds and temporal super-resolution that transforms low-FPS videos into high-FPS sequences. These models achieve state-of-the-art performance across both video understanding and generation tasks.
Introduction
Understanding the flow of time is essential for creating realistic video models and conducting temporal forensics. While modern computer vision models excel at spatial understanding, they often lack temporal reasoning because they are trained primarily on videos with standard, fixed frame rates. This limitation causes existing vision-language and generative models to struggle with predicting playback speeds or generating content at specific temporal cadences. The authors address these challenges by treating time as a learnable visual concept. They leverage multimodal cues and self-supervised learning to develop models capable of detecting speed changes and estimating playback speed. This approach allowed them to curate the largest slow-motion video dataset to date, which they used to enable advanced temporal control, including speed-conditioned video generation and high-fidelity temporal super-resolution.
Dataset

The authors introduce SloMo-44K, a large-scale dataset designed for slow-motion video understanding and generation. The dataset details are as follows:
- Composition and Sources: The dataset consists of 44,632 slow-motion video clips totaling 18 million frames. The raw video material is sourced from YouTube, Vimeo, and Flickr using queries related to high frame rates and slow motion.
- Data Filtering and Quality Control: The authors implement a multi-stage pipeline to ensure high quality. They use TransNetv2 for shot segmentation and an OCR model to remove clips with excessive text. To maintain content integrity, Qwen2.5-VL is used to filter out CGI and screen recordings, while video quality assessment (VQA) metrics are applied to discard low-quality samples.
- Slow-Motion Identification: To prevent the dataset from being dominated by standard speed content, the authors use a two-stage filtering process. This combines a VideoLLM (Gemini) to localize slow-motion segments with a fine-tuned ViT-based classifier (VideoMAEv2) trained on human-annotated clips. A clip is only retained if it meets strict thresholds from both models.
- Processing and Annotation:
- Temporal Segmentation: A speed change detector segments videos into clips with homogeneous playback speeds.
- Speed Annotation: The authors use a speed estimator to provide pseudo-speed annotations for each clip.
- Metadata Construction: Dense captions are generated using InternVL3. These include short and long descriptions along with specific attributes such as background, style, shot type, lighting, and atmosphere to capture both semantic and aesthetic details.
Method
The authors leverage a self-supervised framework to train a playback speed estimator that learns to predict temporal speed variations within videos without requiring ground-truth speed annotations. The core idea is to enforce equivariance under temporal resampling: if a video is accelerated by a factor k, the predicted speed should scale by the same factor. This principle is formalized through a loss function that compares the logarithm of the predicted speed of the original clip V with the logarithm of the predicted speed of the accelerated clip Vk, scaled by k. The training objective is defined as:
L=[logfθ(Vk)−log(k⋅fθ(V))]2.This self-supervised signal is applied during training, where clips are subsampled by a random factor k∼N(1,2T). For videos with known frame rates, the model also incorporates a supervised regression objective to directly predict the playback speed. The framework is designed to detect speed changes and estimate absolute speed, as illustrated in the figure below.

For speed-conditioned video generation, the model builds upon the Wan2.1-I2V architecture and introduces explicit speed control mechanisms. Given an image, a text prompt, and a target playback speed, the model generates videos with dynamic content that reflects the specified temporal rate. To achieve this, the target speed is first discretized into logarithmically spaced buckets, ranging from 0.01× to 1.0×, and encoded using sinusoidal positional embeddings. This bucket ID is then passed through a multilayer perceptron and added to the timestep embedding, which modulates the denoising schedule to align with the desired temporal speed. The discretization process is defined as:
Butcket_ID=⌊log(1)−log(0.01)log(speed)−log(0.01)⋅Nbuckets⌋,where Nbuckets=10 is empirically set. To further enhance speed control, the model applies frame-wise conditioning by modulating the latent features using an MLP that takes a positional embedding of the product of the timestep and the target speed. This conditioning is applied as:
latent[i]←latent[i]+MLPψ(ϕ(i⋅speed)),where latent[i] denotes the latent feature at temporal index i. This mechanism allows the model to generate videos with varying motion dynamics, as demonstrated in the figure below.

Experiment
The researchers evaluate their approach through a series of experiments designed to validate temporal speed perception and manipulation. They first benchmark a speed-change detector and a playback-speed estimator, demonstrating that their self-supervised methods achieve high accuracy and closely approximate human perception. Using the newly curated SloMo-44K dataset, the study further validates models for speed-conditioned video generation and temporal super-resolution, showing that these models can synthesize lifelike motion at controllable speeds and reconstruct sharp, high-frame-rate sequences even from motion-blurred inputs. Overall, the findings suggest that leveraging high-frame-rate data and cross-modal cues enables superior modeling of real-world physical dynamics compared to existing methods.
The authors introduce a large-scale slow-motion dataset that spans diverse activities and temporal scales, which they use to train models for understanding and manipulating video speed. The dataset is significantly larger than existing collections, enabling improved performance in tasks such as speed estimation, video generation, and temporal super-resolution. Results show that models trained on this dataset achieve near-human accuracy in speed perception and produce high-quality, controllable slow-motion videos. The proposed dataset is substantially larger than existing slow-motion datasets in terms of clips, videos, and frames, enabling more robust training for temporal modeling. Models trained on the dataset achieve near-human performance in playback speed estimation and outperform baselines in speed-controlled video generation and temporal super-resolution. The dataset supports both understanding and generation tasks, with strong results in video forensics and high-fidelity synthesis of real-world dynamics across a wide range of speeds.
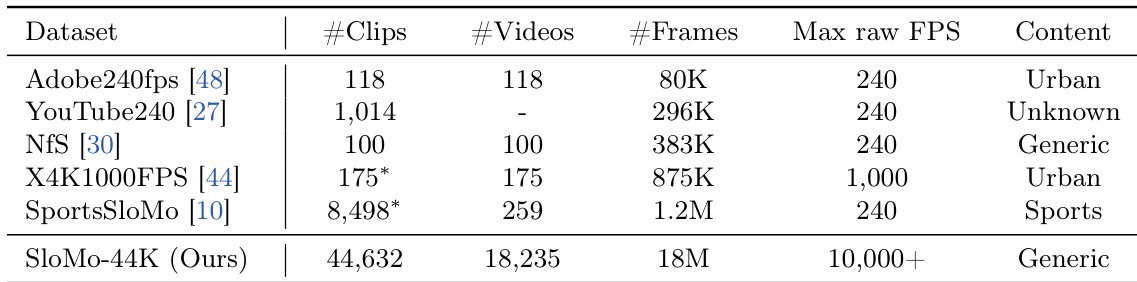
The authors present a method for video understanding and generation that leverages self-supervised signals to infer playback speed and manipulate temporal dynamics. Their approach is evaluated on tasks such as speed estimation and temporal super-resolution, with results demonstrating improved performance over baselines in both quantitative and perceptual metrics. The model achieves strong alignment with human perception, particularly in generating realistic slow-motion videos and enhancing low-frame-rate footage. The proposed method achieves higher perceptual quality and motion smoothness compared to the baseline in video generation tasks. Results show that the model generates videos with more accurate speed controllability and temporal consistency. The model outperforms baselines in both image quality and flicker reduction, indicating superior temporal coherence.

The authors evaluate their method for temporal super-resolution against several baselines, focusing on both clean and motion-blurred inputs. Results show that their approach achieves superior performance across multiple metrics, particularly in handling motion blur and producing high-quality, temporally consistent outputs. The method consistently outperforms existing models, demonstrating its effectiveness in reconstructing fine-grained motion details under challenging conditions. The proposed method significantly outperforms existing baselines in temporal super-resolution, especially under motion blur. It achieves the best results across multiple evaluation metrics, including FID and FVD, indicating high-quality reconstruction. The approach demonstrates robustness in generating sharp, coherent frames even from heavily blurred inputs.
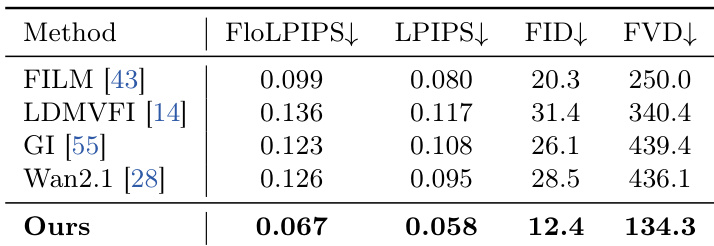
The authors evaluate a model for playback speed prediction against several baselines, including human experts and existing methods. Results show that the proposed method achieves performance close to human experts, significantly outperforming other models in correlation and accuracy metrics, while demonstrating robustness in estimating speed across diverse video conditions. The proposed method achieves performance close to human experts in playback speed prediction, outperforming existing models in correlation and error metrics. The model significantly improves upon baselines like VideoLLM and SpeedNet, narrowing the gap between machine and human performance. The method demonstrates strong robustness and accuracy in estimating video speed, particularly in challenging scenarios with motion blur and extreme temporal scales.
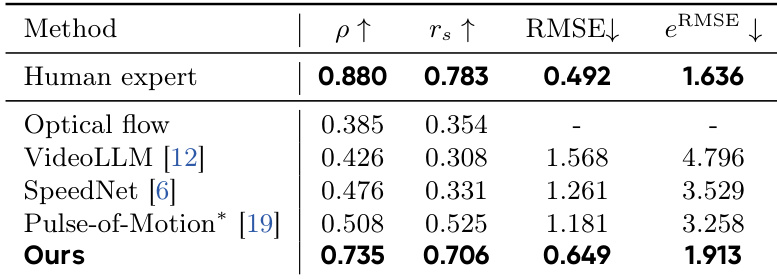
The authors evaluate the impact of training data on playback speed prediction, comparing models trained on standard videos versus those trained on their large-scale slow-motion dataset, SloMo-44K. Results show that models trained on SloMo-44K achieve significantly better performance across all metrics, including correlation coefficients and error measures, indicating superior speed estimation accuracy. Models trained on SloMo-44K outperform those trained on standard videos across all speed prediction metrics. Training on SloMo-44K leads to higher correlation with ground truth and lower prediction error. The improvement is consistent across both linear and rank-based correlation measures.
The authors evaluate their method using a large-scale slow-motion dataset across tasks including speed estimation, video generation, and temporal super-resolution. The experiments demonstrate that the proposed approach achieves near-human accuracy in speed perception and produces high-quality, temporally consistent videos with superior motion smoothness. Furthermore, the model proves highly robust in reconstructing fine-grained details from motion-blurred inputs and benefits significantly from the diverse temporal scales provided by the new dataset.