Command Palette
Search for a command to run...
WorldMark : une suite de référence unifiée pour les modèles de monde vidéo interactifs
WorldMark : une suite de référence unifiée pour les modèles de monde vidéo interactifs
Xiaojie Xu Zhengyuan Lin Kang He Yukang Feng Xiaofeng Mao Yuanyang Yin Kaipeng Zhang Yongtao Ge
Résumé
Les modèles de génération de vidéo interactive, tels que Genie, YUME, HY-World et Matrix-Game, progressent rapidement ; cependant, chaque modèle est évalué sur son propre benchmark utilisant des scènes et des trajectoires privées, ce qui rend toute comparaison équitable entre les modèles impossible. Les benchmarks publics existants proposent des métriques utiles, telles que l'erreur de trajectoire, les scores esthétiques et les jugements basés sur les VLM (modèles de langage visuel), mais aucun ne fournit les conditions de test standardisées — scènes identiques, séquences d'actions identiques et interface de contrôle unifiée — nécessaires pour rendre ces métriques comparables entre des modèles ayant des entrées hétérogènes.Nous présentons WorldMark, le premier benchmark qui offre un terrain d'entente commun pour les modèles de monde (world models) interactifs de type « Image-to-Video ». WorldMark apporte les contributions suivantes :(1) une couche unifiée de mappage d'actions qui traduit un vocabulaire d'actions partagé de type WASD dans le format de contrôle natif de chaque modèle, permettant ainsi une comparaison directe (« apples-to-apples ») entre six modèles majeurs sur des scènes et des trajectoires identiques ;(2) une suite de tests hiérarchisée comprenant 500 cas d'évaluation couvrant des points de vue à la première et à la troisième personne, des scènes photoréalistes et stylisées, ainsi que trois niveaux de difficulté (de « Easy » à « Hard ») s'étendant sur 20 à 60 secondes ;(3) un kit d'évaluation modulaire pour la qualité visuelle, l'alignement du contrôle et la cohérence du monde, conçu de manière à ce que les chercheurs puissent réutiliser nos entrées standardisées tout en intégrant leurs propres métriques à mesure que le domaine évolue.Nous publierons l'ensemble des données, le code d'évaluation et les sorties des modèles afin de faciliter les recherches futures. Au-delà des métriques hors ligne, nous lançons World Model Arena (warena.ai), une plateforme en ligne où chacun peut confronter les principaux modèles de monde dans des duels côte à côte et consulter le classement en direct.
One-sentence Summary
To enable fair cross-model comparisons for interactive video world models, the authors introduce WorldMark, a unified benchmark suite that utilizes a standardized action-mapping layer and a hierarchical test suite of 500 cases across diverse viewpoints and difficulty tiers to evaluate visual quality, control alignment, and world consistency.
Key Contributions
- The paper introduces WorldMark, a standardized benchmark for interactive Image-to-Video world models that utilizes a unified action-mapping layer to translate shared WASD-style commands into various native control formats. This mechanism enables direct comparisons between different models by testing them on identical scenes and trajectories.
- This work provides a hierarchical test suite consisting of 500 evaluation cases that span first- and third-person viewpoints, photorealistic and stylized environments, and three difficulty tiers ranging from 20 to 60 seconds.
- A modular evaluation toolkit is presented to assess Visual Quality, Control Alignment, and World Consistency through a combination of geometric trajectory metrics and VLM-based scoring. This toolkit is designed to allow researchers to integrate new metrics as the field evolves while using the benchmark's standardized inputs.
Introduction
Interactive video generation models are evolving into sophisticated world simulators that respond to user actions and camera controls. However, the field currently lacks a standardized way to compare these models because each developer uses private scenes, bespoke trajectories, and heterogeneous control interfaces. While existing benchmarks provide useful metrics for visual quality or physical consistency, they fail to offer the identical test conditions required to make cross-model comparisons meaningful.
The authors introduce WorldMark, the first benchmark suite designed to provide a common playing field for interactive Image-to-Video world models. They leverage a unified action-mapping layer that translates a shared WASD-style vocabulary into the specific control format of any given model, such as text prompts or pose parameters. To ensure comprehensive testing, the authors contribute a hierarchical suite of 500 evaluation cases spanning various viewpoints and difficulty tiers, alongside a modular toolkit for assessing visual quality, control alignment, and world consistency.
Dataset
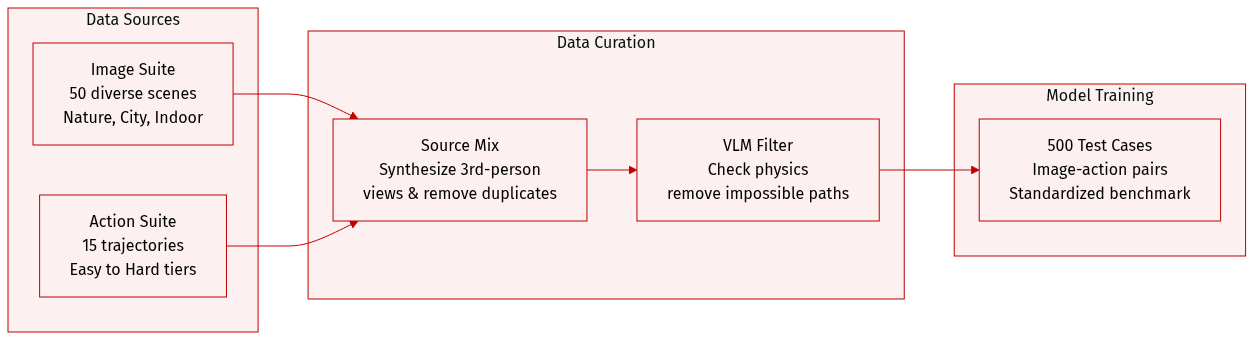
The authors introduce WorldMark, a standardized benchmarking toolkit for interactive image-to-video (I2V) world models. The dataset is structured as follows:
-
Dataset Composition and Sources
- The authors curate the Image Suite from the WorldScore dataset, which aggregates images from various existing sources.
- The Action Suite consists of 15 standardized action trajectories ranging from simple translations to complex cyclic motions.
- By combining the images and actions, the authors create a test suite of approximately 500 standardized evaluation cases.
-
Subset Details and Filtering
- Image Suite: This subset contains 100 images. The authors start with 50 reference images from WorldScore, removing duplicates and near-duplicates to maximize diversity. To enable viewpoint evaluation, they use an image generation model to synthesize a third-person view for every original first-person image. The suite covers three scene categories (Nature, City, Indoor), two visual styles (Real, Stylized), and two viewpoints (first-person and third-person).
- Action Suite: This subset includes 15 trajectories categorized into three difficulty tiers: Easy (20s single-segment), Medium (40s two-segment), and Hard (60s three-segment).
- Action Filtering: To ensure physical plausibility, the authors use a Vision Language Model (VLM) to analyze each scene. The VLM identifies physical constraints, such as obstacles, and filters out trajectories that would be impossible within that specific environment.
-
Processing and Metadata Construction
- Unified Action Interface: To allow for "apples-to-apples" comparison across different models, the authors map a shared WASD + L/R rotation vocabulary to each model's specific native control format using per-model adapters.
- Evaluation Framework: The data is integrated into a modular four-stage pipeline that evaluates models across three dimensions: Visual Quality, Control Alignment, and World Consistency.
Method
The authors leverage a modular framework designed to enable consistent evaluation of interactive world models across diverse systems, addressing the challenge of heterogeneous action interfaces. At the core of this approach is a unified action interface that standardizes input commands, allowing disparate models to operate on a common set of instructions. The framework defines a shared action vocabulary consisting of six discrete primitives: forward (W), backward (S), strafe-left (A), strafe-right (D), yaw-left (L), and yaw-right (R), each parameterized by duration. All 15 trajectories in the Action Suite are constructed from this vocabulary, ensuring semantic consistency across evaluations.
Refer to the framework diagram: this shared vocabulary is translated into each model’s native control format through action-mapping adapters. For example, YUME interprets WASD instructions embedded in natural-language captions, HY-World processes structured 6-DoF pose parameters, Genie 3 accepts gamepad-style controls, Matrix-Game exposes custom action functions, and Open-Oasis operates on 25-dimensional continuous action vectors. The adapters calibrate per-model parameters such as step size and yaw rate to preserve the intended semantic behavior, enabling faithful execution of the same action across different architectures. This design ensures that all models receive semantically identical instructions while respecting their architectural constraints. Adding support for a new model requires implementing only a single adapter, minimizing integration overhead.
The evaluation workflow integrates this unified interface with other components: Image Selection, Action Mapping, Video Generation, and Metric Evaluation. Given a target model, users first select images based on viewpoint, scene category, or visual style, or provide custom references for which a VLM script infers suitable action sequences. The selected images and actions are then passed through Action Mapping, where per-model adapters translate the shared WASD+L/R vocabulary into the target model’s native format. With the (text, image, action) triplet constructed, Video Generation runs the model under standardized conditions. Finally, Metric Evaluation scores outputs using the eight-metric suite, with the modular design allowing users to plug in custom or third-party metrics without modifying other stages.
The framework’s design is illustrated through a series of visualizations. The first panel shows diverse scenes, styles, and viewpoints, including photorealistic first- and third-person views and stylized variants, demonstrating the range of environments the system can handle. The second panel depicts the unified action mapping process, where the shared vocabulary is translated into the respective control formats of different models, highlighting the adaptability of the approach. The third panel presents a comparative analysis of outputs from multiple models—Genie 3, YUME, HY-World, MatrixGame, and HY-Game—given the same reference image and actions, showcasing the variability in quality and behavior despite identical input. This variability underscores the importance of a standardized evaluation framework. The final visualization illustrates a VLM reasoning process: given an image of a subway station, the model identifies physical barriers and infers safe passage paths, generating output action sequences such as "Forward," "Backward," and "Walk+Pan." This demonstrates the system’s ability to reason about environmental constraints and select appropriate actions, with the resulting trajectories visualized in terms of movement and yaw over time.
Experiment
The WorldMark evaluation suite benchmarks interactive video generation models across three dimensions: visual quality, control alignment, and world consistency. By testing various open-source and proprietary models in both first-person and third-person perspectives, the experiments reveal that high frame-level aesthetics do not necessarily guarantee temporal or geometric coherence. While some models excel at precise command following or visual appeal, proprietary models like Genie 3 demonstrate a superior ability to maintain stable 3D environments and stylistic uniformity over time.
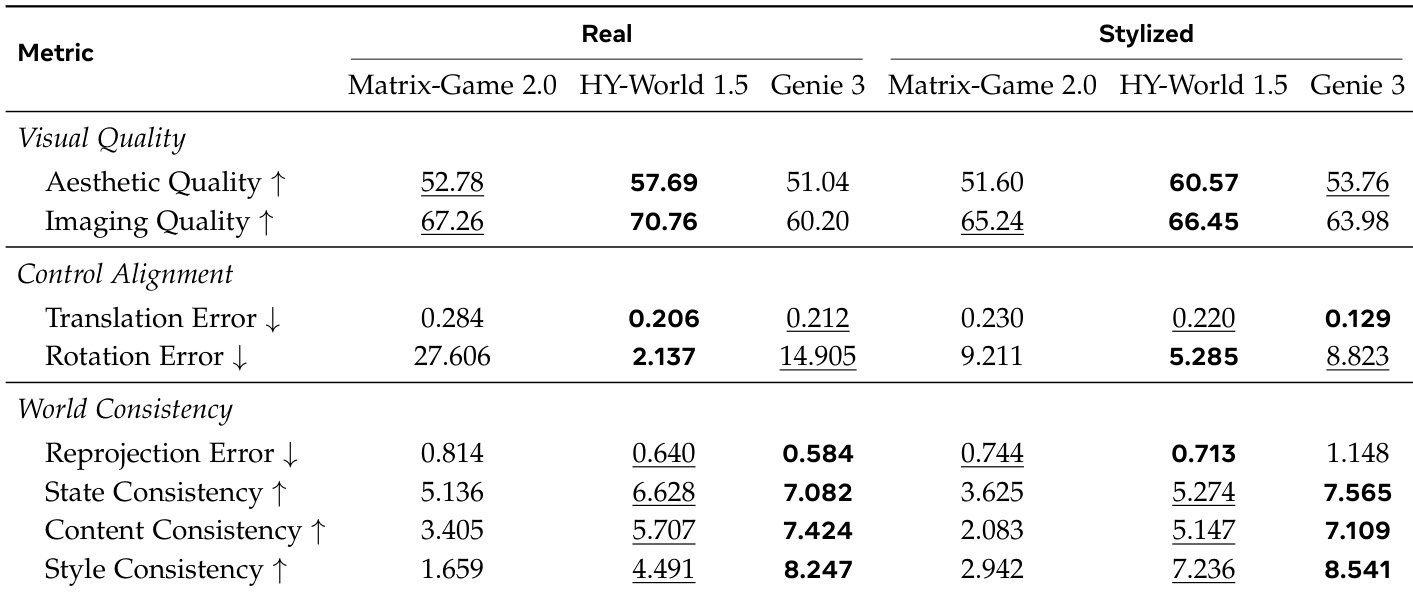
The authors evaluate several interactive video generation models across multiple dimensions, including visual quality, control alignment, and world consistency, using a comprehensive suite of metrics. Results show that different models excel in different areas, with some achieving high visual fidelity while others maintain better temporal coherence and control accuracy, and that performance varies significantly between first- and third-person perspectives. Genie 3 consistently achieves the best or near-best results in world consistency metrics across both real and stylized scenarios. HY-World 1.5 performs strongly in visual quality and control alignment, particularly in first-person evaluations. Matrix-Game 2.0 shows high translation error and significant rotation error, indicating challenges in maintaining control fidelity, especially in third-person settings.
The authors evaluate video generation models across three dimensions: Visual Quality, Control Alignment, and World Consistency, using a suite of metrics that assess frame-level fidelity, geometric control, and temporal coherence. Results show that different models excel in distinct areas, with some achieving high visual appeal but poor world coherence, while others maintain strong spatial and temporal consistency despite lower frame-level quality. Models exhibit trade-offs between visual quality and world consistency, with some producing high-fidelity frames but lacking temporal coherence. Control alignment performance varies significantly, with certain models showing strong geometric fidelity while others struggle with rotational consistency. Proprietary models consistently outperform open-source baselines in maintaining world consistency across both first-person and third-person evaluations.

The authors introduce WorldMark, a benchmark designed to evaluate interactive image-to-video generation models across multiple dimensions, including visual quality, control alignment, and world consistency. The benchmark supports interactive I2V tasks and cross-model evaluation, offering a comprehensive assessment that captures both frame-level fidelity and temporal coherence, with a focus on interactive and cross-model scenarios. WorldMark evaluates interactive I2V tasks with support for cross-model and interactive evaluation The benchmark assesses multiple dimensions including visual quality, control alignment, and world consistency WorldMark enables unified evaluation across different models and interaction types, unlike prior benchmarks
The authors evaluate multiple video generation models across three dimensions: Visual Quality, Control Alignment, and World Consistency. Results show that different models excel in different aspects, with some achieving high visual fidelity but poor control or consistency, while others maintain strong world coherence but lower frame-level quality. Genie 3 consistently performs well in World Consistency metrics across scenarios, and HY-World 1.5 leads in Visual Quality for both first- and third-person views. Genie 3 achieves the best performance in World Consistency metrics across all scenarios, demonstrating strong temporal and spatial coherence. HY-World 1.5 outperforms other models in Visual Quality, particularly in aesthetic and imaging quality. Control Alignment varies significantly among models, with some showing low translation errors but high rotation errors, indicating differing strengths in geometric fidelity.
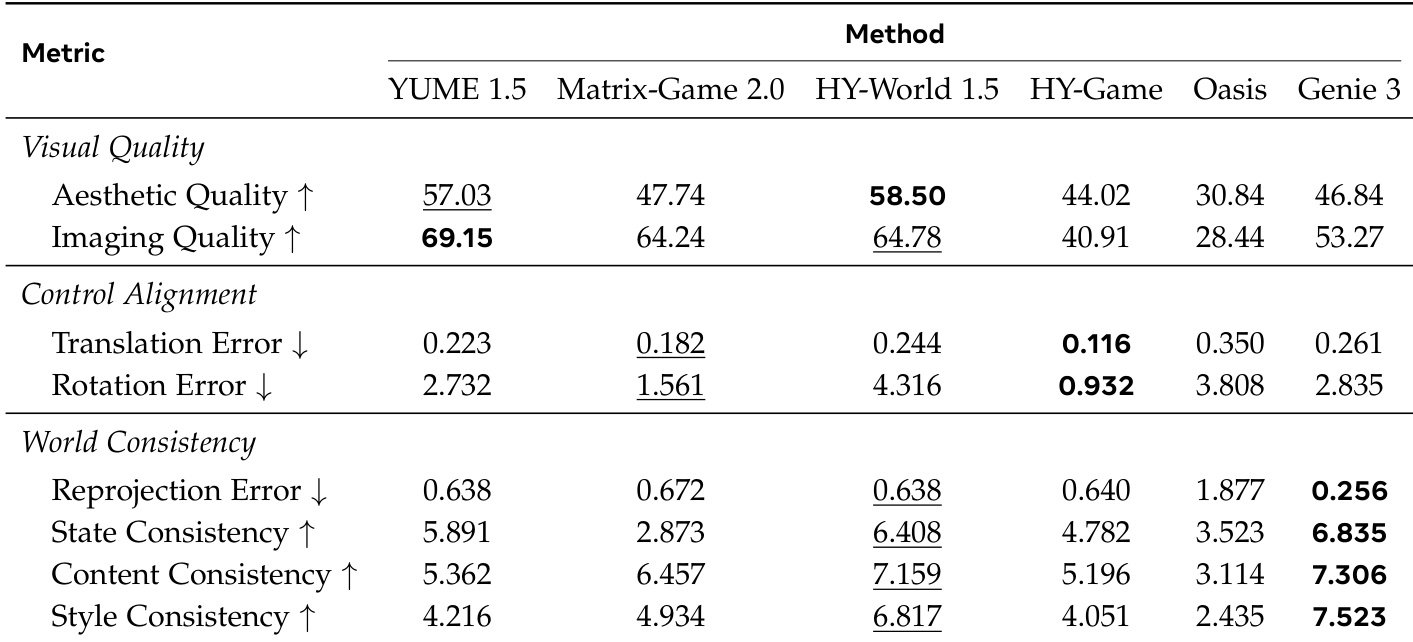
The authors evaluate multiple interactive video generation models across visual quality, control alignment, and world consistency dimensions. Results show that different models excel in specific areas, with some achieving high aesthetic quality but poor temporal coherence, while others maintain consistent worlds despite lower frame-level fidelity. YUME 1.5 achieves the highest scores in visual quality metrics, particularly in aesthetic and imaging quality. HY-Game demonstrates the best control alignment with the lowest translation and rotation errors. Genie 3 leads in world consistency across all metrics, indicating superior temporal coherence and stability.
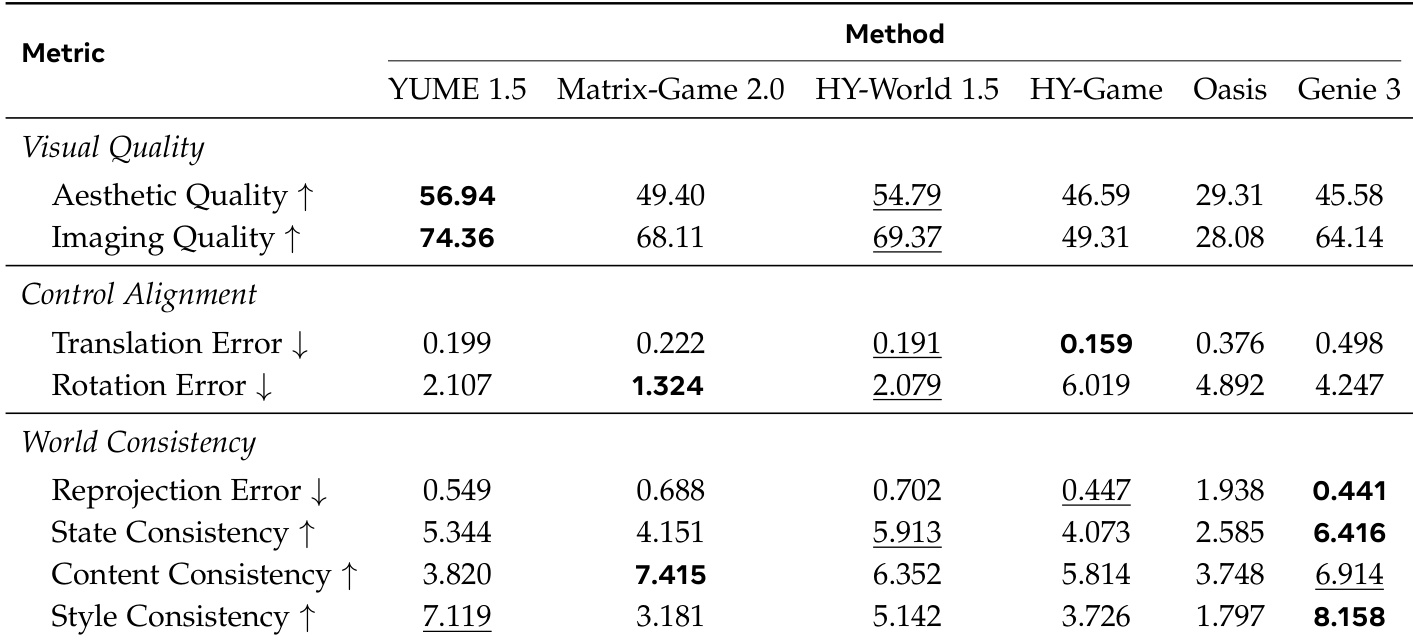
The authors utilize the WorldMark benchmark to evaluate interactive video generation models across the dimensions of visual quality, control alignment, and world consistency. The experiments reveal inherent trade-offs between models, as some prioritize high aesthetic fidelity while others excel in temporal coherence and geometric stability. Overall, different models demonstrate specialized strengths, with certain architectures leading in visual appeal, others in precise control adherence, and others in maintaining consistent world physics across various perspectives.