Command Palette
Search for a command to run...
DiLoCo découplé pour un pré-entraînement distribué résilient
DiLoCo découplé pour un pré-entraînement distribué résilient
Decoupled DiLoCo Team
Résumé
Voici la traduction de votre texte en français, réalisée selon les standards de la communication scientifique et technique :Le pré-entraînement des modèles de langage à grande échelle (LLM) modernes repose largement sur le paradigme SPMD (single program multiple data), lequel nécessite un couplage étroit entre les accélérateurs. En raison de ce couplage, des ralentissements transitoires, des défaillances matérielles et des surcharges de synchronisation interrompent l'ensemble du calcul, entraînant un gaspillage important de ressources de calcul à grande échelle. Bien que des méthodes distribuées récentes, telles que DiLoCo, aient permis de réduire la bande passante de communication, elles restent fondamentalement synchrones et vulnérables à ces blocages système. Pour remédier à ce problème, nous introduisons Decoupled DiLoCo, une évolution du framework DiLoCo conçue pour briser la barrière de la synchronisation par pas de tir (lock-step synchronization) et dépasser le modèle SPMD afin de maximiser le goodput de l'entraînement. Decoupled DiLoCo partitionne le calcul entre plusieurs « learners » (apprenants) indépendants qui exécutent des étapes d'optimisation locales. Ces learners communiquent de manière asynchrone des fragments de paramètres à un synchroniseur central, lequel contourne les learners défaillants ou lents (stragglers) en agrégeant les mises à jour via un quorum minimal, une fenêtre de grâce adaptative (adaptive grace window) et une fusion dynamique pondérée par les tokens. Inspirés par l'« ingénierie du chaos » (chaos engineering), nous atteignons une efficacité d'entraînement considérablement accrue dans des environnements sujets aux pannes — testée sur des millions de puces simulées avec un temps d'arrêt global strictement nul — tout en maintenant des performances de modèle compétitives sur des tâches de texte et de vision, tant pour les architectures denses que pour les architectures Mixture-of-Experts (MoE).
One-sentence Summary
Inspired by chaos engineering, Decoupled DiLoCo is an evolution of the DiLoCo framework that partitions compute across independent learners asynchronously communicating parameter fragments to a central synchronizer employing a minimum quorum, an adaptive grace window, and dynamic token-weighted merging to circumvent hardware failures, maximizing training goodput and achieving strictly zero global downtime across millions of simulated chips while maintaining competitive performance on text and vision tasks for both dense and mixture-of-expert architectures.
Key Contributions
- Decoupled DiLoCo is introduced as an evolution of the DiLoCo framework designed to break the lock-step synchronization barrier of the single program multiple data (SPMD) paradigm. The system partitions compute across multiple independent learners that execute local inner optimization steps to maximize training goodput.
- Independent learners asynchronously communicate parameter fragments to a central synchronizer which aggregates updates using a minimum quorum, an adaptive grace window, and dynamic token-weighted merging. This approach circumvents failed or straggling learners to ensure resilience in failure-prone environments.
- Experiments with millions of simulated chips demonstrate significantly improved training efficiency with strictly zero global downtime. Model performance remains competitive on benchmarks including MMLU-Pro and GSM8K for both dense and mixture-of-expert architectures.
Introduction
Modern pre-training of large scale language models relies on the Single Program Multiple Data paradigm, which enforces tight coupling across accelerators and creates reliability bottlenecks where a single hardware failure stalls the entire system. While recent methods like DiLoCo reduced communication bandwidth, they remained fundamentally synchronous and vulnerable to these system stalls. To address this, the authors introduce Decoupled DiLoCo, a framework that breaks the synchronization barrier by partitioning compute across independent learners. These learners execute local optimization steps and asynchronously communicate parameter fragments to a central synchronizer that aggregates updates using a minimum quorum and merging weighted by tokens. This approach maximizes training goodput in environments prone to failure with zero global downtime while maintaining competitive model performance.
Dataset
The authors employ a diverse suite of benchmarks to assess model performance across text and vision capabilities.
-
Dataset Composition and Sources
- The evaluation suite aggregates established public datasets from prior research, including citations from Clark et al., Zellers et al., and Yue et al.
- Data is divided into text-based reasoning benchmarks and vision-based multimodal understanding tasks.
-
Key Details for Each Subset
- Text Benchmarks:
- ARC: Grade-school science questions for question-answering.
- BoolQ: Yes/no reading comprehension questions from search queries.
- HellaSwag: Commonsense natural language inference and text continuation.
- PIQA: Physical commonsense reasoning regarding interactions.
- SIQA: Commonsense reasoning on social interactions and behavior.
- WinoGrande: Adversarial benchmark for pronoun resolution.
- Vision Benchmarks:
- ChartQA and InfographicVQA: Visual and logical reasoning on charts and infographics.
- COCO-Captions: Generating descriptive captions for everyday images.
- DocVQA: Visual question answering on document page images.
- MMMU: Expert-level multi-discipline multimodal evaluation.
- TextVQA: Reading and reasoning about text within images.
- Text Benchmarks:
-
Usage and Processing
- The authors use these datasets exclusively for evaluation to measure reasoning, commonsense, and multimodal understanding.
- Specific training splits, mixture ratios, or cropping strategies are not detailed in this section as the data serves as a test suite.
- Processing focuses on task-specific inputs such as image captions or question-answer pairs based on the benchmark definitions.
Method
The authors introduce Decoupled DiLoCo, a distributed training framework designed to evolve previous bandwidth-focused methods by decomposing monolithic SPMD clusters into independent, asynchronous learners. This architecture prioritizes availability and partition tolerance over strict consistency, allowing the system to operate efficiently at pre-training scales even in the presence of hardware failures or stragglers.
The system architecture features a central synchronizer to facilitate asynchronous parameter reconciliation. As illustrated in the system architecture diagram, the Learner workers run on accelerator hardware (TPUs) with high-bandwidth memory (HBM), executing the computationally intensive inner optimization loops. In contrast, the Syncer runs on CPU-only resources with RAM, managing the global model parameters and orchestrating the asynchronous parameter reconciliation. This separation ensures that the Syncer has a minimal failure surface and does not compete for accelerator resources with the training workload.
Refer to the framework diagram to understand the interaction between learners and the Syncer. In this setup, Learner Unit 1 continues its training loop even when Learner Unit 2 stalls. The Syncer aggregates updates from available learners and broadcasts them back, ensuring that the overall training process never stops despite individual component failures. This decoupling isolates the blast radius of hardware failures, preventing localized issues from propagating across the cluster.
To optimize communication efficiency, the model weights are partitioned into fragments. The authors evaluate several fragmentation strategies to balance model performance and system bandwidth usage. The layer fragmentation approach groups weights by transformer layers, which can lead to bursty communication patterns if the sync interval exceeds the number of layers. Tensor fragmentation partitions weights at the individual tensor level, allowing more frequent communication but potentially resulting in uneven fragment sizes. To address these issues, the authors employ balanced tensor fragmentation. This strategy uses a greedy bin-packing algorithm to distribute tensors across fragments such that their total sizes are approximately equal, ensuring consistent bandwidth usage and avoiding communication spikes.
The training process involves an inner optimization loop on the learners and an outer optimization loop on the Syncer. Learners perform standard inner optimization steps (e.g., AdamW) on their local data shards. Periodically, they send metadata and model fragments to the Syncer. The Syncer aggregates these fragments from a quorum of learners, applies an outer optimizer (e.g., SGD with Nesterov momentum), and broadcasts the updated parameters. This asynchronous reconciliation allows the system to tolerate stragglers and heterogeneous hardware speeds.
Robustness is further enhanced through distributed checkpointing and learner recovery mechanisms. Vector clocks are used to track the causal state of the system, enabling consistent distributed snapshots via the Chandy-Lamport algorithm. When a learner fails or needs to rejoin, it can recover by acquiring a recent copy of the model state from a peer learner and synchronizing with the Syncer. This process is asynchronous and does not block the rest of the system, allowing for dynamic adjustment of the number of active learners.
Refer to the comparison of stepping patterns to see how Decoupled DiLoCo differs from Elastic Data-Parallel training. While Elastic Data-Parallel training halts when slices are unavailable or during synchronization, Decoupled DiLoCo continues stepping even when some learners are offline or recovering. This capability allows the framework to maintain high goodput and availability even under aggressive hardware failure scenarios.
Finally, the system supports deterministic replay for debugging and analysis. By logging an event tape that captures the causal state, vector clocks, and failure events, the training trajectory can be reproduced exactly regardless of the underlying hardware conditions. This ensures that algorithmic behavior can be isolated from system noise, facilitating rigorous evaluation of the framework's resilience.
Experiment
Experiments evaluate Decoupled DiLoCo using Gemma models on text and vision data to validate resilience against hardware failures, support for heterogeneous hardware, and scalability across model sizes. The framework maintains high system goodput and uptime during simulated failure scenarios where standard data-parallel training degrades, without sacrificing downstream model quality. Results further confirm that the approach seamlessly integrates opportunistic compute resources and matches centralized baselines across both dense and Mixture-of-Experts architectures.
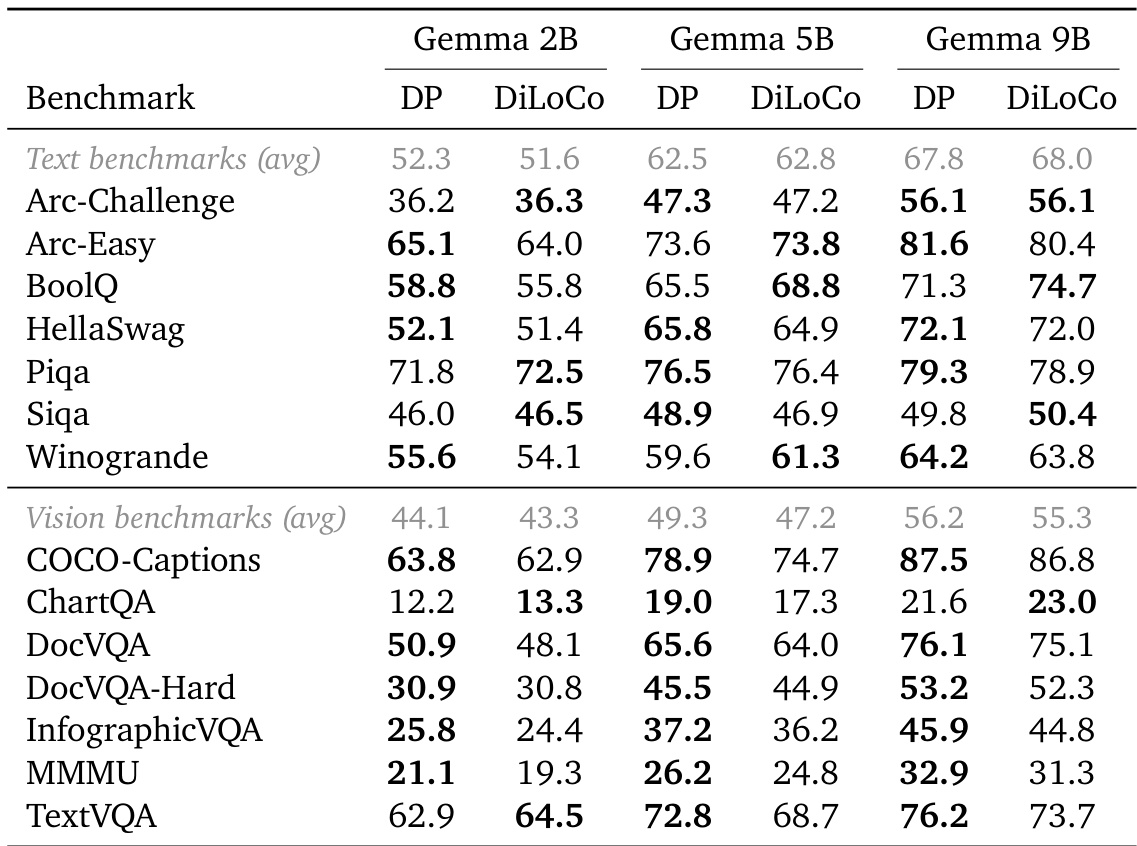
The authors compare the downstream performance of Decoupled DiLoCo against standard Data Parallel training across Gemma models of varying sizes. The results show that the decoupled framework achieves performance comparable to the centralized baseline on both text and vision benchmarks. Decoupled DiLoCo achieves text benchmark averages comparable to Data Parallel training across all model sizes. Vision benchmark results indicate consistent performance parity between the decoupled and standard training approaches. Specific task scores vary slightly between methods, but no significant performance gap is observed at larger scales.
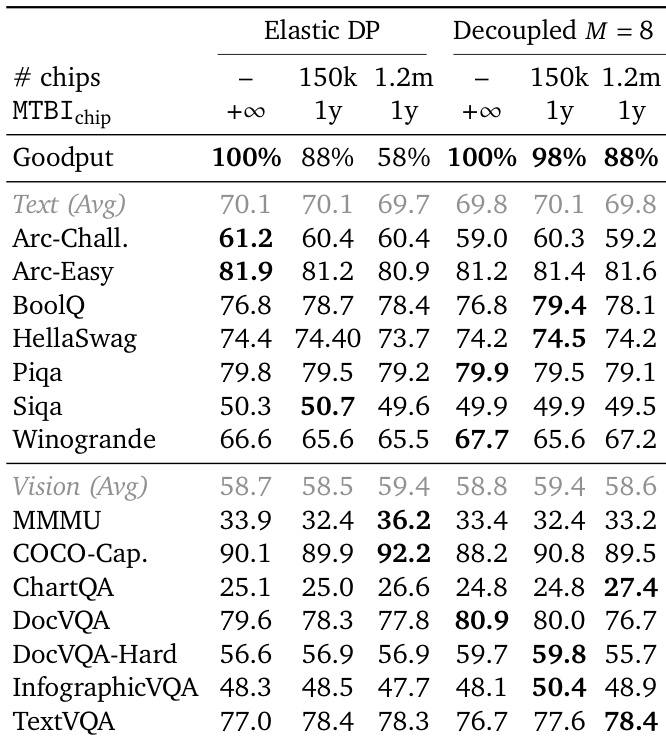
The authors apply chaos engineering principles to test the resilience of their Decoupled DiLoCo framework against simulated hardware failures, comparing it against standard Elastic Data Parallelism. The results indicate that while standard Elastic DP suffers a drastic reduction in goodput as the cluster size and failure rate increase, the Decoupled approach maintains consistently high efficiency. Furthermore, downstream model performance on text and vision benchmarks remains robust and comparable to the no-failure baseline, demonstrating that the framework preserves training quality despite significant hardware interruptions. Decoupled training sustains high goodput under heavy simulated failure rates, significantly outperforming Elastic DP which sees a sharp decline in efficiency. Downstream evaluation metrics on text and vision tasks remain stable and competitive across both methods, showing resilience to hardware interruptions. The system effectively masks hardware failures, maintaining model quality comparable to a standard training run without failures.
The authors evaluate different merging strategies, specifically comparing standard averaging against Radial-Directional Averaging (RDA) for both model parameters and embeddings. Results indicate that utilizing RDA for the model merge operation consistently yields superior performance across various text and vision benchmarks compared to standard averaging methods. The configuration using RDA for both merging and model updates achieves the highest overall averages in both text and vision categories. Applying RDA to the merge operation alone significantly improves performance on tasks like ARC-Challenge and COCO compared to the baseline averaging method. Standard averaging for both components serves as the lowest-performing baseline across most evaluated metrics.

The experiment compares the efficiency of Decoupled DiLoCo against standard Data-Parallel training across varying levels of compute availability. Results indicate that the Decoupled DiLoCo framework is significantly more efficient, exhibiting much lower values than the Data-Parallel baseline across all tested scenarios. Furthermore, applying int4 communication compression to the Decoupled DiLoCo method yields additional efficiency gains compared to its uncompressed counterpart. Decoupled DiLoCo maintains a significant efficiency advantage over Data-Parallel training across all compute utilization levels. Using int4 communication compression further reduces the metric values for Decoupled DiLoCo compared to the standard configuration. The efficiency gap between the methods persists and remains substantial as compute utilization increases.

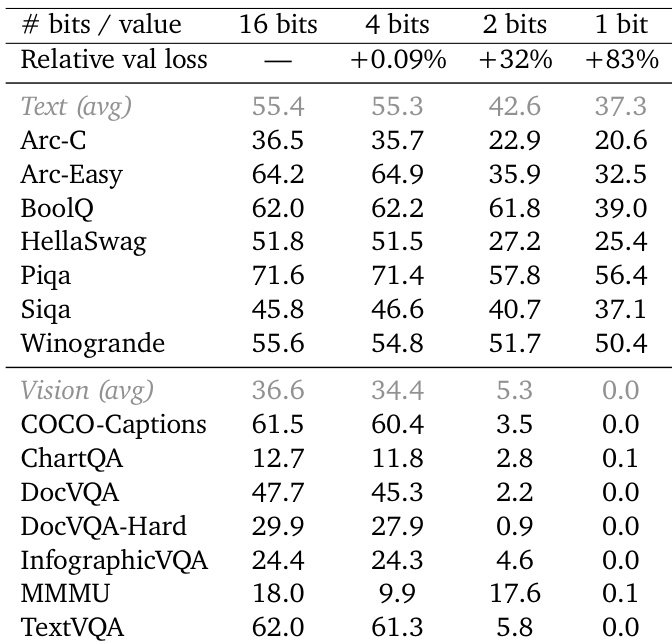
The authors evaluate the impact of compressing outer gradients to lower bit precisions to minimize bandwidth constraints during training. Results show that compressing to 4 bits maintains model performance comparable to the 16-bit baseline, whereas reducing precision to 2 or 1 bit leads to significant degradation in downstream task capabilities. 4-bit compression yields performance comparable to the 16-bit baseline with minimal validation loss increase. Text and vision benchmarks experience substantial performance drops when using 2-bit precision. 1-bit compression results in severe model degradation across all evaluated tasks.
The authors evaluate Decoupled DiLoCo against standard Data Parallel training, demonstrating comparable downstream performance on text and vision benchmarks while maintaining superior resilience against simulated hardware failures. Further analysis validates that employing Radial-Directional Averaging for merging and 4-bit gradient compression optimizes efficiency without sacrificing model quality. Collectively, these experiments confirm the framework achieves robust training performance and significant efficiency gains across varying compute conditions and precision levels.