Command Palette
Search for a command to run...
Co-Évolution de la décision des LLM et des skill bank agents pour les tâches à long horizon
Co-Évolution de la décision des LLM et des skill bank agents pour les tâches à long horizon
Xiyang Wu Zongxia Li Guangyao Shi Alexander Duffy Tyler Marques Matthew Lyle Olson Tianyi Zhou Dinesh Manocha
Résumé
Les environnements interactifs à long horizon constituent un banc d'essai pour évaluer les capacités d'utilisation des skills des agents. Ces environnements exigent un raisonnement multi-étapes, l'enchaînement de multiples skills sur de nombreux pas de temps (timesteps), ainsi qu'une prise de décision robuste face à des récompenses différées et une observabilité partielle. Les jeux représentent un excellent banc d'essai pour évaluer l'utilisation des skills par les agents dans ces environnements. Si les grands modèles de langage (LLM) offrent une alternative prometteuse en tant que game playing agents, ils éprouvent souvent des difficultés à maintenir une prise de décision cohérente sur le long terme, faute de mécanisme pour découvrir, conserver et réutiliser des skills structurées à travers les épisodes.Nous présentons COSPLAY, un cadre de co-évolution dans lequel un LLM decision agent extrait des skills d'une banque de skills (skill bank) apprenable pour guider la prise d'action, tandis qu'un pipeline de skills géré par un agent découvre des skills réutilisables à partir des rollouts non étiquetés des agents afin de constituer la skill bank. Notre cadre améliore simultanément le decision agent, en lui permettant de mieux apprendre la récupération de skills et la génération d'actions, et l'agent de la skill bank, qui extrait, affine et met à jour continuellement les skills ainsi que leurs contrats (contracts).Des expérimentations menées sur six environnements de jeu démontrent que COSPLAY, utilisant un modèle de base de 8B, atteint une amélioration moyenne de la récompense de plus de 25,1 % par rapport à quatre modèles de référence (frontier LLM baselines) sur des benchmarks de jeux solo, tout en restant compétitif dans des jeux de raisonnement social multi-joueurs.
One-sentence Summary
The proposed COS-PLAY co-evolution framework enhances long-horizon decision-making by pairing an LLM decision agent with an agent-managed skill pipeline that discovers and refines reusable skills from unlabeled rollouts, achieving over a 25.1% average reward improvement against four frontier LLM baselines across six game environments using an 8B base model.
Key Contributions
- The paper introduces COS-PLAY, a co-evolution framework that integrates an LLM-based decision agent with an agent-managed skill pipeline to enable unsupervised skill discovery and continual refinement.
- This framework utilizes a dual-agent system where a decision agent retrieves skills from a learnable bank to guide actions, while a skill bank agent extracts, segments, and updates reusable skills and their contracts from unlabeled rollouts.
- Experiments across six diverse game environments demonstrate that the 8B base model achieves over 25.1% average reward improvement against four frontier LLM baselines in single-player benchmarks while maintaining competitiveness in multi-player social reasoning tasks.
Introduction
Autonomous agents in long-horizon interactive environments must master multi-step reasoning and the ability to chain complex behaviors to succeed. While Large Language Models (LLMs) show promise in these settings, they often struggle with consistent decision-making because they lack efficient mechanisms to discover, store, and reuse structured skills across different episodes. Existing approaches typically rely on curated human demonstrations or fixed pipelines that do not allow the agent to evolve its own procedural knowledge. The authors leverage a co-evolution framework called COS-PLAY to bridge this gap. This system utilizes a dual-agent architecture where an LLM decision agent retrieves skills to guide actions while a separate skill bank agent autonomously discovers and refines reusable skills from unlabeled interaction data.
Dataset

The authors evaluate their model across six diverse game environments, categorized into puzzle solving, platform control, and multi-agent social reasoning. The dataset and evaluation setup include:
-
Environment Composition and Observations:
- 2048: A single-player sliding-tile puzzle on a 4x4 grid. The agent receives a text-rendered board including tile values, score, and directional move lookahead.
- Candy Crush: A match-3 puzzle on an 8x8 board. Observations consist of a text-based board and currently valid swap actions.
- Tetris: A tile-stacking game on a 10x20 board. The agent receives an ASCII board, current and upcoming pieces, and statistics like stack height and holes.
- Super Mario Bros.: A side-scrolling platformer. Observations are converted into natural-language descriptions of Mario's position, nearby objects, and enemies.
- Avalon: A five-player social deduction game. The state is provided as a natural-language description covering the current phase, private roles, quest progress, and discussion history.
- Diplomacy: A seven-player grand-strategy game. The agent observes natural-language states including unit locations, supply center counts, and negotiation history.
-
Action Spaces and Processing:
- The authors convert all observations into textual or natural-language state descriptions.
- Agents interact through discrete text actions. For Tetris, the authors use macro actions for valid placements rather than primitive controls. For Candy Crush, the action space is dynamic, consisting of valid coordinate-pair swaps.
-
Task Constraints and Rewards:
- Episode Limits: Most environments are capped at specific horizons, such as 200 steps for 2048, Tetris, and Super Mario Bros., 50 moves for Candy Crush, 5 quests for Avalon, and 20 phases for Diplomacy.
- Reward Structures: Rewards are tailored to each task, ranging from merge scores and game points to progress-based signals in platformers or victory-based outcomes in social deduction and strategy games.
Method
The COS-PLAY framework operates as a co-evolving system where a decision agent and a skill bank agent interact iteratively to improve long-horizon decision-making in interactive environments. The overall architecture consists of two primary components: the decision agent, which interacts with the game environment through primitive actions and skill retrieval, and the skill bank agent, which processes trajectories to discover, refine, and maintain structured skills in the skill bank. At each timestep, the decision agent observes the current environment state, retrieves relevant skill candidates from the skill bank using a retrieval mechanism, updates its internal intention state based on the retrieved skill, and executes a primitive action conditioned on the observation, intention, and active skill. This process generates a rollout trajectory that is then fed to the skill bank agent for refinement. The skill bank agent operates through a four-stage pipeline: boundary proposal, segmentation inference, contract learning, and skill bank maintenance. Boundary proposal identifies potential skill-transition points using local signals such as predicate flips, intention changes, reward spikes, and action execution patterns. These candidate boundaries are then processed by a segmentation module that labels each segment with an existing skill or a new skill based on the consistency of observed effects with learned contracts. Contract learning aggregates state changes across instances of a skill to form a verified effect contract that captures reliable state transitions, which is then used to guide segmentation and improve bank quality. The final maintenance stage applies refinement, materialization, merging, splitting, and retirement operations to update the skill bank, ensuring it remains compact, stable, and aligned with the evolving decision policy.  The two agents are trained jointly using GRPO with separate LoRA adapters, enabling the decision agent to learn skill retrieval and action execution while the skill bank agent learns to segment trajectories, verify contracts, and maintain the bank. This closed-loop co-evolution ensures that improvements in skill quality enhance decision-making, while better rollouts improve skill discovery, creating a self-reinforcing learning system.
The two agents are trained jointly using GRPO with separate LoRA adapters, enabling the decision agent to learn skill retrieval and action execution while the skill bank agent learns to segment trajectories, verify contracts, and maintain the bank. This closed-loop co-evolution ensures that improvements in skill quality enhance decision-making, while better rollouts improve skill discovery, creating a self-reinforcing learning system.
Experiment
The framework is evaluated across six diverse environments, including single-player puzzle games and complex multi-player social reasoning games like Avalon and Diplomacy. Experiments validate that the co-evolving training approach enables a small model to achieve high data efficiency and strong cross-domain adaptability, matching or exceeding the performance of much larger frontier LLMs. Qualitative analysis demonstrates that the learned skill bank provides essential temporal structure and reusable strategic patterns, which prevents catastrophic failures in long-horizon tasks and maintains general reasoning capabilities.
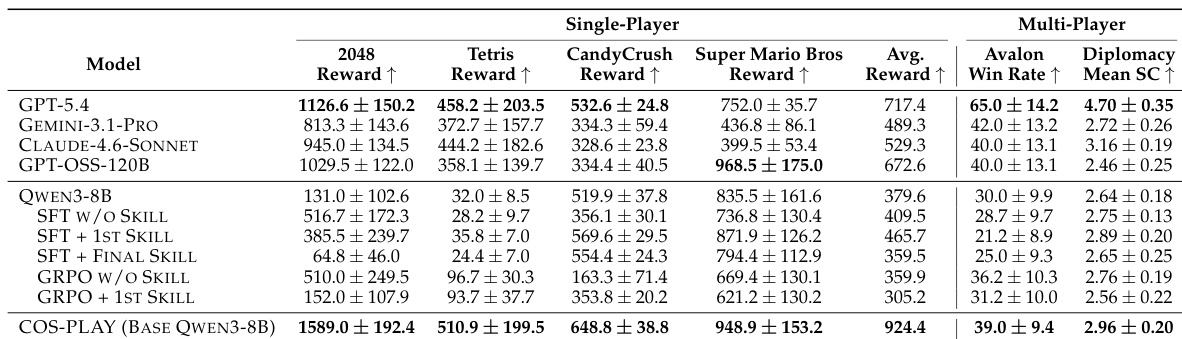
The authors compare COS-PLAY against baseline models on game environments, showing that the full COS-PLAY framework achieves higher rewards than both GPT-5.4 and a merged LoRA variant. The results indicate that the full model outperforms the base Qwen3-8B and the merged LoRA version, suggesting that the co-evolving training and specialized LoRA adapters contribute to improved performance. COS-PLAY achieves higher rewards than GPT-5.4 and the merged LoRA variant. The full COS-PLAY model outperforms the base Qwen3-8B and the merged LoRA version. The improved performance suggests the importance of the co-evolving training and specialized LoRA adapters.
The authors evaluate COS-PLAY on a range of single-player and multi-player game environments, comparing its performance against several frontier LLMs. Results show that COS-PLAY achieves substantial improvements over a baseline model on single-player games and remains competitive with state-of-the-art models on multi-player social reasoning tasks, demonstrating effective few-shot adaptation and skill reusability. The framework's performance is attributed to co-evolving a decision agent with a skill bank that learns reusable, structured abstractions, enabling robust long-horizon reasoning. COS-PLAY achieves significant average improvement over a baseline model on single-player games and matches or exceeds frontier LLMs on multi-player social reasoning tasks. The framework demonstrates effective few-shot adaptation, reaching strong performance with minimal training iterations compared to prior methods. COS-PLAY learns reusable skill abstractions that provide a safety floor and improve action diversity, enabling robust performance in long-horizon social games.
The authors evaluate COS-PLAY against a base model on general reasoning benchmarks, showing that the adapted model maintains performance close to the original while achieving strong game-playing results. Results indicate that the adaptation process preserves general reasoning ability with minimal degradation, suggesting the method does not compromise broad cognitive skills despite specialization in game environments. COS-PLAY maintains performance close to the base model on general reasoning benchmarks The adaptation process results in minimal degradation of general reasoning ability COS-PLAY preserves the base model's reasoning capabilities while improving game-specific performance

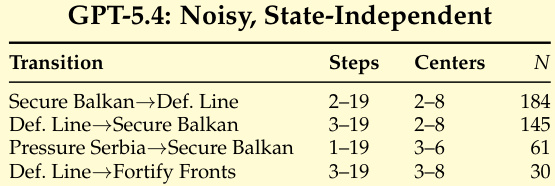
{"summary": "The authors analyze skill transitions in Diplomacy, showing how different skill categories are triggered at specific steps and center counts during gameplay. The the the table illustrates that certain transitions, such as Secure Balkan to Def. Line and Pressure Serbia to Secure Balkan, occur within defined ranges of game steps and supply centers, indicating a structured, phase-based decision process. These patterns suggest that skills are used to impose temporal structure and guide action selection, with some transitions being more frequent than others.", "highlights": ["Skill transitions in Diplomacy are triggered within specific ranges of game steps and supply centers, indicating a structured decision process.", "Certain transitions like Secure Balkan to Def. Line and Pressure Serbia to Secure Balkan occur frequently, suggesting their importance in gameplay.", "The use of skills imposes temporal structure, helping to guide action selection and prevent strategic stagnation."]
The authors analyze failure modes in Diplomacy by comparing successful and failed episodes, identifying that successful runs exhibit diverse actions and structured skill transitions, while failures are characterized by repetitive actions and lack of strategic variation. The analysis highlights that skill transitions and action diversity are critical for avoiding stagnation and enabling effective gameplay, with the framework providing a temporal structure that supports exploration and prevents collapse. Successful episodes show diverse actions and structured skill transitions, while failures are marked by high action repetition and lack of variation. The framework prevents collapse by enforcing a temporal structure that maintains a safety floor, even with poor action selection. Skill transitions impose a curriculum schedule that broadens action exploration and avoids stagnation.

The authors evaluate the COS-PLAY framework across single-player and multi-player game environments, general reasoning benchmarks, and specific gameplay analysis in Diplomacy. The results demonstrate that co-evolving decision agents with specialized skill banks enables superior game performance and robust long-horizon reasoning while preserving the base model's general cognitive abilities. Furthermore, qualitative analysis shows that the learned skill abstractions provide a necessary temporal structure that promotes action diversity and prevents strategic stagnation.